

Distance-based clustering challenges for unbiased benchmarking studies
- PMID: 34556686
- PMCID: PMC8460803
- DOI: 10.1038/s41598-021-98126-1
Distance-based clustering challenges for unbiased benchmarking studies
Erratum in
-
Publisher Correction: Distance-based clustering challenges for unbiased benchmarking studies.Sci Rep. 2021 Oct 6;11(1):20245. doi: 10.1038/s41598-021-99687-x. Sci Rep. 2021. PMID: 34615989 Free PMC article. No abstract available.
Abstract
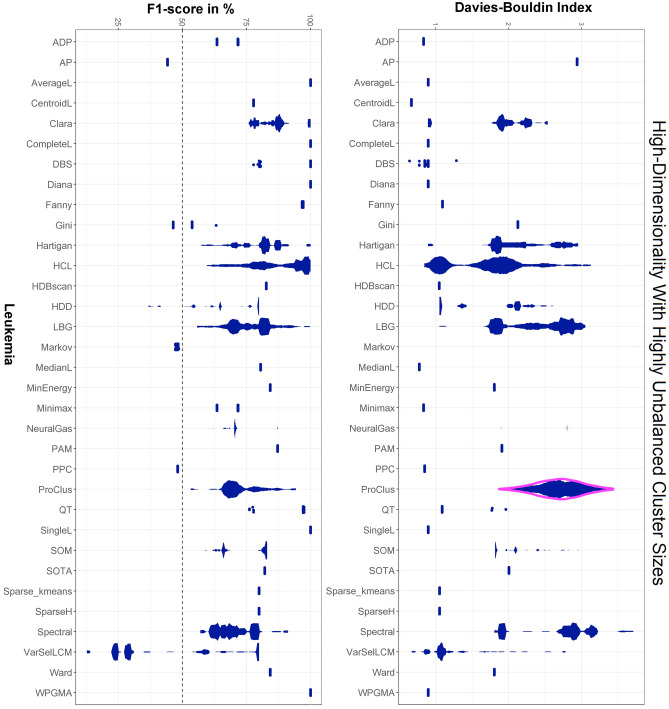
Benchmark datasets with predefined cluster structures and high-dimensional biomedical datasets outline the challenges of cluster analysis: clustering algorithms are limited in their clustering ability in the presence of clusters defining distance-based structures resulting in a biased clustering solution. Data sets might not have cluster structures. Clustering yields arbitrary labels and often depends on the trial, leading to varying results. Moreover, recent research indicated that all partition comparison measures can yield the same results for different clustering solutions. Consequently, algorithm selection and parameter optimization by unsupervised quality measures (QM) are always biased and misleading. Only if the predefined structures happen to meet the particular clustering criterion and QM, can the clusters be recovered. Results are presented based on 41 open-source algorithms which are particularly useful in biomedical scenarios. Furthermore, comparative analysis with mirrored density plots provides a significantly more detailed benchmark than that with the typically used box plots or violin plots.
© 2021. The Author(s).
Conflict of interest statement
The author declares no competing interests.
Figures

References
-
- Fayyad UM, Piatetsky-Shapiro G, Smyth P, Uthurusamy R. Advances in Knowledge Discovery and Data Mining. Menlo Park, CA: American Association for Artificial Intelligence Press; 1996.
-
- Wiwie C, Baumbach J, Röttger R. Comparing the performance of biomedical clustering methods. Nat. Methods. 2015;12:1033. - PubMed
-
- Bonner RE. On some clustering technique. IBM J. Res. Dev. 1964;8:22–32.
Publication types
LinkOut - more resources
Full Text Sources
