

This is a preprint.
Deep learning models for predicting RNA degradation via dual crowdsourcing
- PMID: 34671698
- PMCID: PMC8528079
Deep learning models for predicting RNA degradation via dual crowdsourcing
Update in
-
Deep learning models for predicting RNA degradation via dual crowdsourcing.Nat Mach Intell. 2022;4(12):1174-1184. doi: 10.1038/s42256-022-00571-8. Epub 2022 Dec 14. Nat Mach Intell. 2022. PMID: 36567960 Free PMC article.
Abstract
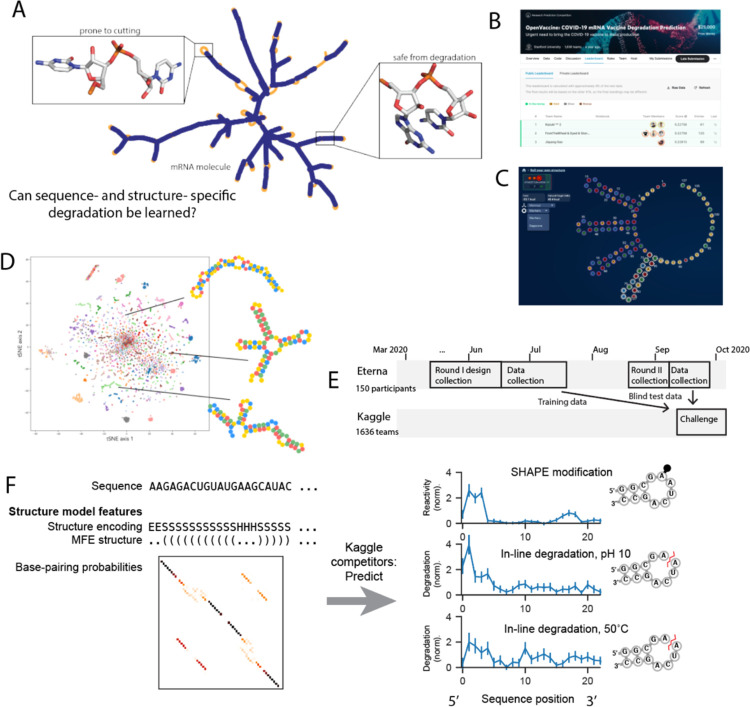
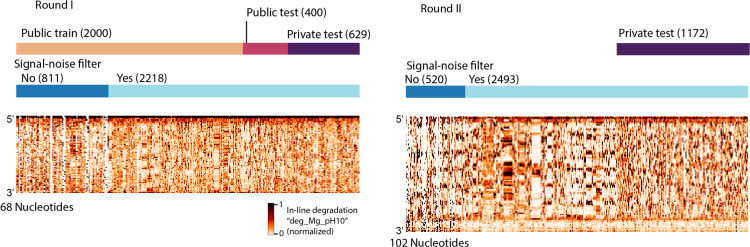
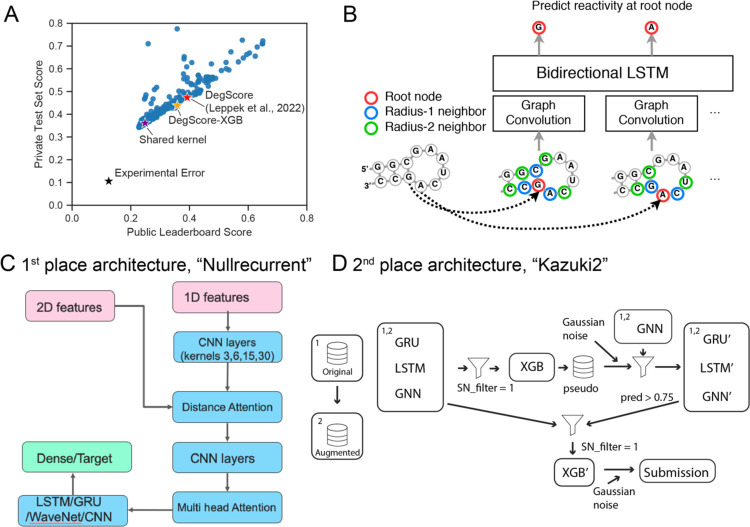
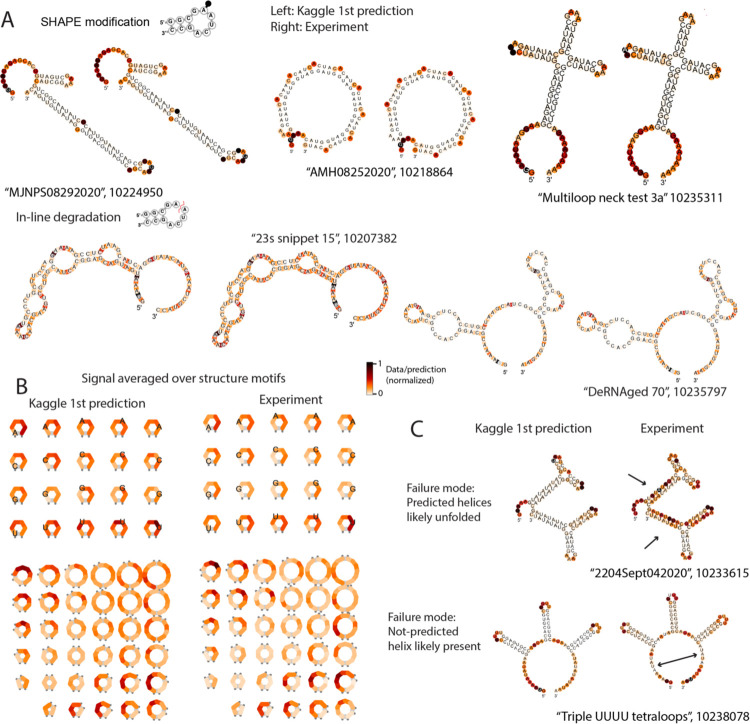
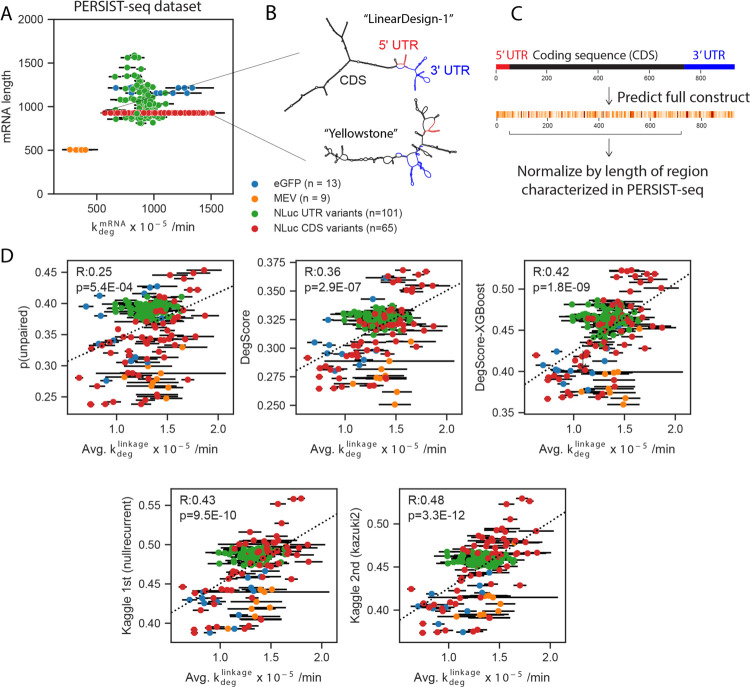
Messenger RNA-based medicines hold immense potential, as evidenced by their rapid deployment as COVID-19 vaccines. However, worldwide distribution of mRNA molecules has been limited by their thermostability, which is fundamentally limited by the intrinsic instability of RNA molecules to a chemical degradation reaction called in-line hydrolysis. Predicting the degradation of an RNA molecule is a key task in designing more stable RNA-based therapeutics. Here, we describe a crowdsourced machine learning competition ("Stanford OpenVaccine") on Kaggle, involving single-nucleotide resolution measurements on 6043 102-130-nucleotide diverse RNA constructs that were themselves solicited through crowdsourcing on the RNA design platform Eterna. The entire experiment was completed in less than 6 months, and 41% of nucleotide-level predictions from the winning model were within experimental error of the ground truth measurement. Furthermore, these models generalized to blindly predicting orthogonal degradation data on much longer mRNA molecules (504-1588 nucleotides) with improved accuracy compared to previously published models. Top teams integrated natural language processing