

Four dimensions characterize attributions from faces using a representative set of English trait words
- PMID: 34453054
- PMCID: PMC8397784
- DOI: 10.1038/s41467-021-25500-y
Four dimensions characterize attributions from faces using a representative set of English trait words
Abstract
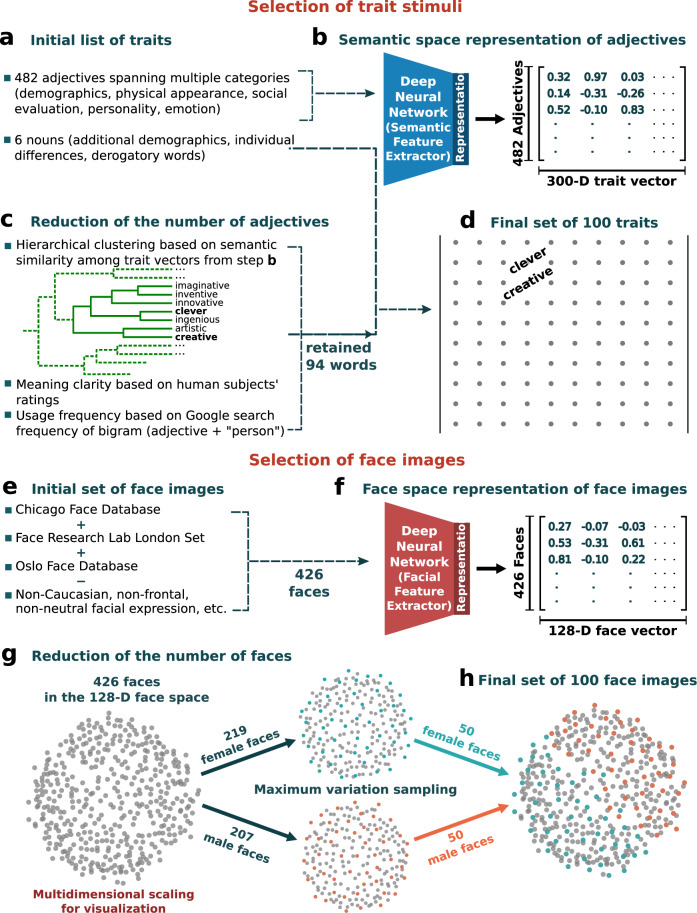
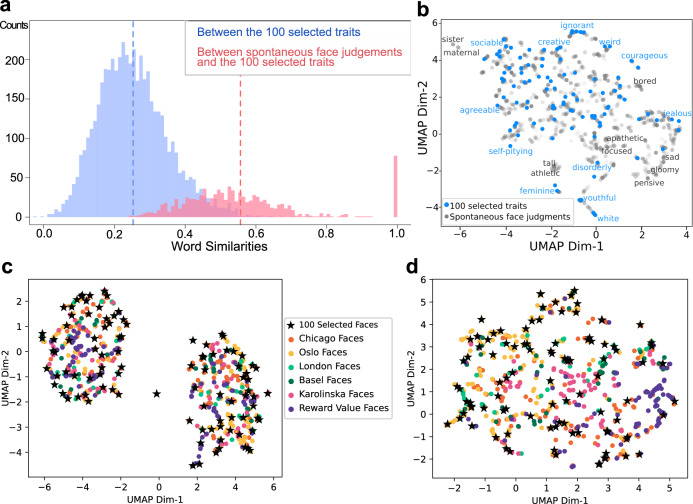
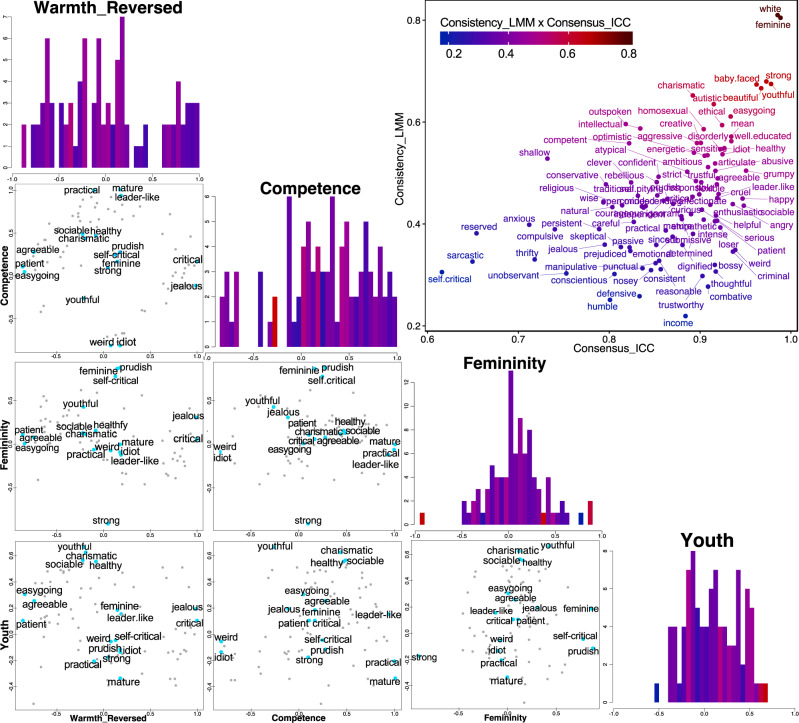
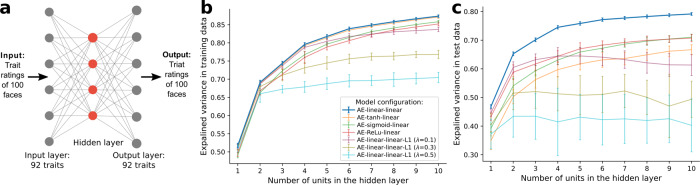
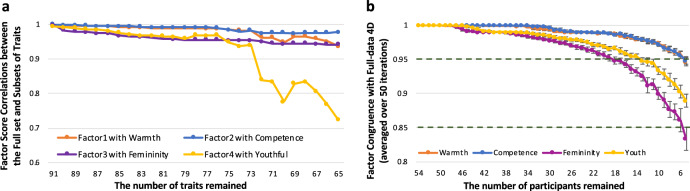
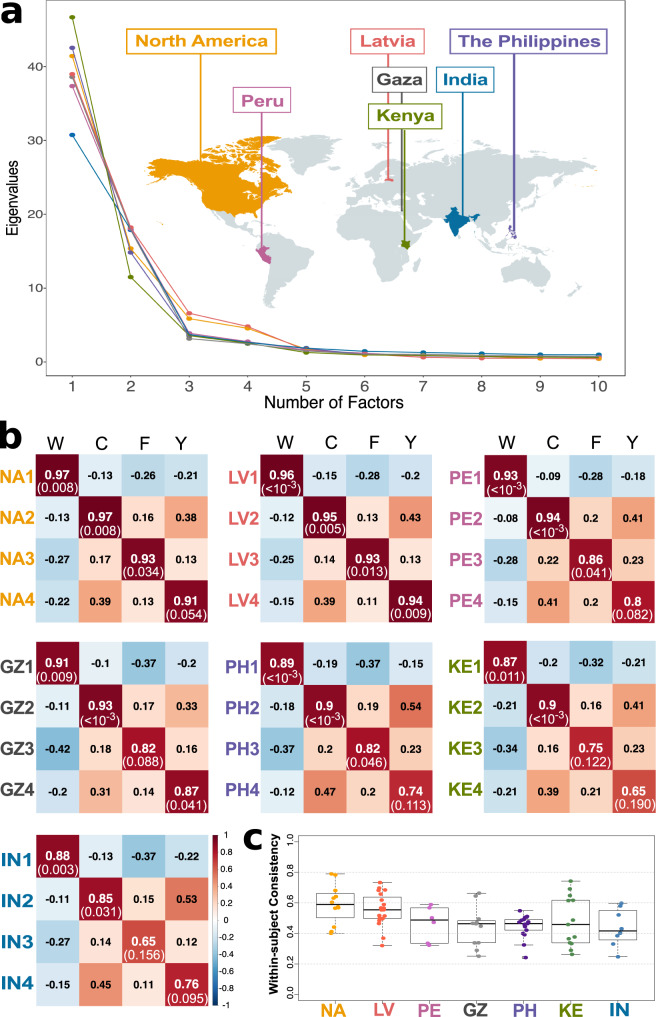
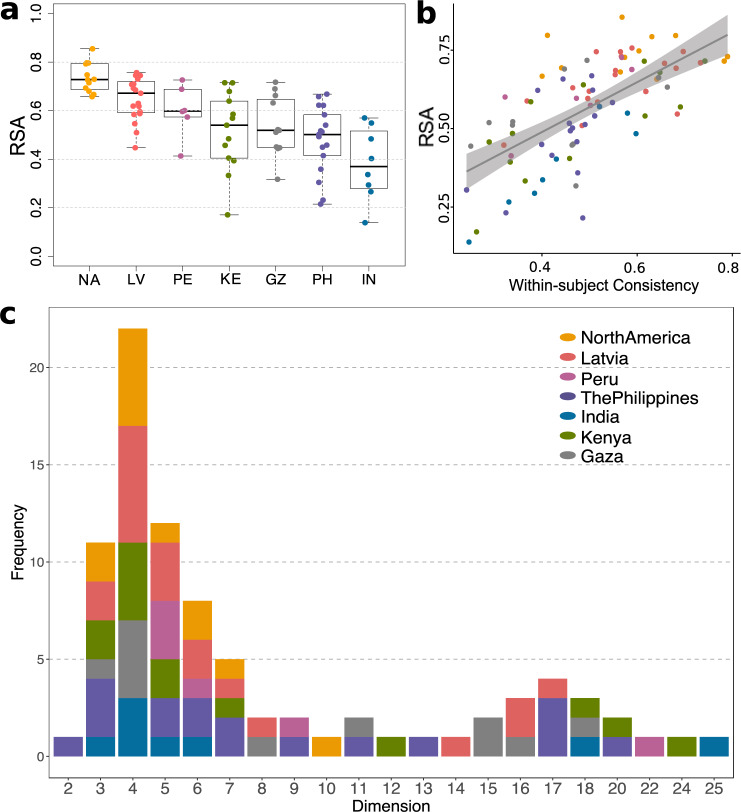
People readily (but often inaccurately) attribute traits to others based on faces. While the details of attributions depend on the language available to describe social traits, psychological theories argue that two or three dimensions (such