

Efficient Reinforcement Learning from Demonstration via Bayesian Network-Based Knowledge Extraction
- PMID: 34603434
- PMCID: PMC8486502
- DOI: 10.1155/2021/7588221
Efficient Reinforcement Learning from Demonstration via Bayesian Network-Based Knowledge Extraction
Abstract
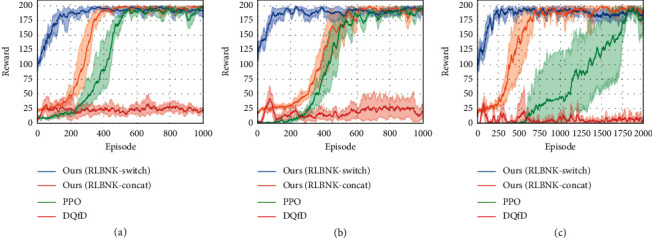
Reinforcement learning from demonstration (RLfD) is considered to be a promising approach to improve reinforcement learning (RL) by leveraging expert demonstrations as the additional decision-making guidance. However, most existing RLfD methods only regard demonstrations as low-level knowledge instances under a certain task. Demonstrations are generally used to either provide additional rewards or pretrain the neural network-based RL policy in a supervised manner, usually resulting in poor generalization capability and weak robustness performance. Considering that human knowledge is not only interpretable but also suitable for generalization, we propose to exploit the potential of demonstrations by extracting knowledge from them via Bayesian networks and develop a novel RLfD method called Reinforcement Learning from demonstration via Bayesian Network-based Knowledge (RLBNK). The proposed RLBNK method takes advantage of node influence with the Wasserstein distance metric (NIW) algorithm to obtain abstract concepts from demonstrations and then a Bayesian network conducts knowledge learning and inference based on the abstract data set, which will yield the coarse policy with corresponding confidence. Once the coarse policy's confidence is low, another RL-based refine module will further optimize and fine-tune the policy to form a (near) optimal hybrid policy. Experimental results show that the proposed RLBNK method improves the learning efficiency of corresponding baseline RL algorithms under both normal and sparse reward settings. Furthermore, we demonstrate that our RLBNK method delivers better generalization capability and robustness than baseline methods.
Copyright © 2021 Yichuan Zhang et al.
Conflict of interest statement
The authors declare that they have no conflicts of interest.
Figures










Similar articles
-
A reinforcement learning algorithm acquires demonstration from the training agent by dividing the task space.Neural Netw. 2023 Jul;164:419-427. doi: 10.1016/j.neunet.2023.04.042. Epub 2023 May 5. Neural Netw. 2023. PMID: 37187108
-
Inverse reinforcement learning for intelligent mechanical ventilation and sedative dosing in intensive care units.BMC Med Inform Decis Mak. 2019 Apr 9;19(Suppl 2):57. doi: 10.1186/s12911-019-0763-6. BMC Med Inform Decis Mak. 2019. PMID: 30961594 Free PMC article.
-
Novelty and Inductive Generalization in Human Reinforcement Learning.Top Cogn Sci. 2015 Jul;7(3):391-415. doi: 10.1111/tops.12138. Epub 2015 Mar 23. Top Cogn Sci. 2015. PMID: 25808176 Free PMC article.
-
Exploration in neo-Hebbian reinforcement learning: Computational approaches to the exploration-exploitation balance with bio-inspired neural networks.Neural Netw. 2022 Jul;151:16-33. doi: 10.1016/j.neunet.2022.03.021. Epub 2022 Mar 23. Neural Netw. 2022. PMID: 35367735 Review.
-
Reinforcement Learning in Neurocritical and Neurosurgical Care: Principles and Possible Applications.Comput Math Methods Med. 2021 Feb 22;2021:6657119. doi: 10.1155/2021/6657119. eCollection 2021. Comput Math Methods Med. 2021. PMID: 33680069 Free PMC article. Review.
Cited by
-
An Ensemble Learning Method Based on an Evidential Reasoning Rule considering Combination Weighting.Comput Intell Neurosci. 2022 Mar 7;2022:1156748. doi: 10.1155/2022/1156748. eCollection 2022. Comput Intell Neurosci. 2022. PMID: 35295274 Free PMC article.
-
An Efficient Data Classification Decision Based on Multimodel Deep Learning.Comput Intell Neurosci. 2022 May 4;2022:7636705. doi: 10.1155/2022/7636705. eCollection 2022. Comput Intell Neurosci. 2022. PMID: 35571693 Free PMC article.
References
-
- Carta S., Corriga A., Ferreira A., Podda A. S., Recupero D. R. A multi-layer and multi-ensemble stock trader using deep learning and deep reinforcement learning. Applied Intelligence . 2021;51(2):889–905. doi: 10.1007/s10489-020-01839-5. - DOI
-
- Zhao X., Zhang L., Ding Z., Xia L., Tang J., Yin D. Recommendations with negative feedback via pairwise deep reinforcement learning. In: Guo Y., Farooq F., editors. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2018; August 2018; London, UK. ACM; pp. 1040–1048. - DOI
-
- Schaal S. Learning from demonstration. In: Mozer M., Jordan M. I., Petsche T., editors. Proceedings of the Advances in Neural Information Processing Systems 9, NIPS; December 1996; Denver, CO, USA. MIT Press; pp. 1040–1046.
-
- Vecerík M., Hester T., Scholz J., et al. Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards. 2017. http://arxiv.org/abs/1707.08817 .
MeSH terms
LinkOut - more resources
Full Text Sources
