

Attention-Based Fault-Tolerant Approach for Multi-Agent Reinforcement Learning Systems
- PMID: 34573757
- PMCID: PMC8469175
- DOI: 10.3390/e23091133
Attention-Based Fault-Tolerant Approach for Multi-Agent Reinforcement Learning Systems
Abstract
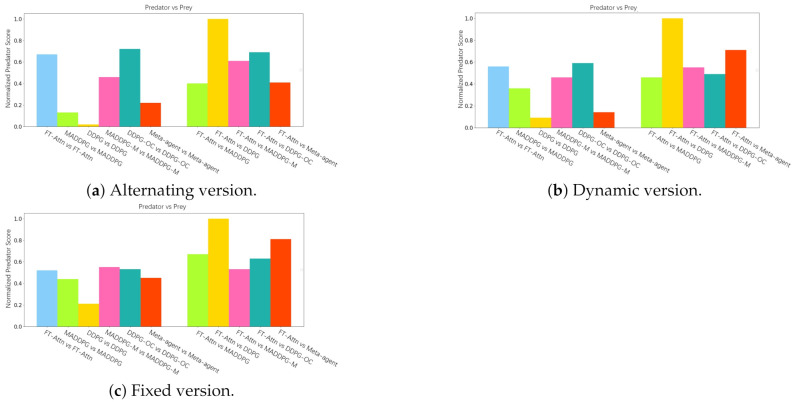
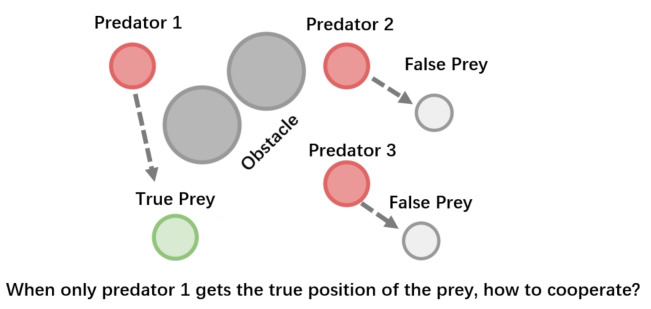
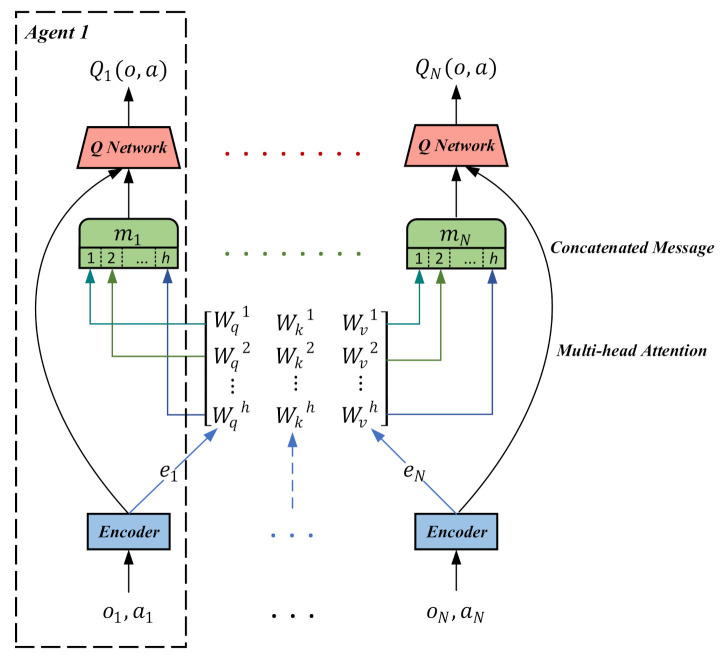
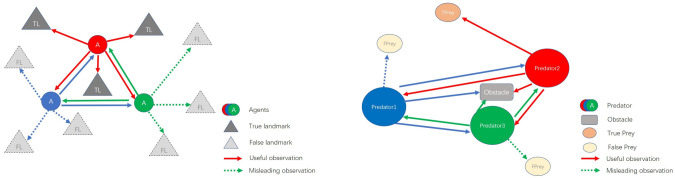
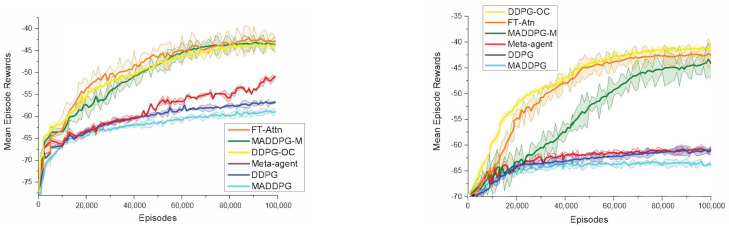
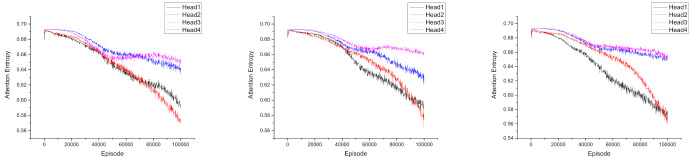
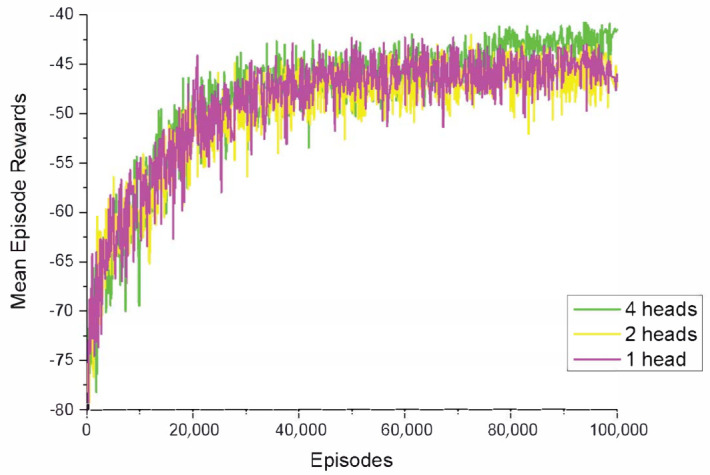
The aim of multi-agent reinforcement learning systems is to provide interacting agents with the ability to collaboratively learn and adapt to the behavior of other agents. Typically, an agent receives its private observations providing a partial view of the true state of the environment. However, in realistic settings, the harsh environment might cause one or more agents to show arbitrarily faulty or malicious behavior, which may suffice to allow the current coordination mechanisms fail. In this paper, we study a practical scenario of multi-agent reinforcement learning systems considering the security issues in the presence of agents with arbitrarily faulty or malicious behavior. The previous state-of-the-art work that coped with extremely noisy environments was designed on the basis that the noise intensity in the environment was known in advance. However, when the noise intensity changes, the existing method has to adjust the configuration of the model to learn in new environments, which limits the practical applications. To overcome these difficulties, we present an Attention-based Fault-Tolerant (FT-Attn) model, which can select not only correct, but also relevant information for each agent at every time step in noisy environments. The multihead attention mechanism enables the agents to learn effective communication policies through experience concurrent with the action policies. Empirical results showed that FT-Attn beats previous state-of-the-art methods in some extremely noisy environments in both cooperative and competitive scenarios, much closer to the upper-bound performance. Furthermore, FT-Attn maintains a more general fault tolerance ability and does not rely on the prior knowledge about the noise intensity of the environment.
Keywords: attention mechanism; fault tolerance; multi-agent; reinforcement learning.
