

Ultrafast homomorphic encryption models enable secure outsourcing of genotype imputation
- PMID: 34464590
- PMCID: PMC9898842
- DOI: 10.1016/j.cels.2021.07.010
Ultrafast homomorphic encryption models enable secure outsourcing of genotype imputation
Abstract
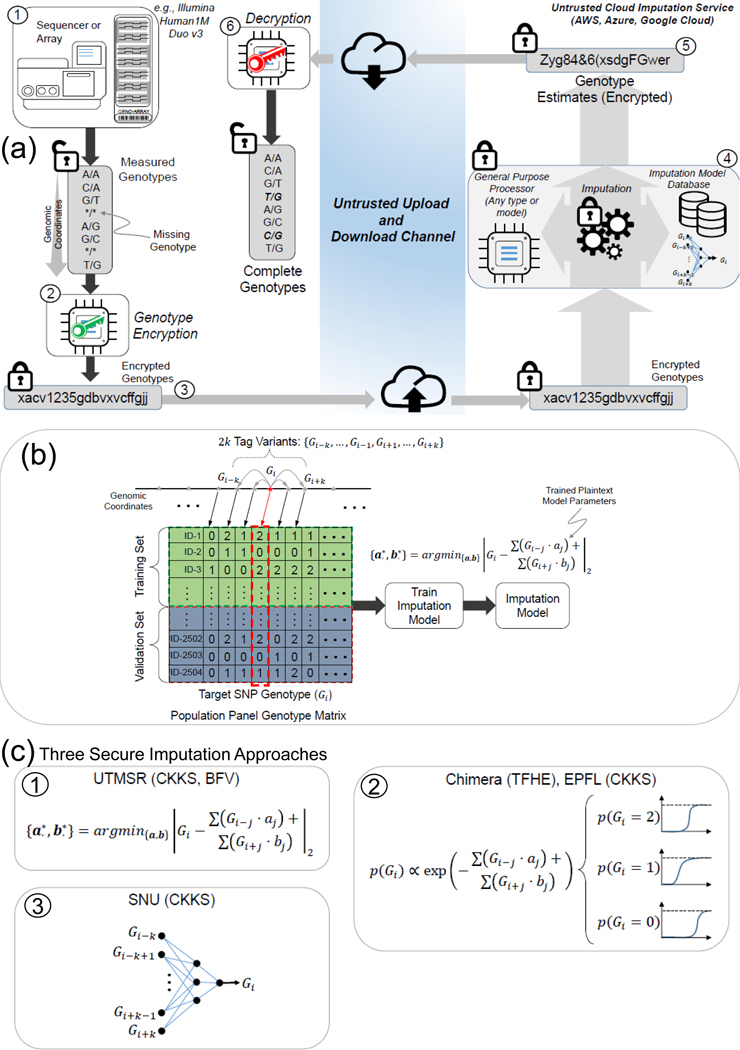
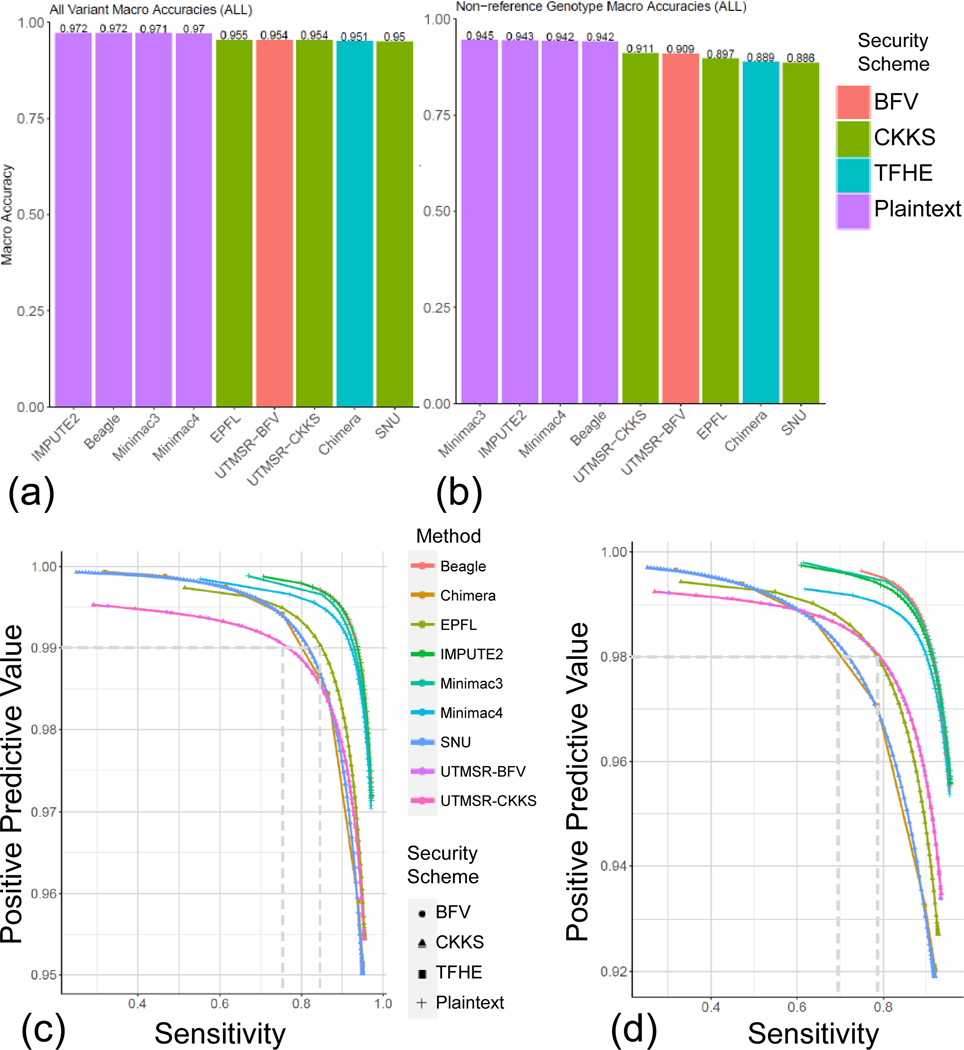
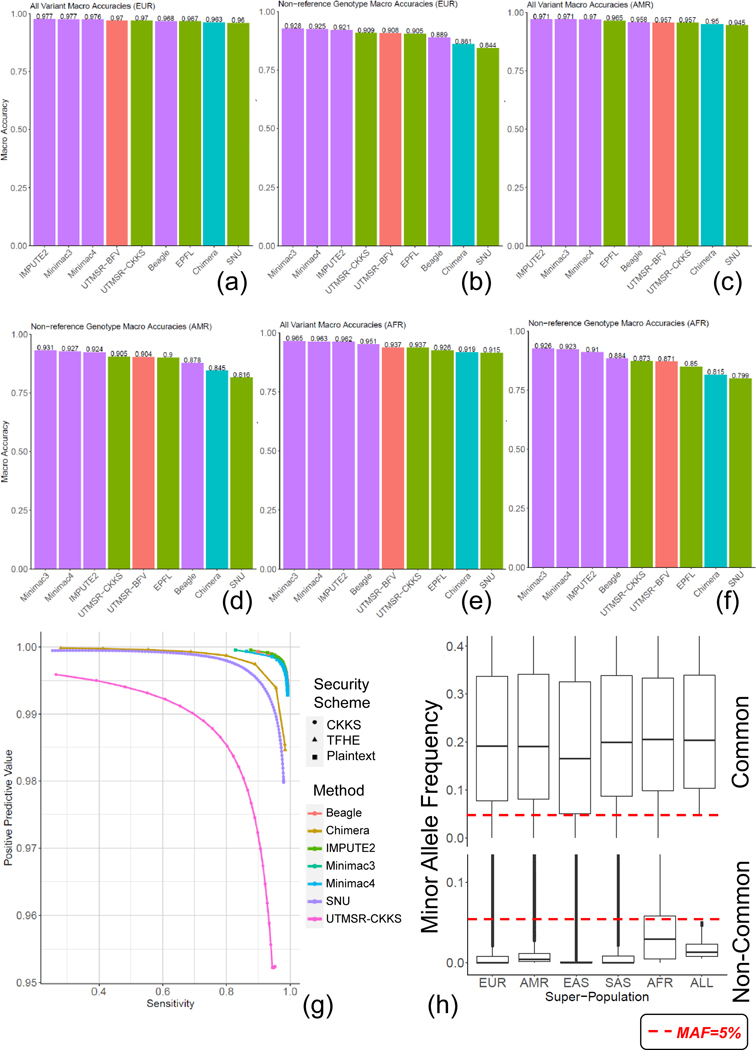
