

Automated detection of poor-quality data: case studies in healthcare
- PMID: 34504205
- PMCID: PMC8429593
- DOI: 10.1038/s41598-021-97341-0
Automated detection of poor-quality data: case studies in healthcare
Abstract
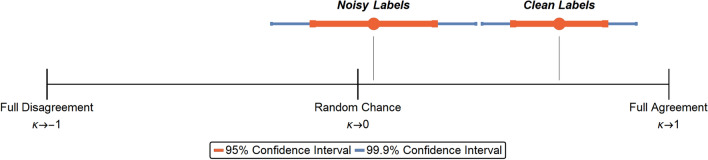
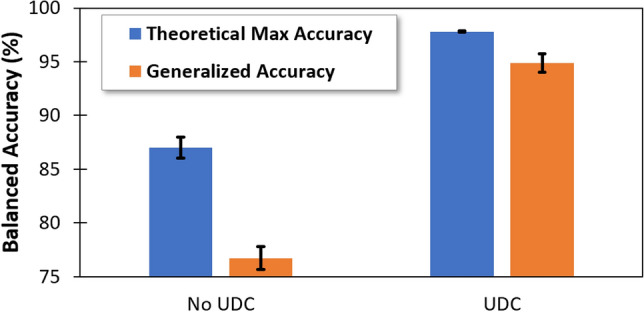
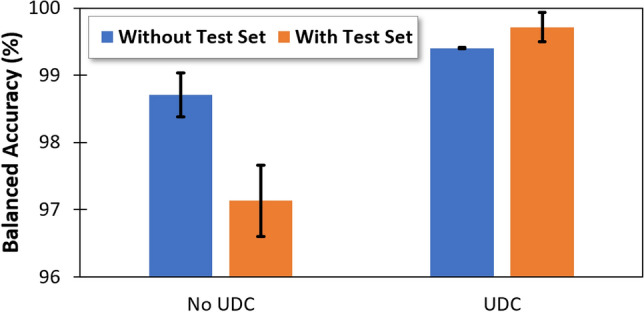
The detection and removal of poor-quality data in a training set is crucial to achieve high-performing AI models. In healthcare, data can be inherently poor-quality due to uncertainty or subjectivity, but as is often the case, the requirement for data privacy restricts AI practitioners from accessing raw training data, meaning manual visual verification of private patient data is not possible. Here we describe a novel method for automated identification of poor-quality data, called Untrainable Data Cleansing. This method is shown to have numerous benefits including protection of private patient data; improvement in AI generalizability; reduction in time, cost, and data needed for training; all while offering a truer reporting of AI performance itself. Additionally, results show that Untrainable Data Cleansing could be useful as a triage tool to identify difficult clinical cases that may warrant in-depth evaluation or additional testing to support a diagnosis.
© 2021. The Author(s).
Conflict of interest statement
J.M.M.H., D.P., and M.P. are co-owners of Presagen. S.M.D., T.V.N., and M.A.D. are employees of Presagen.
Figures

References
-
- Goodfellow I, Bengio Y, Courville A. Deep Learning. MIT Press; 2016.
LinkOut - more resources
Full Text Sources
