

TransMed: Transformers Advance Multi-Modal Medical Image Classification
- PMID: 34441318
- PMCID: PMC8391808
- DOI: 10.3390/diagnostics11081384
TransMed: Transformers Advance Multi-Modal Medical Image Classification
Abstract
Over the past decade, convolutional neural networks (CNN) have shown very competitive performance in medical image analysis tasks, such as disease classification, tumor segmentation, and lesion detection. CNN has great advantages in extracting local features of images. However, due to the locality of convolution operation, it cannot deal with long-range relationships well. Recently, transformers have been applied to computer vision and achieved remarkable success in large-scale datasets. Compared with natural images, multi-modal medical images have explicit and important long-range dependencies, and effective multi-modal fusion strategies can greatly improve the performance of deep models. This prompts us to study transformer-based structures and apply them to multi-modal medical images. Existing transformer-based network architectures require large-scale datasets to achieve better performance. However, medical imaging datasets are relatively small, which makes it difficult to apply pure transformers to medical image analysis. Therefore, we propose TransMed for multi-modal medical image classification. TransMed combines the advantages of CNN and transformer to efficiently extract low-level features of images and establish long-range dependencies between modalities. We evaluated our model on two datasets, parotid gland tumors classification and knee injury classification. Combining our contributions, we achieve an improvement of 10.1% and 1.9% in average accuracy, respectively, outperforming other state-of-the-art CNN-based models. The results of the proposed method are promising and have tremendous potential to be applied to a large number of medical image analysis tasks. To our best knowledge, this is the first work to apply transformers to multi-modal medical image classification.
Keywords: deep learning; medical image classification; multi-modal; multiparametric MRI; transformer.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
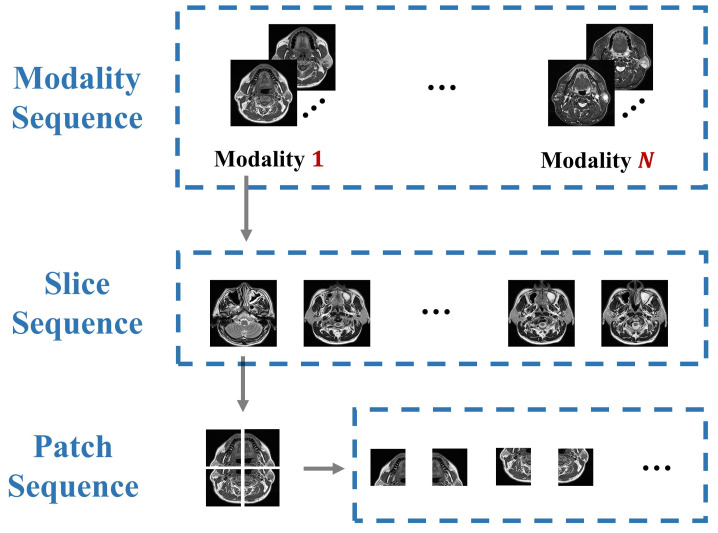
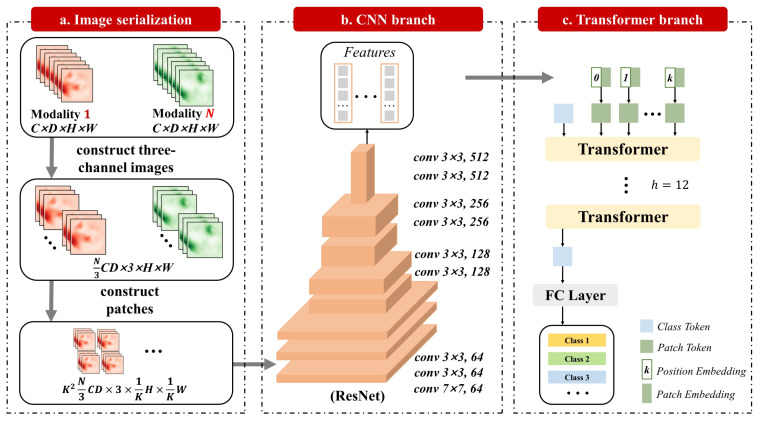
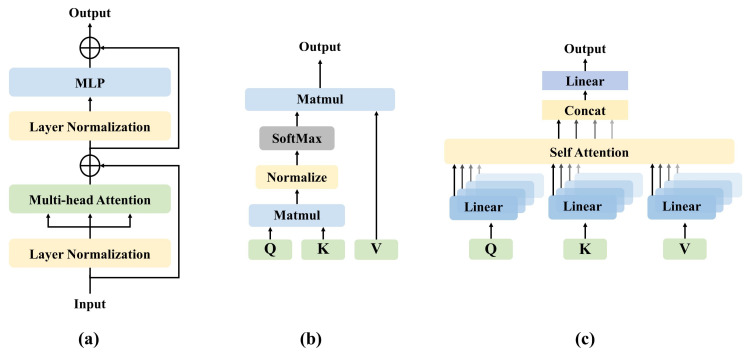
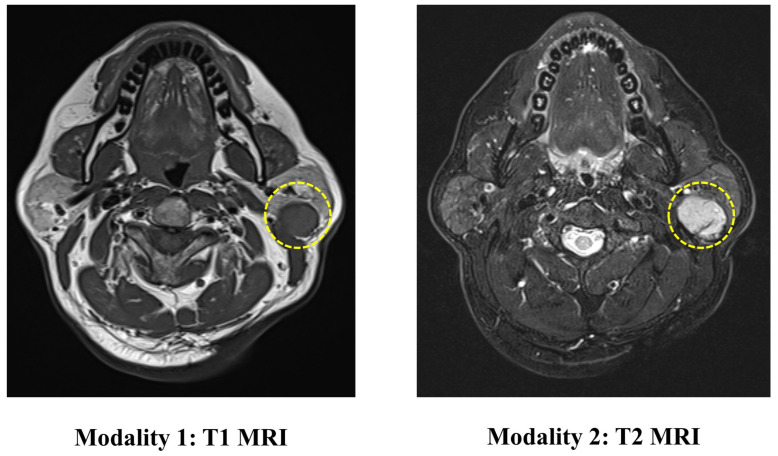
References
-
- Vaswani A., Shazeer N., Parmar N., Uszkoreit J., Jones L., Gomez A.N., Kaiser Ł., Polosukhin I. Attention is All you Need; Proceedings of the Neural Information Processing Systems (NeurIPS); Long Beach, CA, USA. 4–9 December 2017; pp. 5998–6008.
-
- Carion N., Massa F., Synnaeve G., Usunier N., Kirillov A., Zagoruyko S. End-to-end object detection with transformers; Proceedings of the European Conference on Computer Vision (ECCV); Glasgow, UK. 23–28 August 2020; pp. 213–229.
-
- Zheng S., Lu J., Zhao H., Zhu X., Luo Z., Wang Y., Fu Y., Feng J., Xiang T., Torr P.H.S., et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. arXiv. 20202012.15840
-
- Dosovitskiy A., Beyer L., Kolesnikov A., Weissenborn D., Zhai X., Unterthiner T., Dehghani M., Minderer M., Heigold G., Gelly S., et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv. 20202010.11929
-
- Touvron H., Cord M., Douze M., Massa F., Sablayrolles A., Jegou H. Training Data-Efficient Image Transformers & Distillation through Attention. arXiv. 20202012.12877
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
