

Comparison of domain adaptation techniques for white matter hyperintensity segmentation in brain MR images
- PMID: 34454295
- PMCID: PMC8573594
- DOI: 10.1016/j.media.2021.102215
Comparison of domain adaptation techniques for white matter hyperintensity segmentation in brain MR images
Abstract
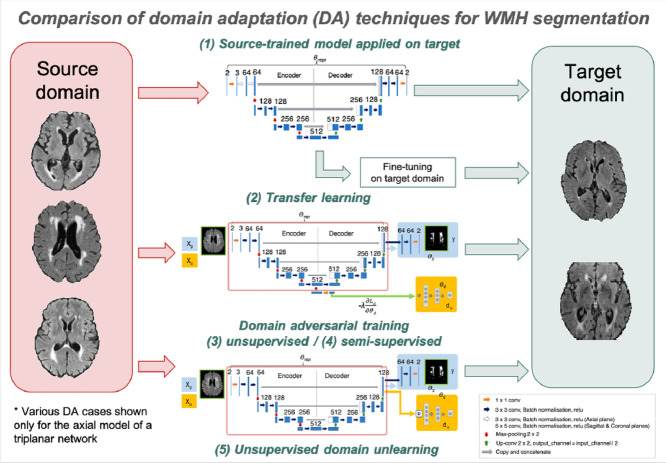
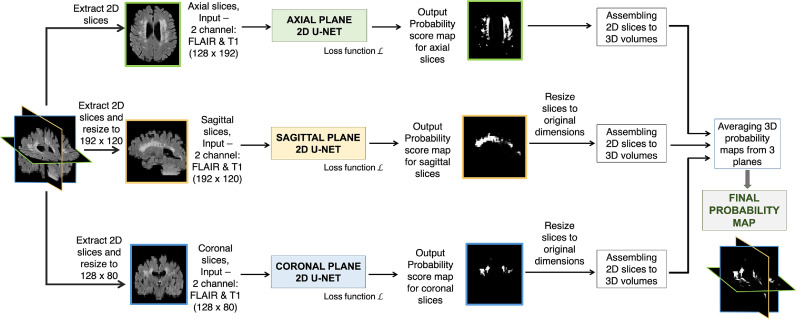
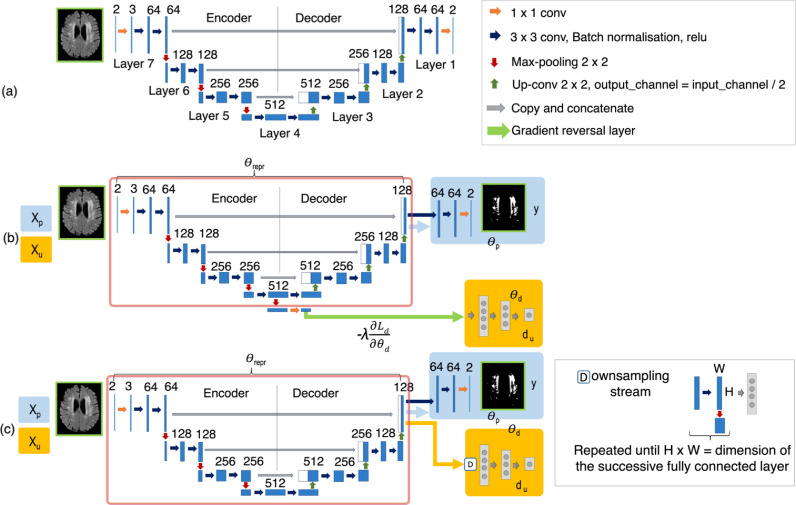
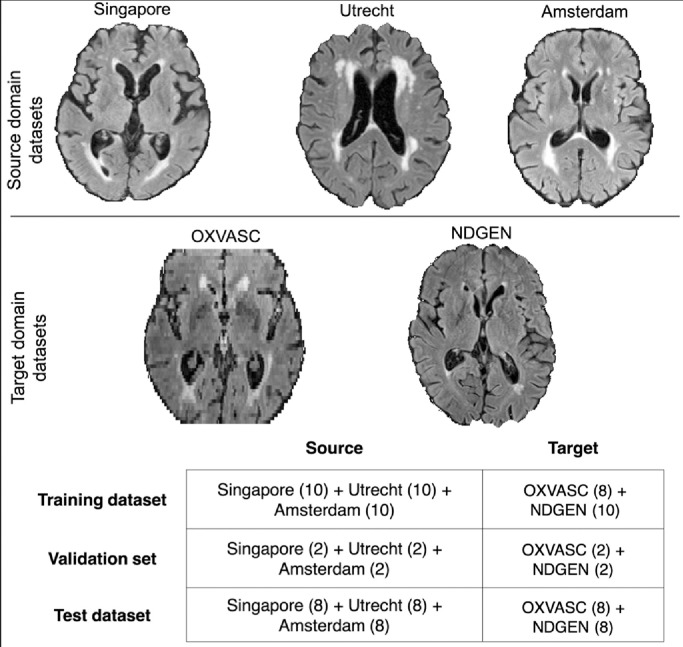
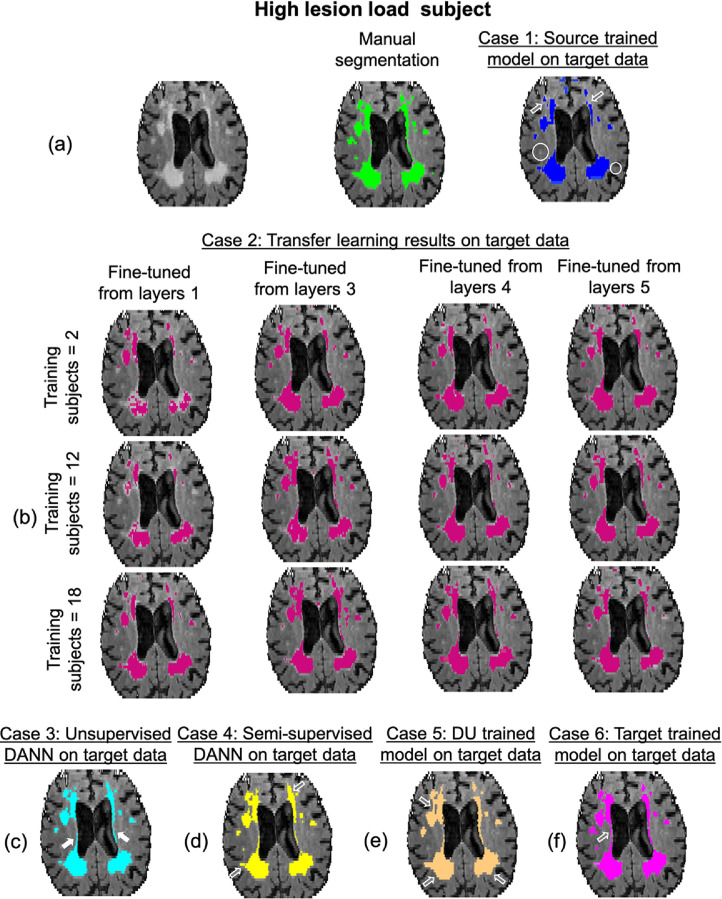
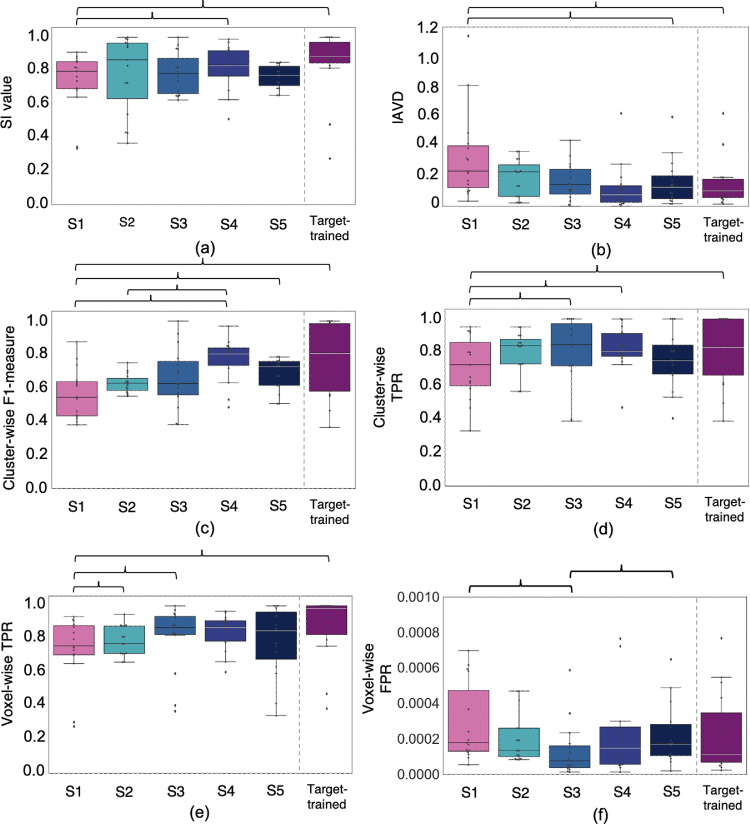
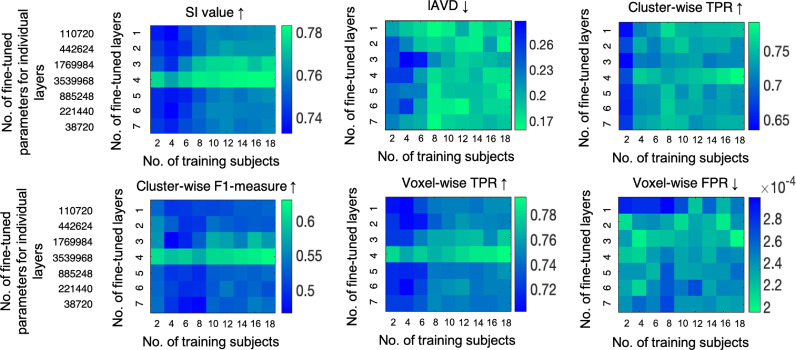
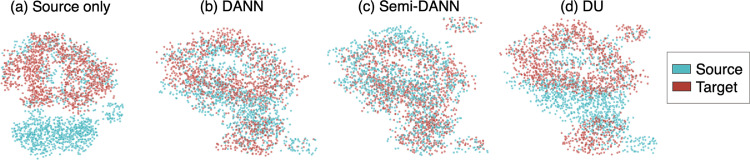
Robust automated segmentation of white matter hyperintensities (WMHs) in different datasets (domains) is highly challenging due to differences in acquisition (scanner, sequence), population (WMH amount and location) and limited availability of manual segmentations to train supervised algorithms. In this work we explore various domain adaptation techniques such as transfer learning and domain adversarial learning methods, including domain adversarial neural networks and domain unlearning, to improve the generalisability of our recently proposed triplanar ensemble network, which is our baseline model. We used datasets with variations in intensity profile, lesion characteristics and acquired using different scanners. For the source domain, we considered a dataset consisting of data acquired from 3 different scanners, while the target domain consisted of 2 datasets. We evaluated the domain adaptation techniques on the target domain datasets, and additionally evaluated the performance on the source domain test dataset for the adversarial techniques. For transfer learning, we also studied various training options such as minimal number of unfrozen layers and subjects required for fine-tuning in the target domain. On comparing the performance of different techniques on the target dataset, domain adversarial training of neural network gave the best performance, making the technique promising for robust WMH segmentation.
Keywords: Deep learning; Domain adaptation; Segmentation; White matter hyperintensities.
Copyright © 2021. Published by Elsevier B.V.
Conflict of interest statement
Declaration of Competing Interest The authors declare the following financial interests/personal relationships which may be considered as potential competing interests: Mark Jenkinson receives royalties from licensing of FSL to non-academic, commercial parties.
