

Comprehensive discovery of CRISPR-targeted terminally redundant sequences in the human gut metagenome: Viruses, plasmids, and more
- PMID: 34673779
- PMCID: PMC8530359
- DOI: 10.1371/journal.pcbi.1009428
Comprehensive discovery of CRISPR-targeted terminally redundant sequences in the human gut metagenome: Viruses, plasmids, and more
Abstract
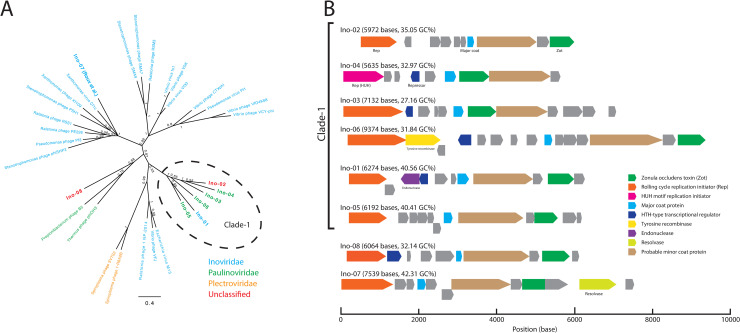
Viruses are the most numerous biological entity, existing in all environments and infecting all cellular organisms. Compared with cellular life, the evolution and origin of viruses are poorly understood; viruses are enormously diverse, and most lack sequence similarity to cellular genes. To uncover viral sequences without relying on either reference viral sequences from databases or marker genes that characterize specific viral taxa, we developed an analysis pipeline for virus inference based on clustered regularly interspaced short palindromic repeats (CRISPR). CRISPR is a prokaryotic nucleic acid restriction system that stores the memory of previous exposure. Our protocol can infer CRISPR-targeted sequences, including viruses, plasmids, and previously uncharacterized elements, and predict their hosts using unassembled short-read metagenomic sequencing data. By analyzing human gut metagenomic data, we extracted 11,391 terminally redundant CRISPR-targeted sequences, which are likely complete circular genomes. The sequences included 2,154 tailed-phage genomes, together with 257 complete crAssphage genomes, 11 genomes larger than 200 kilobases, 766 genomes of Microviridae species, 56 genomes of Inoviridae species, and 95 previously uncharacterized circular small genomes that have no reliably predicted protein-coding gene. We predicted the host(s) of approximately 70% of the discovered genomes at the taxonomic level of phylum by linking protospacers to taxonomically assigned CRISPR direct repeats. These results demonstrate that our protocol is efficient for de novo inference of CRISPR-targeted sequences and their host prediction.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures





References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