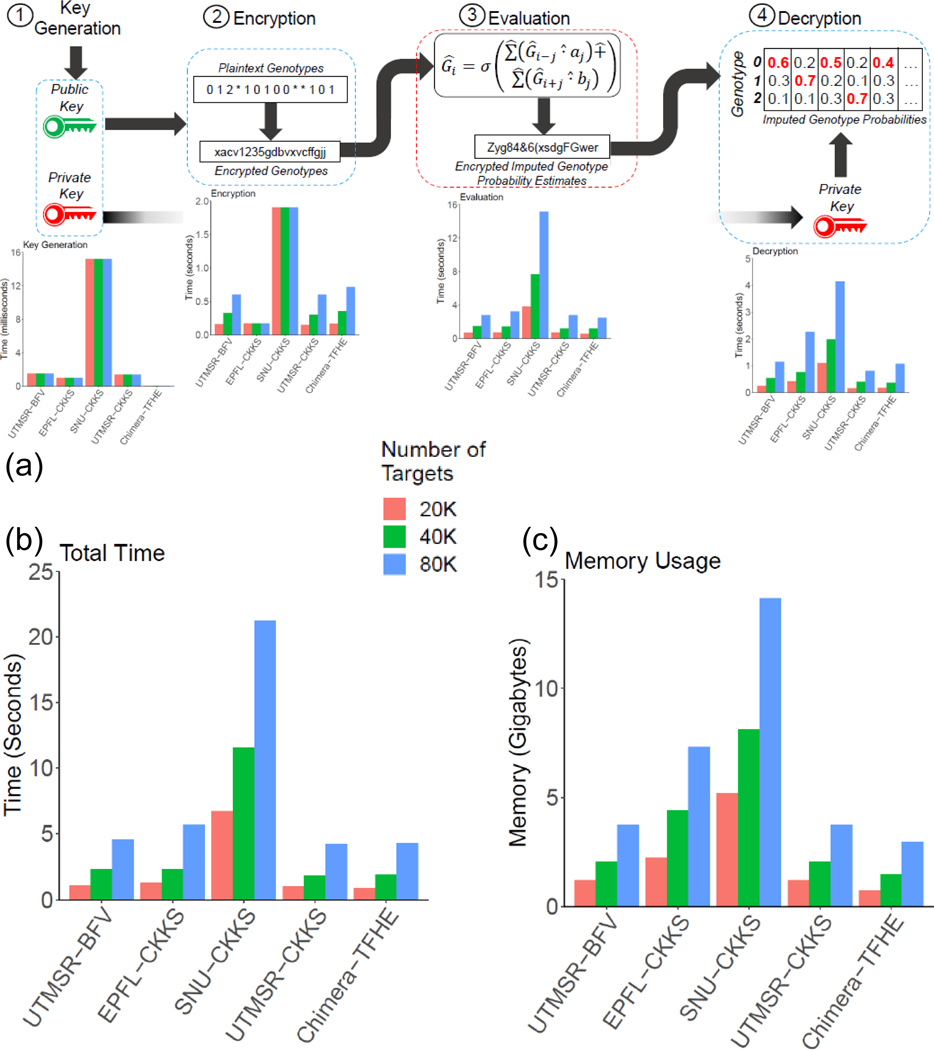
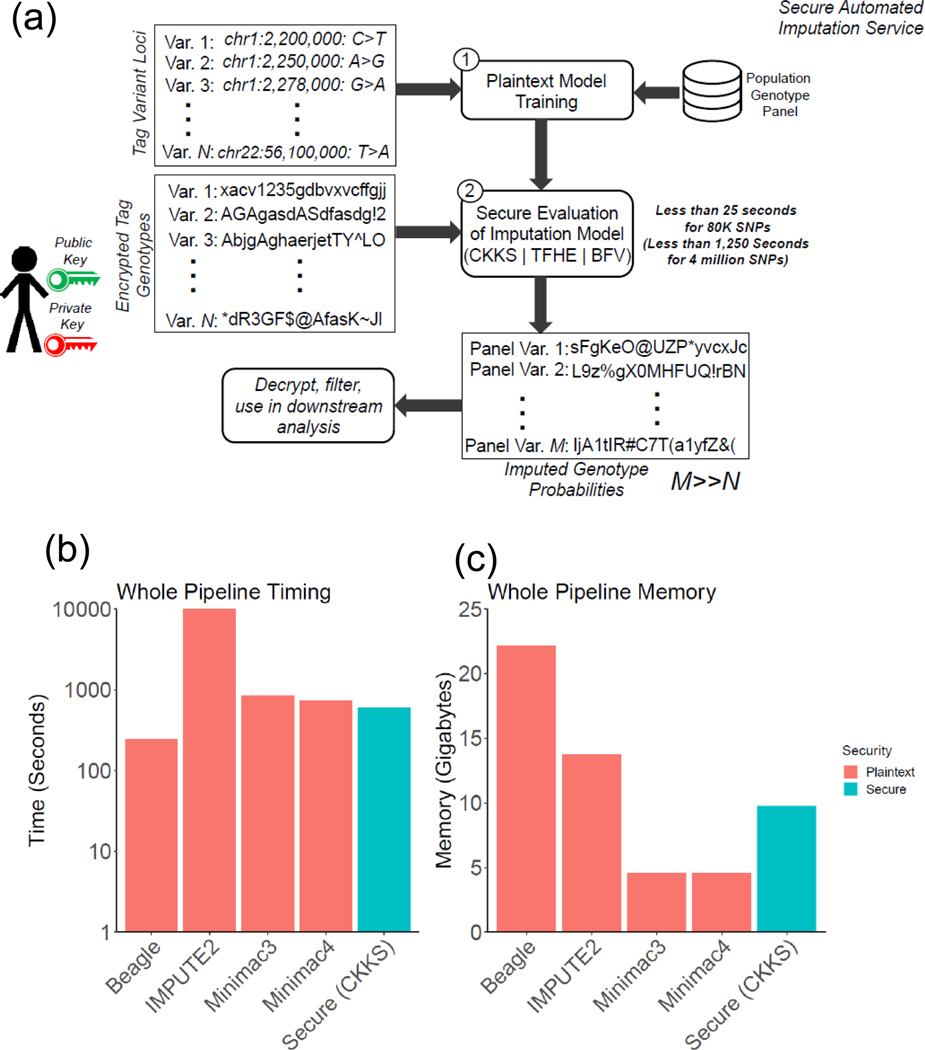
Genotype imputation is a fundamental step in genomic data analysis, where missing variant genotypes are predicted using the existing genotypes of nearby "tag" variants. Although researchers can outsource genotype imputation, privacy concerns may prohibit genetic data sharing with an untrusted imputation service. Here, we developed secure genotype imputation using efficient homomorphic encryption (HE) techniques. In HE-based methods, the genotype data are secure while it is in transit, at rest, and in analysis. It can only be decrypted by the owner. We compared secure imputation with three state-of-the-art non-secure methods and found that HE-based methods provide genetic data security with comparable accuracy for common variants. HE-based methods have time and memory requirements that are comparable or lower than those for the non-secure methods. Our results provide evidence that HE-based methods can practically perform resource-intensive computations for high-throughput genetic data analysis. The source code is freely available for download at https://github.com/K-miran/secure-imputation.
