

Image-based shading correction for narrow-FOV truncated pelvic CBCT with deep convolutional neural networks and transfer learning
- PMID: 34636429
- PMCID: PMC9297981
- DOI: 10.1002/mp.15282
Image-based shading correction for narrow-FOV truncated pelvic CBCT with deep convolutional neural networks and transfer learning
Abstract
Purpose: Cone beam computed tomography (CBCT) is a standard solution for in-room image guidance for radiation therapy. It is used to evaluate and compensate for anatomopathological changes between the dose delivery plan and the fraction delivery day. CBCT is a fast and versatile solution, but it suffers from drawbacks like low contrast and requires proper calibration to derive density values. Although these limitations are even more prominent with in-room customized CBCT systems, strategies based on deep learning have shown potential in improving image quality. As such, this article presents a method based on a convolutional neural network and a novel two-step supervised training based on the transfer learning paradigm for shading correction in CBCT volumes with narrow field of view (FOV) acquired with an ad hoc in-room system.
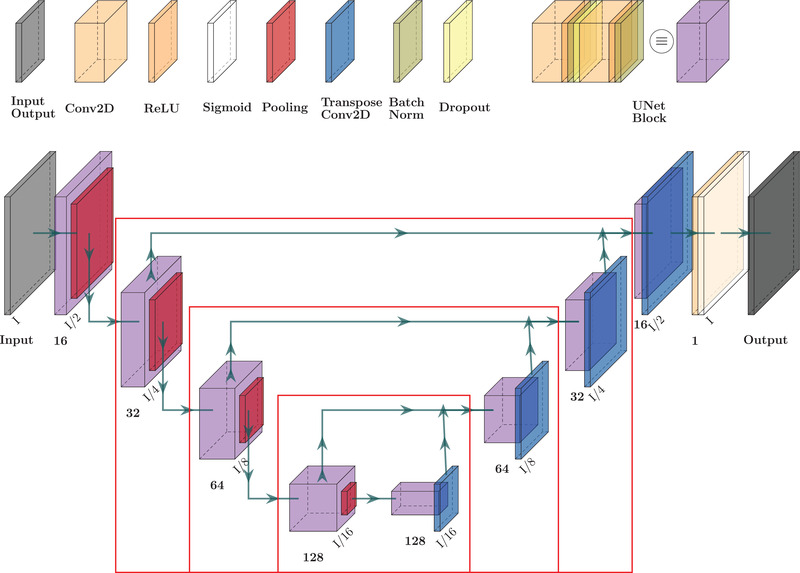
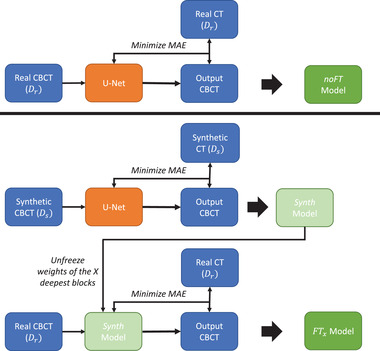
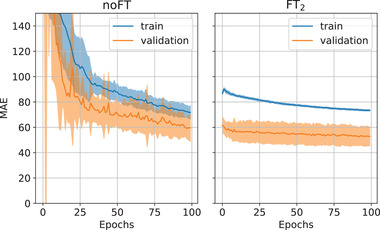
Methods: We designed a U-Net convolutional neural network, trained on axial slices of corresponding CT/CBCT couples. To improve the generalization capability of the network, we exploited two-stage learning using two distinct data sets. At first, the network weights were trained using synthetic CBCT scans generated from a public data set, and then only the deepest layers of the network were trained again with real-world clinical data to fine-tune the weights. Synthetic data were generated according to real data acquisition parameters. The network takes a single grayscale volume as input and outputs the same volume with corrected shading and improved HU values.
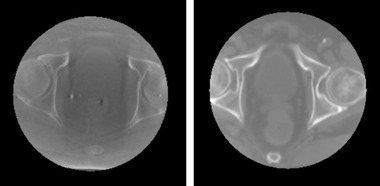
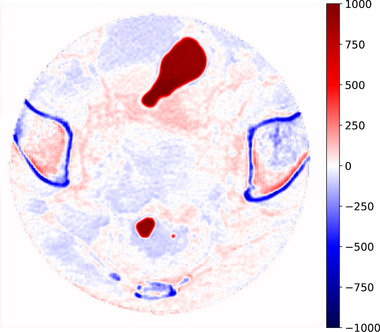
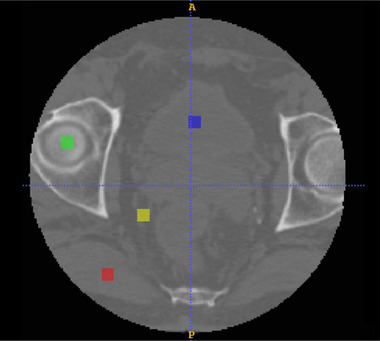
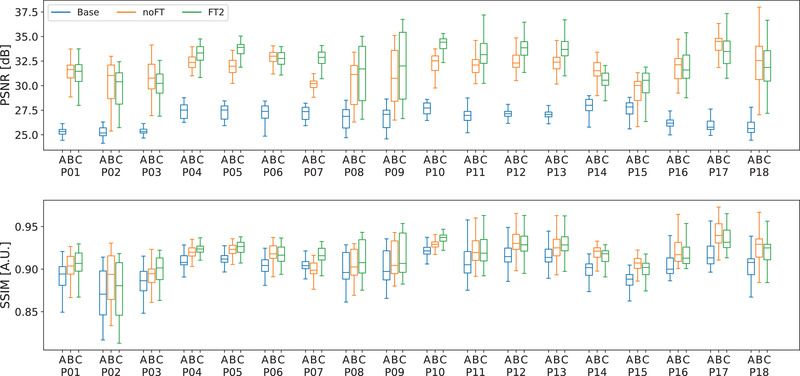
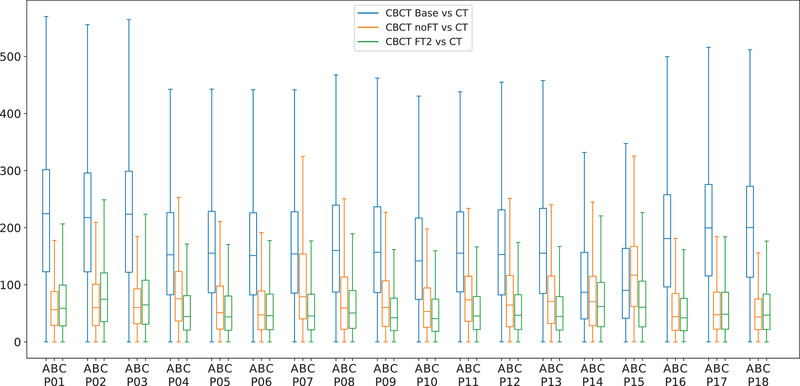
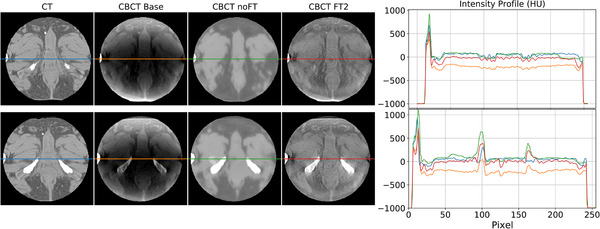
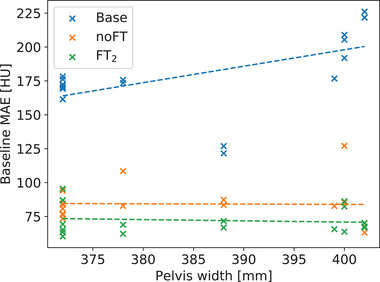
Results: Evaluation was carried out with a leave-one-out cross-validation, computed on 18 unique CT/CBCT pairs from six different patients from a real-world dataset. Comparing original CBCT to CT and improved CBCT to CT, we obtained an average improvement of 6 dB on peak signal-to-noise ratio (PSNR), +2% on structural similarity index measure (SSIM). The median interquartile range (IQR) Hounsfield unit (HU) difference between CBCT and CT improved from 161.37 (162.54) HU to 49.41 (66.70) HU. Region of interest (ROI)-based HU difference was narrowed by 75% in the spongy bone (femoral head), 89% in the bladder, 85% for fat, and 83% for muscle. The improvement in contrast-to-noise ratio for these ROIs was about 67%.
Conclusions: We demonstrated that shading correction obtaining CT-compatible data from narrow-FOV CBCTs acquired with a customized in-room system is possible. Moreover, the transfer learning approach proved particularly beneficial for such a shading correction approach.
Keywords: Hounsfield unit recovery; cone beam CT; deep learning; limited FOV; shading correction; transfer learning.
© 2021 The Authors. Medical Physics published by Wiley Periodicals LLC on behalf of American Association of Physicists in Medicine.
Conflict of interest statement
The authors have no relevant conflicts of interest to disclose.
Figures

References
-
- Fattori G, Riboldi M, Pella A, et al.. Image guided particle therapy in CNAO room 2: implementation and clinical validation. Physica Medica. 2015;31:9–15. - PubMed
-
- Veiga C, Janssens G, Teng CL, et al.. First clinical investigation of cone beam computed tomography and deformable registration for adaptive proton therapy for lung cancer. Int J Radiat Oncol Biol Phys. 2016;95:549–559. - PubMed
-
- Landry G, Hua CH. Current state and future applications of radiological image guidance for particle therapy. Med Phys. 2018;45:e1086–e1095. - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials
Miscellaneous
