

Partitioning variability in animal behavioral videos using semi-supervised variational autoencoders
- PMID: 34550974
- PMCID: PMC8489729
- DOI: 10.1371/journal.pcbi.1009439
Partitioning variability in animal behavioral videos using semi-supervised variational autoencoders
Abstract
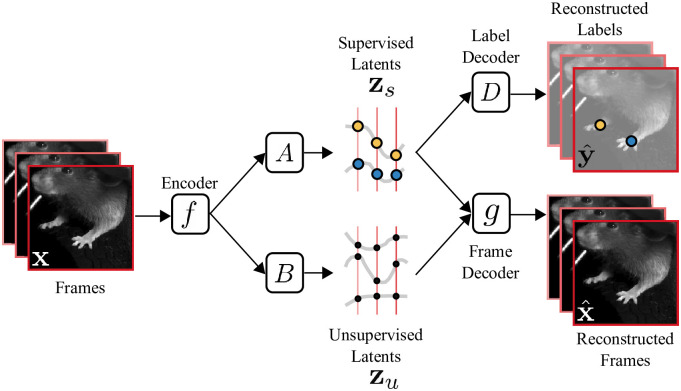
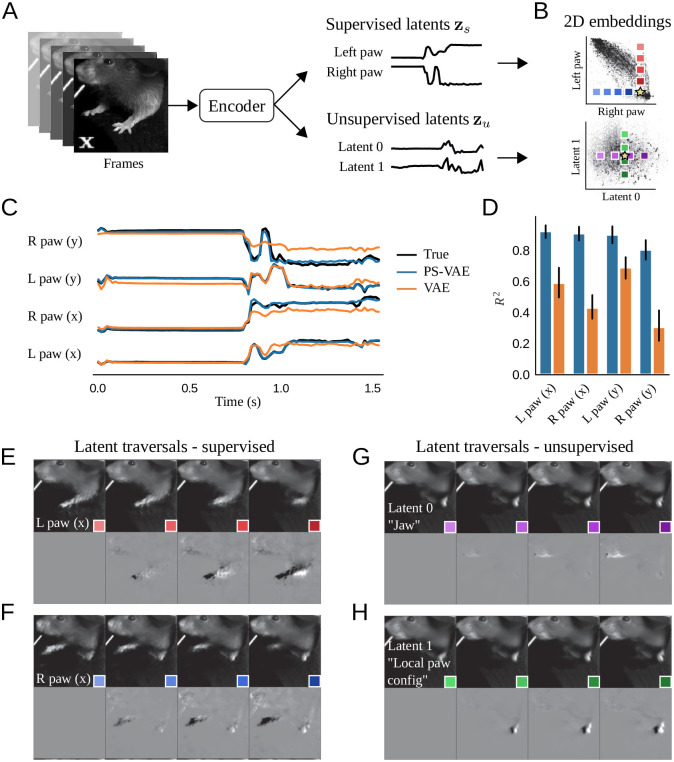
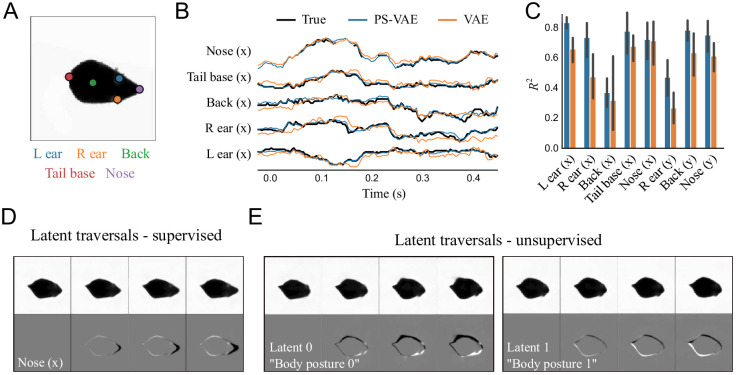
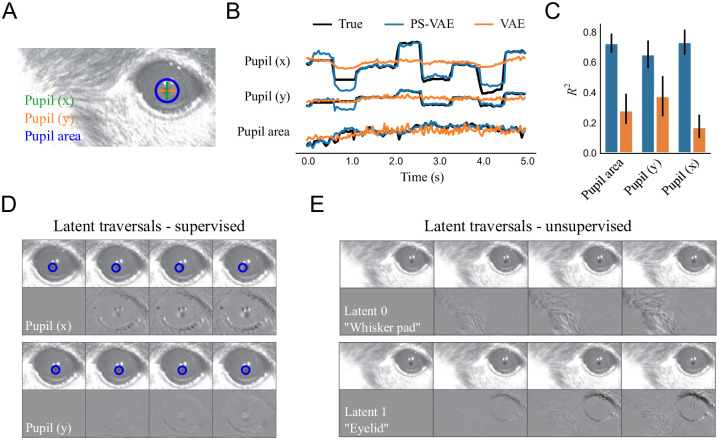
Recent neuroscience studies demonstrate that a deeper understanding of brain function requires a deeper understanding of behavior. Detailed behavioral measurements are now often collected using video cameras, resulting