Keywords: genetic data encryption; genomic privacy; genotype imputation.
Copyright © 2021 The Authors. Published by Elsevier Inc. All rights reserved.
Conflict of interest statement
Declaration of interests The authors declare no competing interests.
Figures
Comment in
-
Paving the path toward genomic privacy with secure imputation.Cell Syst. 2021 Oct 20;12(10):950-952. doi: 10.1016/j.cels.2021.09.006. Cell Syst. 2021. PMID: 34672957
References
-
- Albrecht M, Chase M, Chen H, Ding J, Goldwasser S, Gorbunov S, Halevi S, Hoffstein J, Laine K, Lauter K, Lokam S, Micciancio D, Moody D, Morrison T, Sahai A. & Vaikuntanathan V. (2018), Homomorphic encryption security standard, Technical report, HomomorphicEncryption.org, Toronto, Canada.
-
- Albrecht MR, Player R. & Scott S. (2015), ‘On the concrete hardness of learning with errors’, J. Mathematical Cryptology 9(3), 169–203. URL: http://www.degruyter.com/view/j/jmc.2015.9.issue-3/jmc-2015-0016/jmc-201...
-
- Belmont JW, Hardenbol P, Willis TD, Yu F, Yang H, Ch’Ang LY, Huang W, Liu B, Shen Y, Tam PKH, Tsui LC, Waye MMY, Wong JTF, Zeng C, Zhang Q, Chee MS, Galver LM, Kruglyak S, Murray SS, Oliphant AR, Montpetit A, Chagnon F, Ferretti V, Leboeuf M, Phillips MS, Verner A, Duan S, Lind DL, Miller RD, Rice J, Saccone NL, Taillon-Miller P, Xiao M, Sekine A, Sorimachi K, Tanaka Y, Tsunoda T, Yoshino E, Bentley DR, Hunt S, Powell D, Zhang H, Matsuda I, Fukushima Y, Macer DR, Suda E, Rotimi C, Adebamowo CA, Aniagwu T, Marshall PA, Matthew O, Nkwodimmah C, Royal CD, Leppert MF, Dixon M, Cunningham F, Kanani A, Thorisson GA, Chen PE, Cutler DJ, Kashuk CS, Donnelly P, Marchini J, McVean GA, Myers SR, Cardon LR, Morris A, Weir BS, Mullikin JC, Feolo M, Daly MJ, Qiu R, Kent A, Dunston GM, Kato K, Niikawa N, Watkin J, Gibbs RA, Sodergren E, Weinstock GM, Wilson RK, Fulton LL, Rogers J, Birren BW, Han H, Wang H, Godbout M, Wallenburg JC, L’Archevêque P, Bellemare G, Todani K, Fujita T, Tanaka S, Holden AL, Collins FS, Brooks LD, McEwen JE, Guyer MS, Jordan E, Peterson JL, Spiegel J, Sung LM, Zacharia LF, Kennedy K, Dunn MG, Seabrook R, Shillito M, Skene B, Stewart JG, Valle DL, Clayton EW, Jorde LB, Chakravarti A, Cho MK, Duster T, Foster MW, Jasperse M, Knoppers BM, Kwok PY, Licinio J, Long JC, Ossorio P, Wang VO, Rotimi CN, Spallone P, Terry SF, Lander ES, Lai EH, Nickerson DA, Abecasis GR, Altshuler D, Boehnke M, Deloukas P, Douglas JA, Gabriel SB, Hudson RR, Hudson TJ, Kruglyak L, Nakamura Y, Nussbaum RL, Schaffner SF, Sherry ST, Stein LD & Tanaka T. (2003), ‘The international hapmap project’, Nature 426(6968), 789–796. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