as valence and dominance) summarize social trait attributions from faces. However, prior work has used only a small number of trait words (12 to 18), limiting conclusions to date. In two large-scale, preregistered studies we ask participants to rate 100 faces (obtained from existing face stimuli sets), using a list of 100 English trait words that we derived using deep neural network analysis of words that have been used by other participants in prior studies to describe faces. In study 1 we find that these attributions are best described by four psychological dimensions, which we interpret as "warmth", "competence", "femininity", and "youth". In study 2 we partially reproduce these four dimensions using the same stimuli among additional participant raters from multiple regions around the world, in both aggregated and individual-level data. These results provide a comprehensive characterization of trait attributions from faces, although we note our conclusions are limited by the scope of our study (in particular we note only white faces and English trait words were included).
© 2021. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
References
-
- Todorov, A. Face value: the irresistible influence of first impressions. (Princeton University Press, 2017).
-
- Abir Y, Sklar AY, Dotsch R, Todorov A, Hassin RR. The determinants of consciousness of human faces. Nat. Hum. Behav. 2018;2:194–199. doi: 10.1038/s41562-017-0266-3. - DOI
-
- Rule, N. O., Slepian, M. L. & Ambady, N. A memory advantage for untrustworthy faces. Cognition.125, 207–218 (2012). - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
