

Scaling up DNA digital data storage by efficiently predicting DNA hybridisation using deep learning
- PMID: 34654863
- PMCID: PMC8519920
- DOI: 10.1038/s41598-021-97238-y
Scaling up DNA digital data storage by efficiently predicting DNA hybridisation using deep learning
Abstract
Deoxyribonucleic acid (DNA) has shown great promise in enabling computational applications, most notably in the fields of DNA digital data storage and DNA computing. Information is encoded as DNA strands, which will naturally bind in solution, thus enabling search and pattern-matching capabilities. Being able to control and predict the process of DNA hybridisation is crucial for the ambitious future of Hybrid Molecular-Electronic Computing. Current tools are, however, limited in terms of throughput and applicability to large-scale problems. We present the first comprehensive study of machine learning methods applied to the task of predicting DNA hybridisation. For this purpose, we introduce an in silico-generated hybridisation dataset of over 2.5 million data points, enabling the use of deep learning. Depending on hardware, we achieve a reduction in inference time ranging from one to over two orders of magnitude compared to the state-of-the-art, while retaining high fidelity. We then discuss the integration of our methods in modern, scalable workflows.
© 2021. The Author(s).
Conflict of interest statement
The author declares no competing interests.
Figures
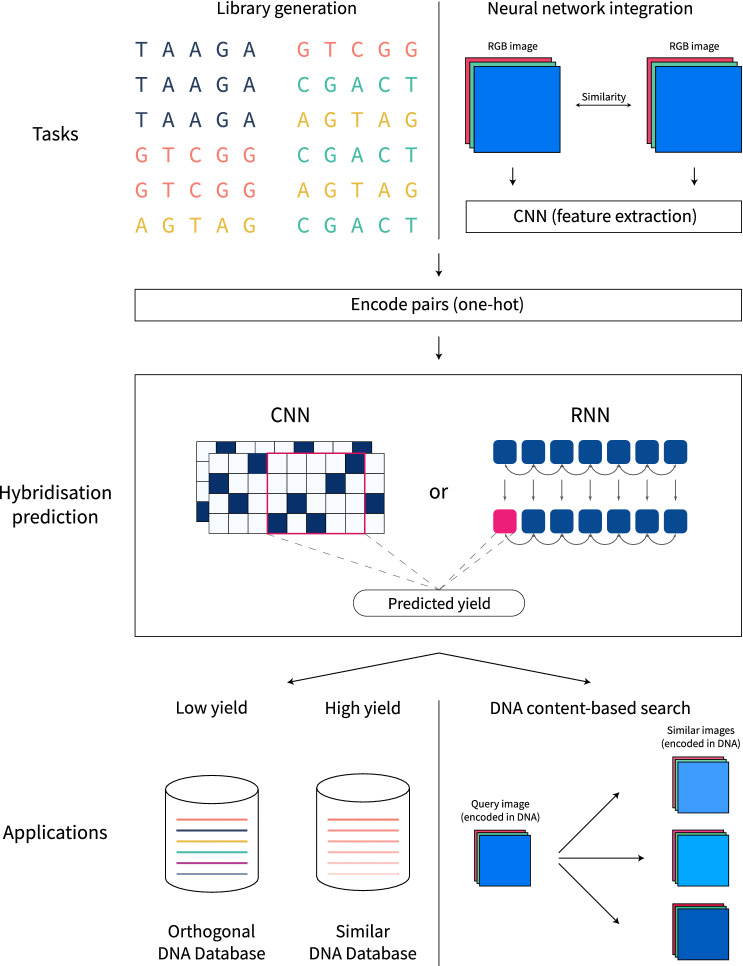
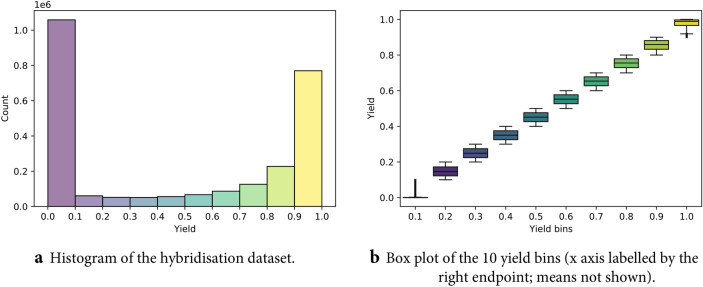
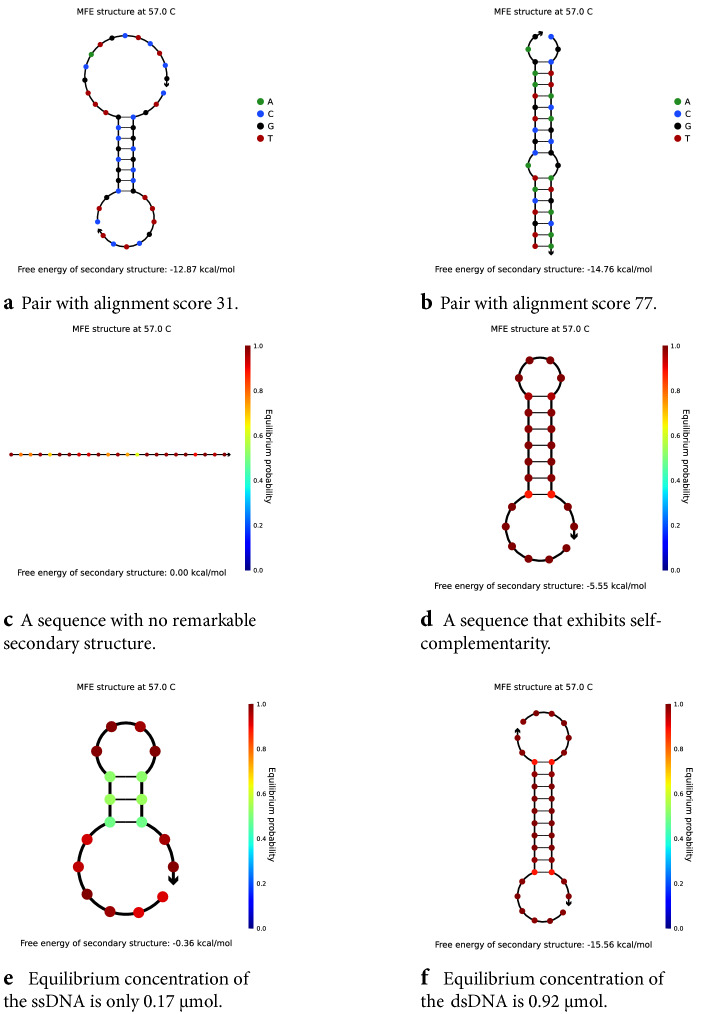
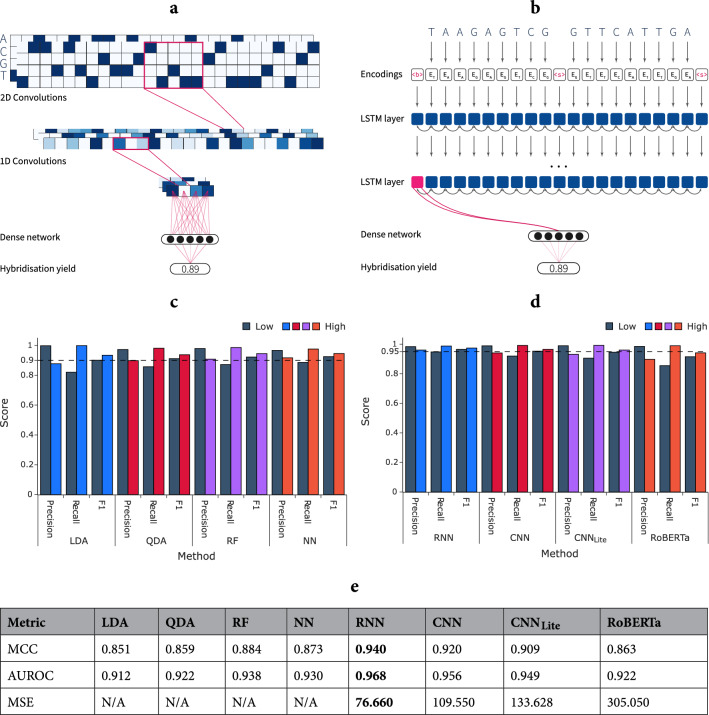
References
-
- Reinsel, D., Gantz, J. & Rydning, J. The Digitization of the World From Edge to Core tech. rep. (2018). https://www.seagate.com/files/www-content/our-story/trends/files/idc-sea.... Accessed 1 June 2019.
-
- Carmean D, et al. DNA data storage and hybrid molecular-electronic computing. Proc. IEEE. 2019;107:63–72. doi: 10.1109/JPROC.2018.2875386. - DOI
-
- Grass, R. N., Heckel, R., Puddu, M., Paunescu, D. & Stark, W. J. Robust chemical preservation of digital information on DNA in silica with error-correcting codes. Angewandte Chemie - International Edition. ISSN: 15213773 (2015). - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
