

A primer on machine learning techniques for genomic applications
- PMID: 34429852
- PMCID: PMC8365460
- DOI: 10.1016/j.csbj.2021.07.021
A primer on machine learning techniques for genomic applications
Abstract
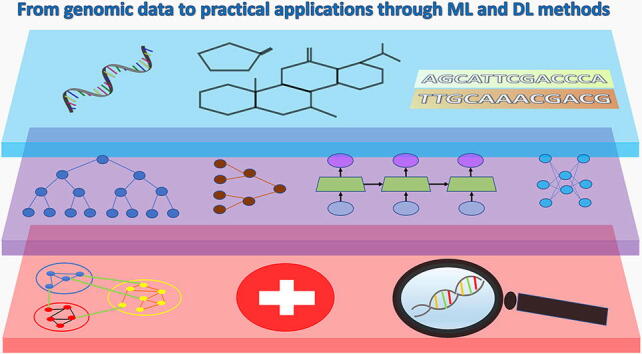
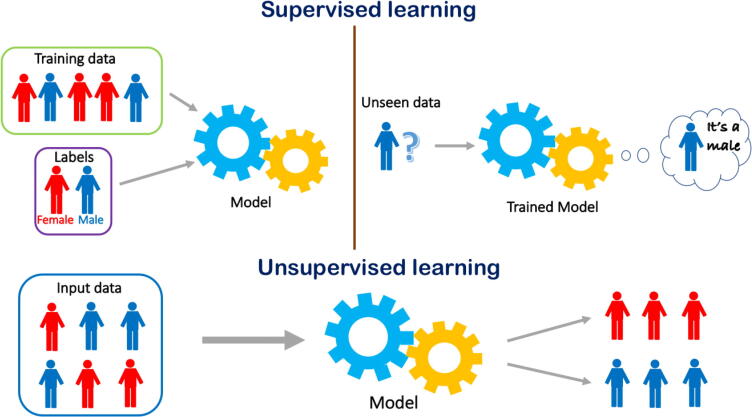
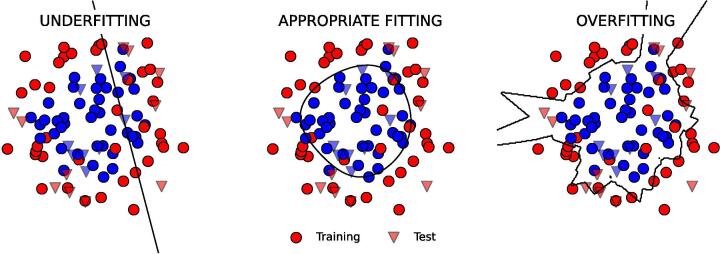
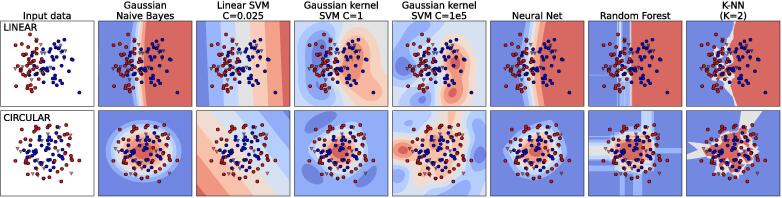
High throughput sequencing technologies have enabled the study of complex biological aspects at single nucleotide resolution, opening the big data era. The analysis of large volumes of heterogeneous "omic" data, however, requires novel and efficient computational algorithms based on the paradigm of Artificial Intelligence. In the present review, we introduce and describe the most common machine learning methodologies, and lately deep learning, applied to a variety of genomics tasks, trying to emphasize capabilities, strengths and limitations through a simple and intuitive language. We highlight the power of the machine learning approach in handling big data by means of a real life example, and underline how described methods could be relevant in all cases in which large amounts of multimodal genomic data are available.
Keywords: Deep learning; Genomics; Machine learning.
© 2021 The Authors.