in an increased need for computer vision algorithms that extract useful information from video data. Here we introduce a new video analysis tool that combines the output of supervised pose estimation algorithms (e.g. DeepLabCut) with unsupervised dimensionality reduction methods to produce interpretable, low-dimensional representations of behavioral videos that extract more information than pose estimates alone. We demonstrate this tool by extracting interpretable behavioral features from videos of three different head-fixed mouse preparations, as well as a freely moving mouse in an open field arena, and show how these interpretable features can facilitate downstream behavioral and neural analyses. We also show how the behavioral features produced by our model improve the precision and interpretation of these downstream analyses compared to using the outputs of either fully supervised or fully unsupervised methods alone.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
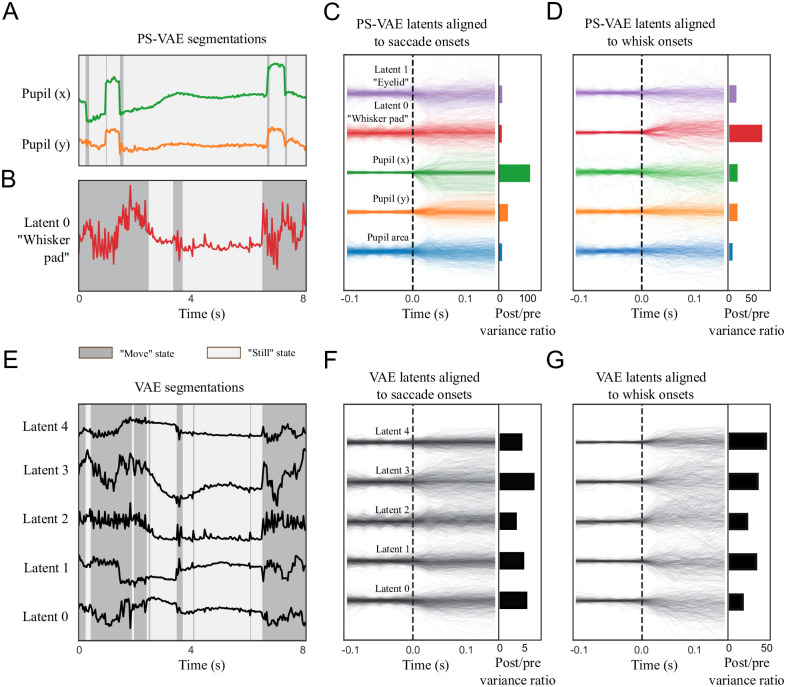
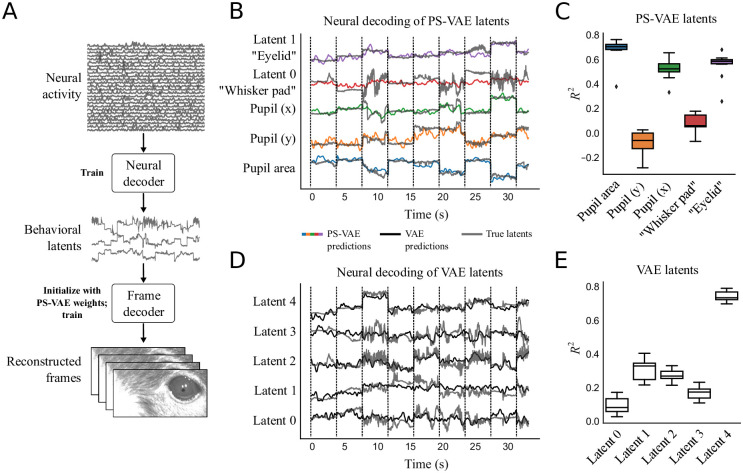
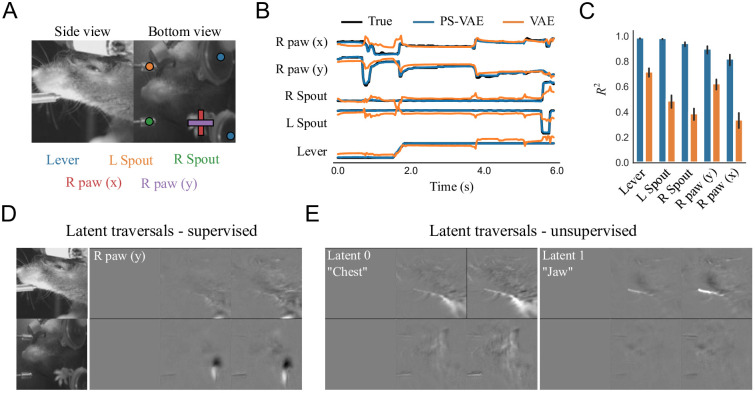
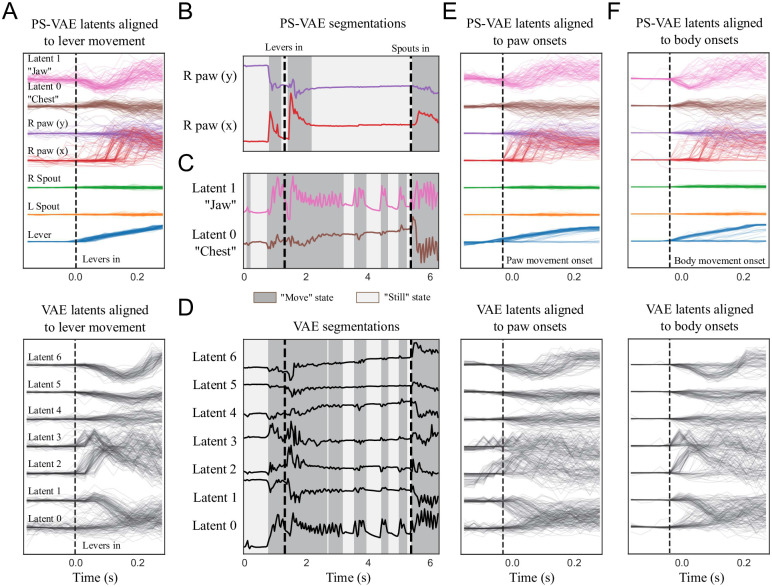
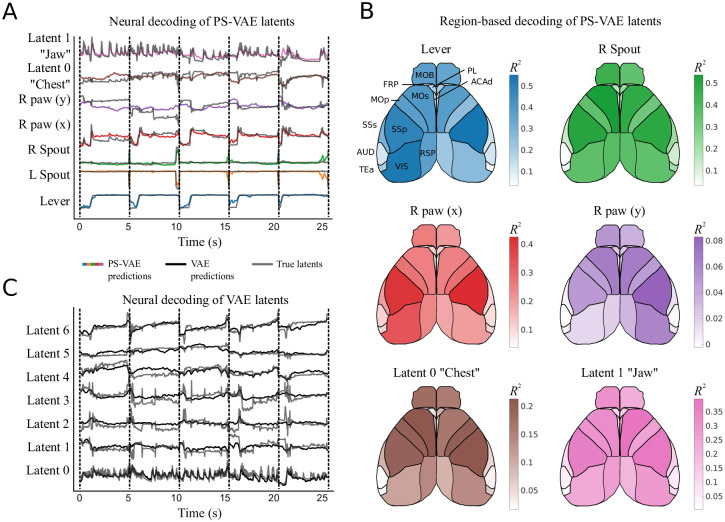
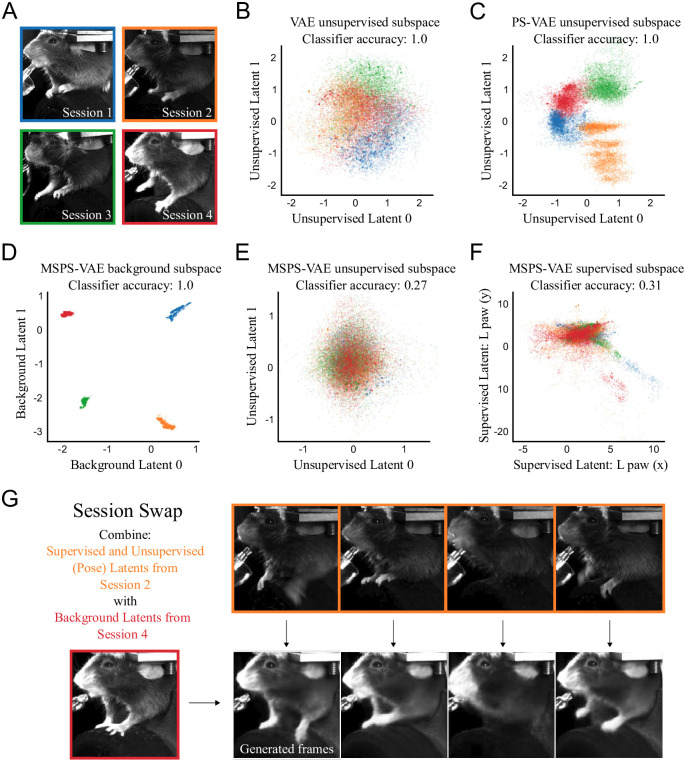
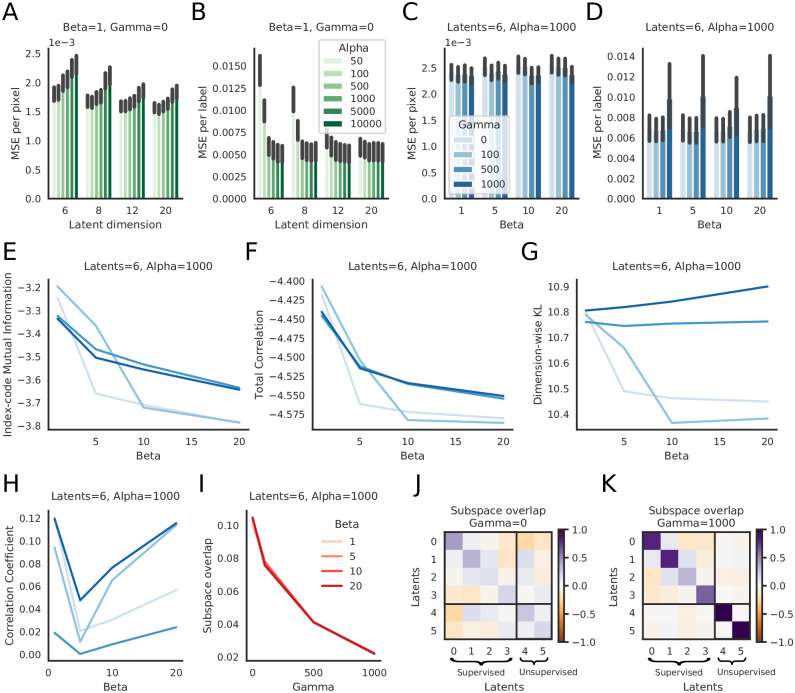
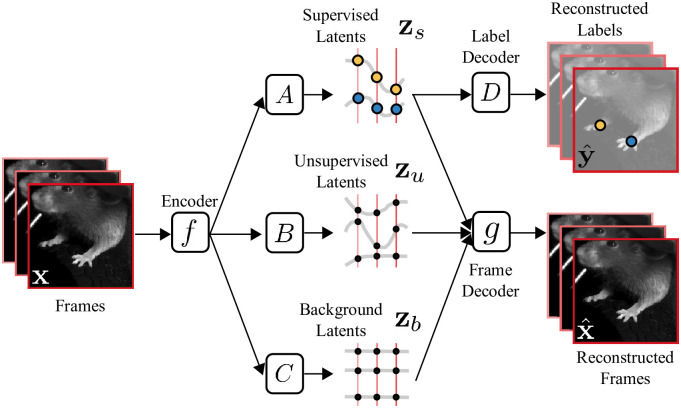
References
Publication types
MeSH terms
Grants and funding
- T32 NS064929/NS/NINDS NIH HHS/United States
- U19 NS104649/NS/NINDS NIH HHS/United States
- UF1 NS107696/NS/NINDS NIH HHS/United States
- 216324/WT_/Wellcome Trust/United Kingdom
- R01 MH082017/MH/NIMH NIH HHS/United States
- R21 MH116348/MH/NIMH NIH HHS/United States
- U19 NS107613/NS/NINDS NIH HHS/United States
- 209558/WT_/Wellcome Trust/United Kingdom
- T32 MH015144/MH/NIMH NIH HHS/United States
- U19 NS123716/NS/NINDS NIH HHS/United States
- 209558/Z/17/Z/WT_/Wellcome Trust/United Kingdom
- RF1 MH120680/MH/NIMH NIH HHS/United States
LinkOut - more resources
Full Text Sources
