

Reinforcement learning modeling reveals a reward-history-dependent strategy underlying reversal learning in squirrel monkeys
- PMID: 34570556
- PMCID: PMC8863624
- DOI: 10.1037/bne0000492
Reinforcement learning modeling reveals a reward-history-dependent strategy underlying reversal learning in squirrel monkeys
Abstract
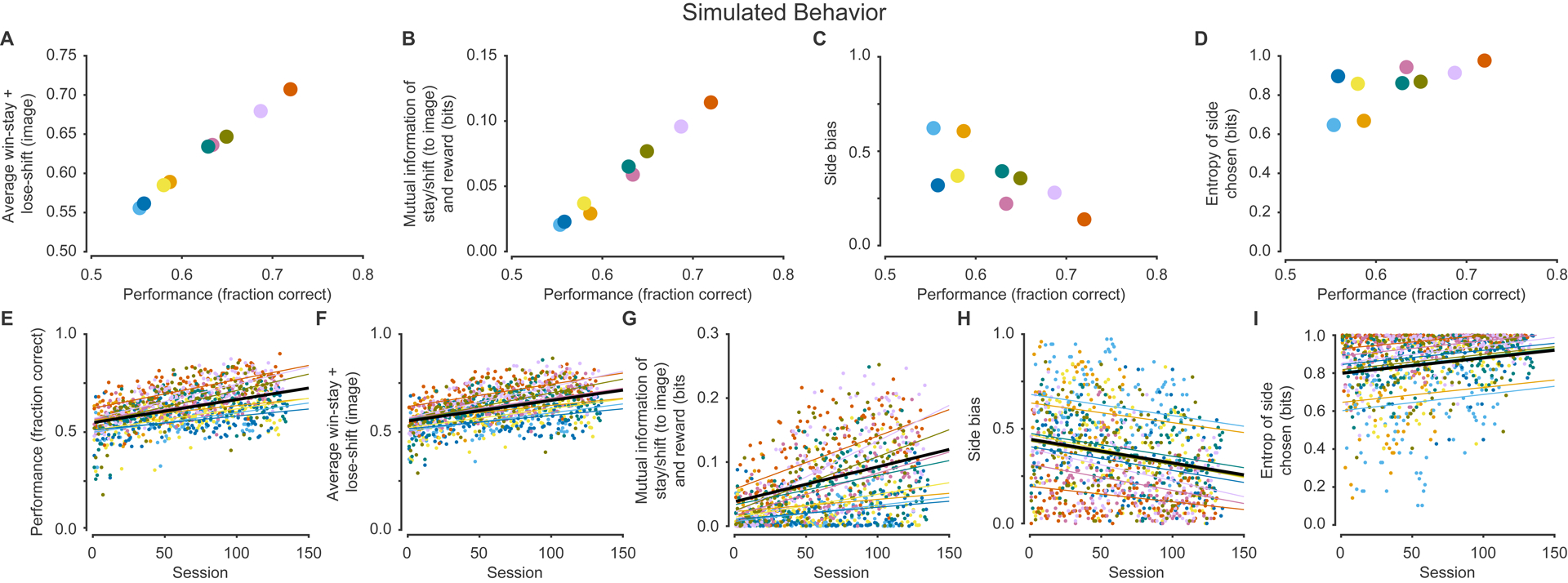
Insight into psychiatric disease and development of therapeutics relies on behavioral tasks that study similar cognitive constructs in multiple species. The reversal learning task is one popular paradigm that probes flexible behavior, aberrations of which are thought to be important in a number of disease states. Despite widespread use, there is a need for a high-throughput primate model that can bridge the genetic, anatomic, and behavioral gap between rodents and humans. Here, we trained squirrel monkeys, a promising preclinical model, on an image-guided deterministic reversal learning task. We found that squirrel monkeys exhibited two key hallmarks of behavior found in other species: integration of reward history over many trials and a side-specific bias. We adapted a reinforcement learning model and demonstrated that it could simulate squirrel monkey-like behavior, capture training-related trajectories, and provide insight into the strategies animals employed. These results validate squirrel monkeys as a model in which to study behavioral flexibility. (PsycInfo Database Record (c) 2022 APA, all rights reserved).
Conflict of interest statement
Figures





References
-
- Abee CR. Squirrel monkey (Saimiri spp.) research and resources. ILAR journal 41: 2–9, 2000. - PubMed
-
- Averbeck BB. Amygdala and ventral striatum population codes implement multiple learning rates for reinforcement learning. In 2017 IEEE Symposium Series on Computational Intelligence (Ssci), pp. 1–5. IEEE, 2017.
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