architectures and data augmentation techniques with predictions from previous dynamic programming models for RNA secondary structure. These results indicate that such models are capable of representing in-line hydrolysis with excellent accuracy, supporting their use for designing stabilized messenger RNAs. The integration of two crowdsourcing platforms, one for data set creation and another for machine learning, may be fruitful for other urgent problems that demand scientific discovery on rapid timescales.
Conflict of interest statement
Figures
Similar articles
-
Deep learning models for predicting RNA degradation via dual crowdsourcing.Nat Mach Intell. 2022;4(12):1174-1184. doi: 10.1038/s42256-022-00571-8. Epub 2022 Dec 14. Nat Mach Intell. 2022. PMID: 36567960 Free PMC article.
-
RNAdegformer: accurate prediction of mRNA degradation at nucleotide resolution with deep learning.Brief Bioinform. 2023 Jan 19;24(1):bbac581. doi: 10.1093/bib/bbac581. Brief Bioinform. 2023. PMID: 36633966 Free PMC article.
-
Ribonanza: deep learning of RNA structure through dual crowdsourcing.bioRxiv [Preprint]. 2024 Jun 11:2024.02.24.581671. doi: 10.1101/2024.02.24.581671. bioRxiv. 2024. PMID: 38464325 Free PMC article. Preprint.
-
RNA-targeted small-molecule drug discoveries: a machine-learning perspective.RNA Biol. 2023 Jan;20(1):384-397. doi: 10.1080/15476286.2023.2223498. RNA Biol. 2023. PMID: 37337437 Free PMC article. Review.
-
Concepts and methods for transcriptome-wide prediction of chemical messenger RNA modifications with machine learning.Brief Bioinform. 2023 May 19;24(3):bbad163. doi: 10.1093/bib/bbad163. Brief Bioinform. 2023. PMID: 37139545 Free PMC article. Review.
References
-
- Kramps T. & Elbers K. in Methods Mol Biol, Vol. 1499, Edn. 2016/12/18 1–11 (2017). - PubMed
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources