

Integrating Domain Knowledge Into Deep Networks for Lung Ultrasound With Applications to COVID-19
- PMID: 34606447
- PMCID: PMC9014480
- DOI: 10.1109/TMI.2021.3117246
Integrating Domain Knowledge Into Deep Networks for Lung Ultrasound With Applications to COVID-19
Abstract
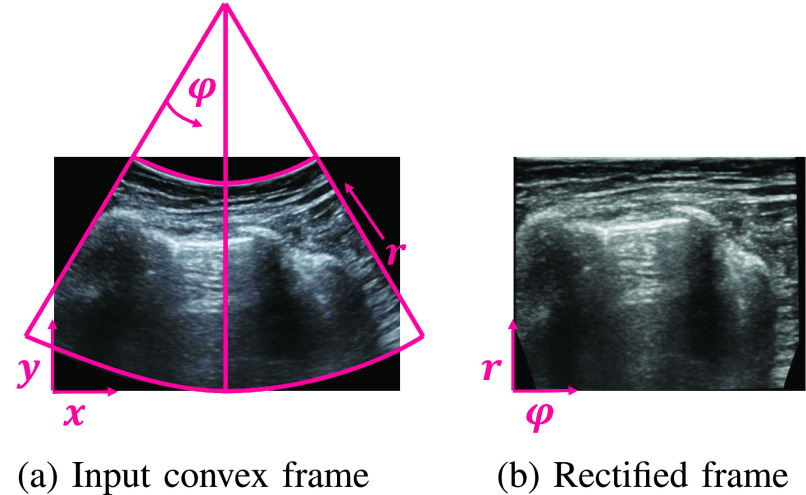
Lung ultrasound (LUS) is a cheap, safe and non-invasive imaging modality that can be performed at patient bed-side. However, to date LUS is not widely adopted due to lack of trained personnel required for interpreting the acquired LUS frames. In this work we propose a framework for training deep artificial neural networks for interpreting LUS, which may promote broader use of LUS. When using LUS to evaluate a patient's condition, both anatomical phenomena (e.g., the pleural line, presence of consolidations), as well as sonographic artifacts (such as A- and B-lines) are of importance. In our framework, we integrate domain knowledge into deep neural networks by inputting anatomical features and LUS artifacts in the form of additional channels containing pleural and vertical artifacts masks along with the raw LUS frames. By explicitly supplying this domain knowledge, standard off-the-shelf neural networks can be rapidly and efficiently finetuned to accomplish various tasks on LUS data, such as frame classification or semantic segmentation. Our framework allows for a unified treatment of LUS frames captured by either convex or linear probes. We evaluated our proposed framework on the task of COVID-19 severity assessment using the ICLUS dataset. In particular, we finetuned simple image classification models to predict per-frame COVID-19 severity score. We also trained a semantic segmentation model to predict per-pixel COVID-19 severity annotations. Using the combined raw LUS frames and the detected lines for both tasks, our off-the-shelf models performed better than complicated models specifically designed for these tasks, exemplifying the efficacy of our framework.
Figures







References
-
- Lichtenstein D., Goldstein I., Mourgeon E., Cluzel P., Grenier P., and Rouby J.-J., “Comparative diagnostic performances of auscultation, chest radiography, and lung ultrasonography in acute respiratory distress syndrome,” J. Amer. Soc. Anesthesiol., vol. 100, no. 1, pp. 9–15, 2004. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