Figures
Similar articles
-
Exploring approaches to tackle cross-domain challenges in brain medical image segmentation: a systematic review.Front Neurosci. 2024 Jun 14;18:1401329. doi: 10.3389/fnins.2024.1401329. eCollection 2024. Front Neurosci. 2024. PMID: 38948927 Free PMC article.
-
Triplanar ensemble U-Net model for white matter hyperintensities segmentation on MR images.Med Image Anal. 2021 Oct;73:102184. doi: 10.1016/j.media.2021.102184. Epub 2021 Jul 18. Med Image Anal. 2021. PMID: 34325148 Free PMC article.
-
SegAE: Unsupervised white matter lesion segmentation from brain MRIs using a CNN autoencoder.Neuroimage Clin. 2019;24:102085. doi: 10.1016/j.nicl.2019.102085. Epub 2019 Nov 9. Neuroimage Clin. 2019. PMID: 31835288 Free PMC article.
-
Deep Bayesian networks for uncertainty estimation and adversarial resistance of white matter hyperintensity segmentation.Hum Brain Mapp. 2022 May;43(7):2089-2108. doi: 10.1002/hbm.25784. Epub 2022 Jan 28. Hum Brain Mapp. 2022. PMID: 35088930 Free PMC article.
-
Evaluation of a deep learning approach for the segmentation of brain tissues and white matter hyperintensities of presumed vascular origin in MRI.Neuroimage Clin. 2017 Oct 12;17:251-262. doi: 10.1016/j.nicl.2017.10.007. eCollection 2018. Neuroimage Clin. 2017. PMID: 29159042 Free PMC article.
Cited by
-
Deep learning-based automated segmentation for the quantitative diagnosis of cerebral small vessel disease via multisequence MRI.Front Neurol. 2025 May 27;16:1540923. doi: 10.3389/fneur.2025.1540923. eCollection 2025. Front Neurol. 2025. PMID: 40496122 Free PMC article.
-
Deep Learning Analysis of White Matter Hyperintensity and its Association with Comprehensive Vascular Factors in Two Large General Populations.J Imaging Inform Med. 2025 Jan 6. doi: 10.1007/s10278-024-01372-8. Online ahead of print. J Imaging Inform Med. 2025. PMID: 39762547
-
CrossMoDA 2021 challenge: Benchmark of cross-modality domain adaptation techniques for vestibular schwannoma and cochlea segmentation.Med Image Anal. 2023 Jan;83:102628. doi: 10.1016/j.media.2022.102628. Epub 2022 Sep 21. Med Image Anal. 2023. PMID: 36283200 Free PMC article.
-
Exploring approaches to tackle cross-domain challenges in brain medical image segmentation: a systematic review.Front Neurosci. 2024 Jun 14;18:1401329. doi: 10.3389/fnins.2024.1401329. eCollection 2024. Front Neurosci. 2024. PMID: 38948927 Free PMC article.
-
Cross-site validation of lung cancer diagnosis by electronic nose with deep learning: a multicenter prospective study.Respir Res. 2024 May 10;25(1):203. doi: 10.1186/s12931-024-02840-z. Respir Res. 2024. PMID: 38730430 Free PMC article.
References
-
- Admiraal-Behloul F., Van Den Heuvel D., Olofsen H., van Osch M.J., van der Grond J., Van Buchem M., Reiber J. Fully automatic segmentation of white matter hyperintensities in MR images of the elderly. NeuroImage. 2005;28(3):607–617. - PubMed
-
- Ben-David S., Blitzer J., Crammer K., Kulesza A., Pereira F., Vaughan J.W. A theory of learning from different domains. Mach. Learn. 2010;79(1–2):151–175.
-
- Bordin V., Bertani I., Mattioli I., Sundaresan V., McCarthy P., Suri S., Zsoldos E., Filippini N., Mahmood A., Melazzini L. Integrating large-scale neuroimaging research datasets: harmonisation of white matter hyperintensity measurements across Whitehall and UK Biobank datasets. bioRxiv. 2020 - PMC - PubMed
-
- Cao Z., Long M., Wang J., Jordan M.I. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018. Partial transfer learning with selective adversarial networks; pp. 2724–2732.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