Conflict of interest statement
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Figures
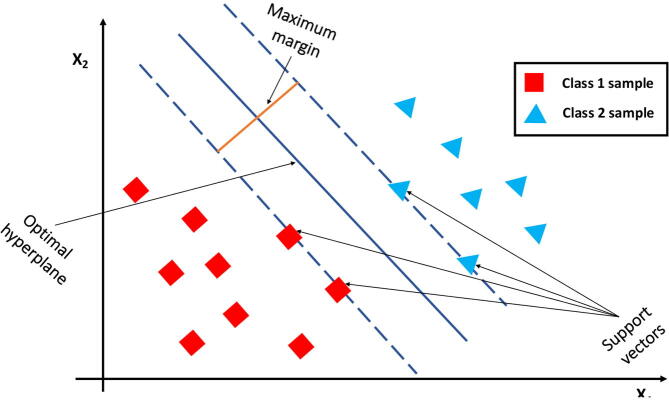
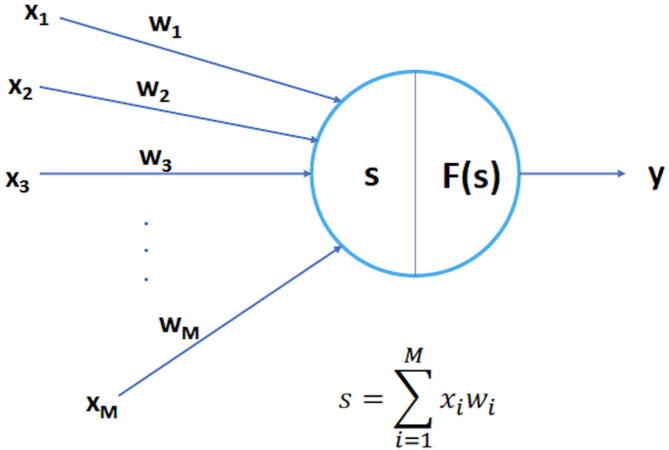
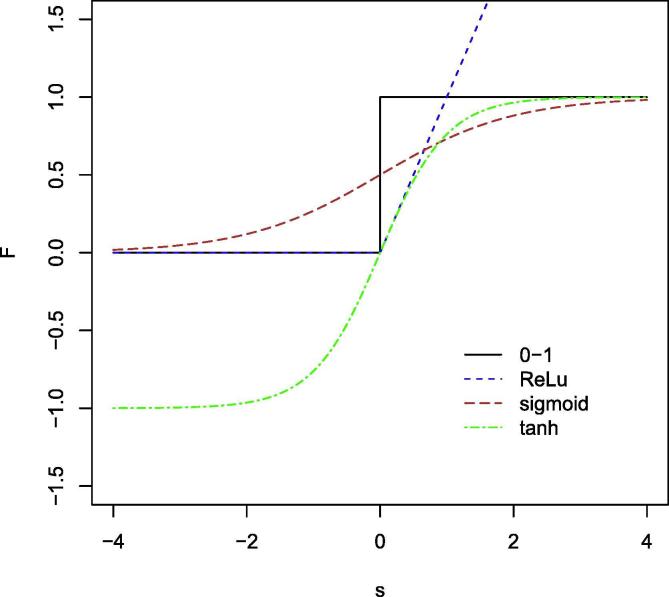
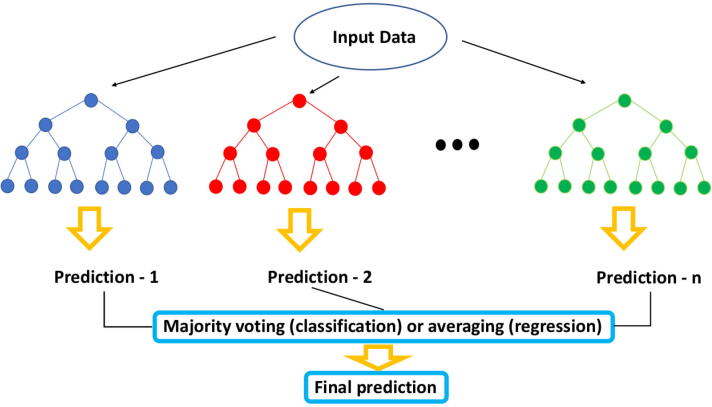
References
-
- McCarthy J. Basic questions. What is Artificial Intelligence?http://www-formal.stanford.edu/jmc/whatisai.html.
Publication types
LinkOut - more resources
Full Text Sources