

Use of artificial intelligence for image analysis in breast cancer screening programmes: systematic review of test accuracy
- PMID: 34470740
- PMCID: PMC8409323
- DOI: 10.1136/bmj.n1872
Use of artificial intelligence for image analysis in breast cancer screening programmes: systematic review of test accuracy
Abstract
Objective: To examine the accuracy of artificial intelligence (AI) for the detection of breast cancer in mammography screening practice.
Design: Systematic review of test accuracy studies.
Data sources: Medline, Embase, Web of Science, and Cochrane Database of Systematic Reviews from 1 January 2010 to 17 May 2021.
Eligibility criteria: Studies reporting test accuracy of AI algorithms, alone or in combination with radiologists, to detect cancer in women's digital mammograms in screening practice, or in test sets. Reference standard was biopsy with histology or follow-up (for screen negative women). Outcomes included test accuracy and cancer type detected.
Study selection and synthesis: Two reviewers independently assessed articles for inclusion and assessed the methodological quality of included studies using the QUality Assessment of Diagnostic Accuracy Studies-2 (QUADAS-2) tool. A single reviewer extracted data, which were checked by a second reviewer. Narrative data synthesis was performed.
Results: Twelve studies totalling 131 822 screened women were included. No prospective studies measuring test accuracy of AI in screening practice were found. Studies were of poor methodological quality. Three retrospective studies compared AI systems with the clinical decisions of the original radiologist, including 79 910 women, of whom 1878 had screen detected cancer or interval cancer within 12 months of screening. Thirty four (94%) of 36 AI systems evaluated in these studies were less accurate than a single radiologist, and all were less accurate than consensus of two or more radiologists. Five smaller studies (1086 women, 520 cancers) at high risk of bias and low generalisability to the clinical context reported that all five evaluated AI systems (as standalone to replace radiologist or as a reader aid) were more accurate than a single radiologist reading a test set in the laboratory. In three studies, AI used for triage screened out 53%, 45%, and 50% of women at low risk but also 10%, 4%, and 0% of cancers detected by radiologists.
Conclusions: Current evidence for AI does not yet allow judgement of its accuracy in breast cancer screening programmes, and it is unclear where on the clinical pathway AI might be of most benefit. AI systems are not sufficiently specific to replace radiologist double reading in screening programmes. Promising results in smaller studies are not replicated in larger studies. Prospective studies are required to measure the effect of AI in clinical practice. Such studies will require clear stopping rules to ensure that AI does not reduce programme specificity.
Study registration: Protocol registered as PROSPERO CRD42020213590.
© Author(s) (or their employer(s)) 2019. Re-use permitted under CC BY-NC. No commercial re-use. See rights and permissions. Published by BMJ.
Conflict of interest statement
Competing interests: All authors have completed the ICMJE uniform disclosure form at www.icmje.org/coi_disclosure.pdf and declare: CS, ST-P, KF, JG, and AC have received funding from the UK National Screening Committee for the conduct of the review; ST-P is funded by the National Institute for Health Research (NIHR) through a career development fellowship; AC is partly supported by the NIHR Applied Research Collaboration West Midlands; SJ and DT have nothing to declare; no other relationships or activities that could appear to have influenced the submitted work.