Conflict of interest statement
The authors declare no conflict of interest.
Figures

Similar articles
-
Scalable and Transferable Reinforcement Learning for Multi-Agent Mixed Cooperative-Competitive Environments Based on Hierarchical Graph Attention.Entropy (Basel). 2022 Apr 18;24(4):563. doi: 10.3390/e24040563. Entropy (Basel). 2022. PMID: 35455226 Free PMC article.
-
You Were Always on My Mind: Introducing Chef's Hat and COPPER for Personalized Reinforcement Learning.Front Robot AI. 2021 Jul 16;8:669990. doi: 10.3389/frobt.2021.669990. eCollection 2021. Front Robot AI. 2021. PMID: 34336935 Free PMC article.
-
Investigation of independent reinforcement learning algorithms in multi-agent environments.Front Artif Intell. 2022 Sep 20;5:805823. doi: 10.3389/frai.2022.805823. eCollection 2022. Front Artif Intell. 2022. PMID: 36204598 Free PMC article.
-
Multi-Agent Deep Reinforcement Learning for Multi-Robot Applications: A Survey.Sensors (Basel). 2023 Mar 30;23(7):3625. doi: 10.3390/s23073625. Sensors (Basel). 2023. PMID: 37050685 Free PMC article. Review.
-
Artificial microswimmers get smart.Sci Robot. 2021 Mar 24;6(52):eabh1977. doi: 10.1126/scirobotics.abh1977. Sci Robot. 2021. PMID: 34043556 Review.
Cited by
-
An Improved Approach towards Multi-Agent Pursuit-Evasion Game Decision-Making Using Deep Reinforcement Learning.Entropy (Basel). 2021 Oct 29;23(11):1433. doi: 10.3390/e23111433. Entropy (Basel). 2021. PMID: 34828131 Free PMC article.
References
-
- Geng M., Zhou X., Ding B., Wang H., Zhang L. International Conference on Neural Information Processing. Springer; Cham, Switzerland: 2018. Learning to cooperate in decentralized multirobot exploration of dynamic environments; pp. 40–51.
-
- Higgins F., Tomlinson A., Martin K.M. Survey on security challenges for swarm robotics; Proceedings of the 2009 Fifth International Conference on Autonomic and Autonomous Systems; Valencia, Spain. 20–25 April 2009; pp. 307–312.
-
- Dresner K., Stone P. A multiagent approach to autonomous intersection management. J. Artif. Intell. Res. 2008;31:591–656. doi: 10.1613/jair.2502. - DOI
-
- Pipattanasomporn M., Feroze H., Rahman S. Multi-agent systems in a distributed smart grid: Design and implementation; Proceedings of the 2009 IEEE/PES Power Systems Conference and Exposition; Seattle, WA, USA. 15–18 March 2009; pp. 1–8.
Grants and funding
LinkOut - more resources
Full Text Sources
