

Spiking Autoencoders With Temporal Coding
- PMID: 34483829
- PMCID: PMC8414972
- DOI: 10.3389/fnins.2021.712667
Spiking Autoencoders With Temporal Coding
Abstract
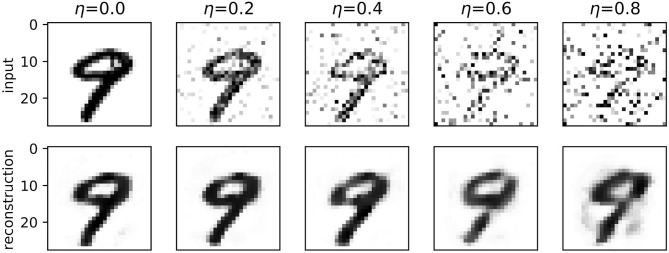
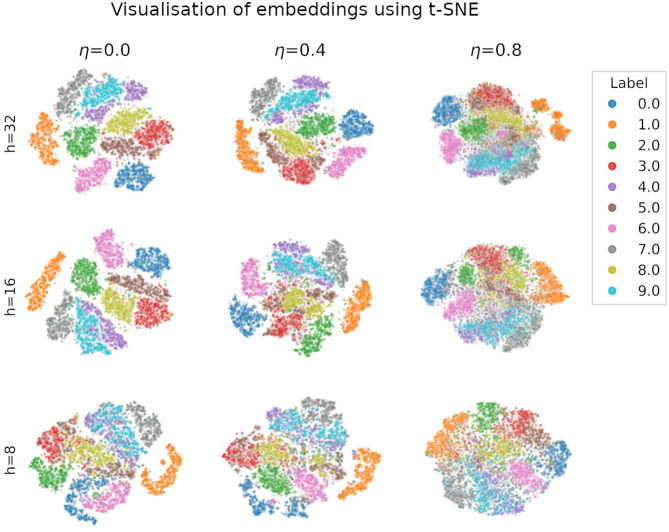
Spiking neural networks with temporal coding schemes process information based on the relative timing of neuronal spikes. In supervised learning tasks, temporal coding allows learning through backpropagation with exact derivatives, and achieves accuracies on par with conventional artificial neural networks. Here we introduce spiking autoencoders with temporal coding and pulses, trained using backpropagation to store and reconstruct images with high fidelity from compact representations. We show that spiking autoencoders with a single layer are able to effectively represent and reconstruct images from the neuromorphically-encoded MNIST and FMNIST datasets. We explore the effect of different spike time target latencies, data noise levels and embedding sizes, as well as the classification performance from the embeddings. The spiking autoencoders achieve results similar to or better than conventional non-spiking autoencoders. We find that inhibition is essential in the functioning of the spiking autoencoders, particularly when the input needs to be memorised for a longer time before the expected output spike times. To reconstruct images with a high target latency, the network learns to accumulate negative evidence and to use the pulses as excitatory triggers for producing the output spikes at the required times. Our results highlight the potential of spiking autoencoders as building blocks for more complex biologically-inspired architectures. We also provide open-source code for the model.
Keywords: autoencoders; backpropagation; biologically-inspired artificial intelligence; inhibition; latency coding; spiking networks; temporal coding.
Copyright © 2021 Comşa, Versari, Fischbacher and Alakuijala.
Conflict of interest statement
All authors were employed by Google Research, Switzerland. Parts of the ideas presented here are covered by pending PCT Patent Application No. PCT/US2019/055848 (Temporal Coding in Leaky Spiking Neural Networks), filed by Google in 2019.
Figures









References
-
- Abadi M., Agarwal A., Barham P., Brevdo E., Chen Z., Citro C., et al. (2015). TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. Available online at: tensorflow.org.
-
- Ahmed F. Y., Shamsuddin S. M., Hashim S. Z. M. (2013). Improved spikeprop for using particle swarm optimization. Math. Probl. Eng. 2013:257085. 10.1155/2013/257085 - DOI
-
- Bengio Y., Lee D.-H., Bornschein J., Mesnard T., Lin Z. (2015). Towards biologically plausible deep learning. arXiv [preprint]. arXiv:1502.04156. Available online at: https://arxiv.org/abs/1502.04156
LinkOut - more resources
Full Text Sources