Figures
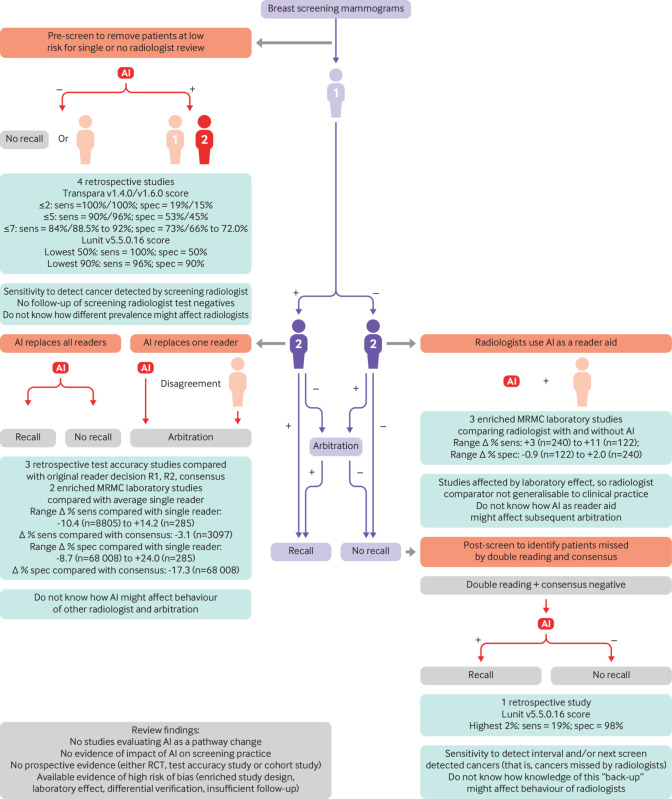
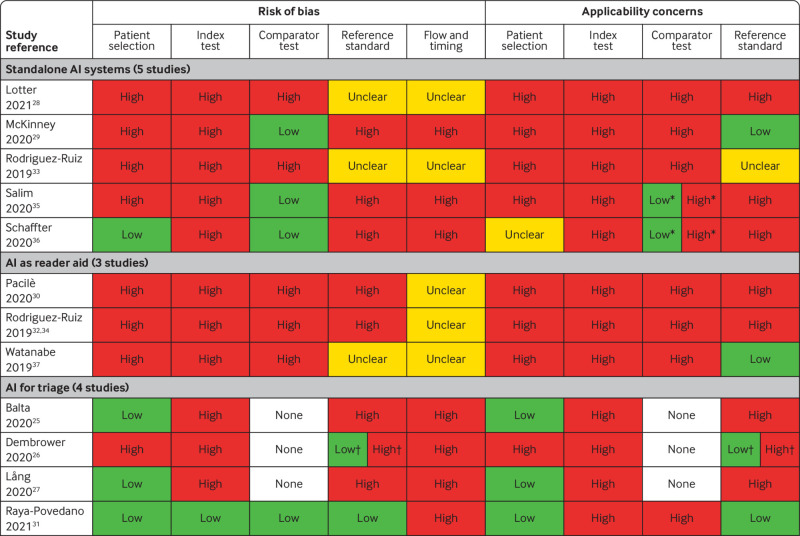
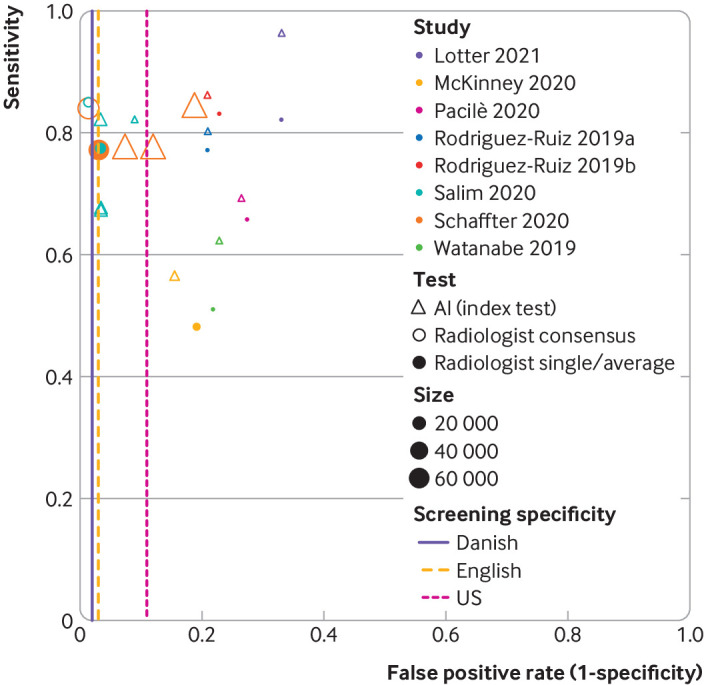
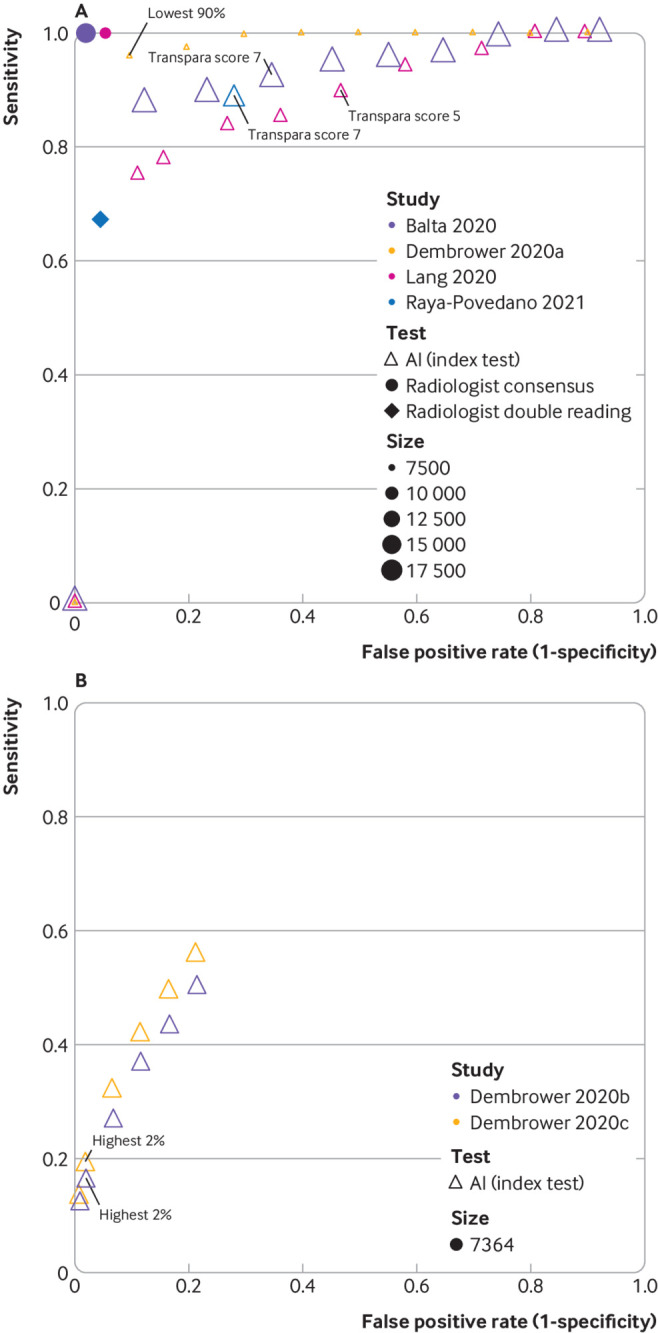
Comment in
-
Readiness for mammography and artificial intelligence.Lancet. 2021 Nov 20;398(10314):1867. doi: 10.1016/S0140-6736(21)02484-3. Lancet. 2021. PMID: 34801097 No abstract available.
References
-
- Fitzmaurice C, Allen C, Barber RM, et al. Global Burden of Disease Cancer Collaboration . Global, Regional, and National Cancer Incidence, Mortality, Years of Life Lost, Years Lived With Disability, and Disability-Adjusted Life-years for 32 Cancer Groups, 1990 to 2015: A Systematic Analysis for the Global Burden of Disease Study. JAMA Oncol 2017;3:524-48. 10.1001/jamaoncol.2016.5688. - DOI - PMC - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Medical