

The learning of prospective and retrospective cognitive maps within neural circuits
- PMID: 34678148
- PMCID: PMC8809184
- DOI: 10.1016/j.neuron.2021.09.034
The learning of prospective and retrospective cognitive maps within neural circuits
Abstract
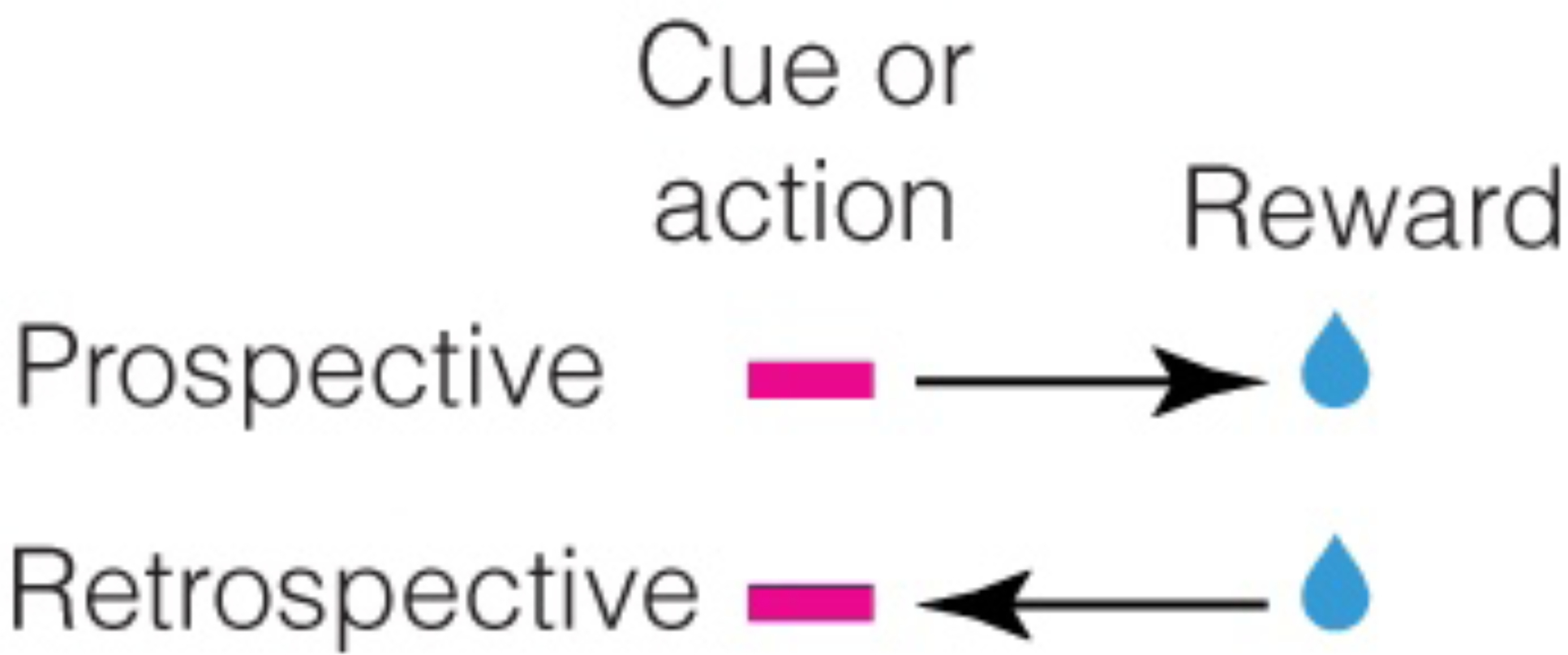
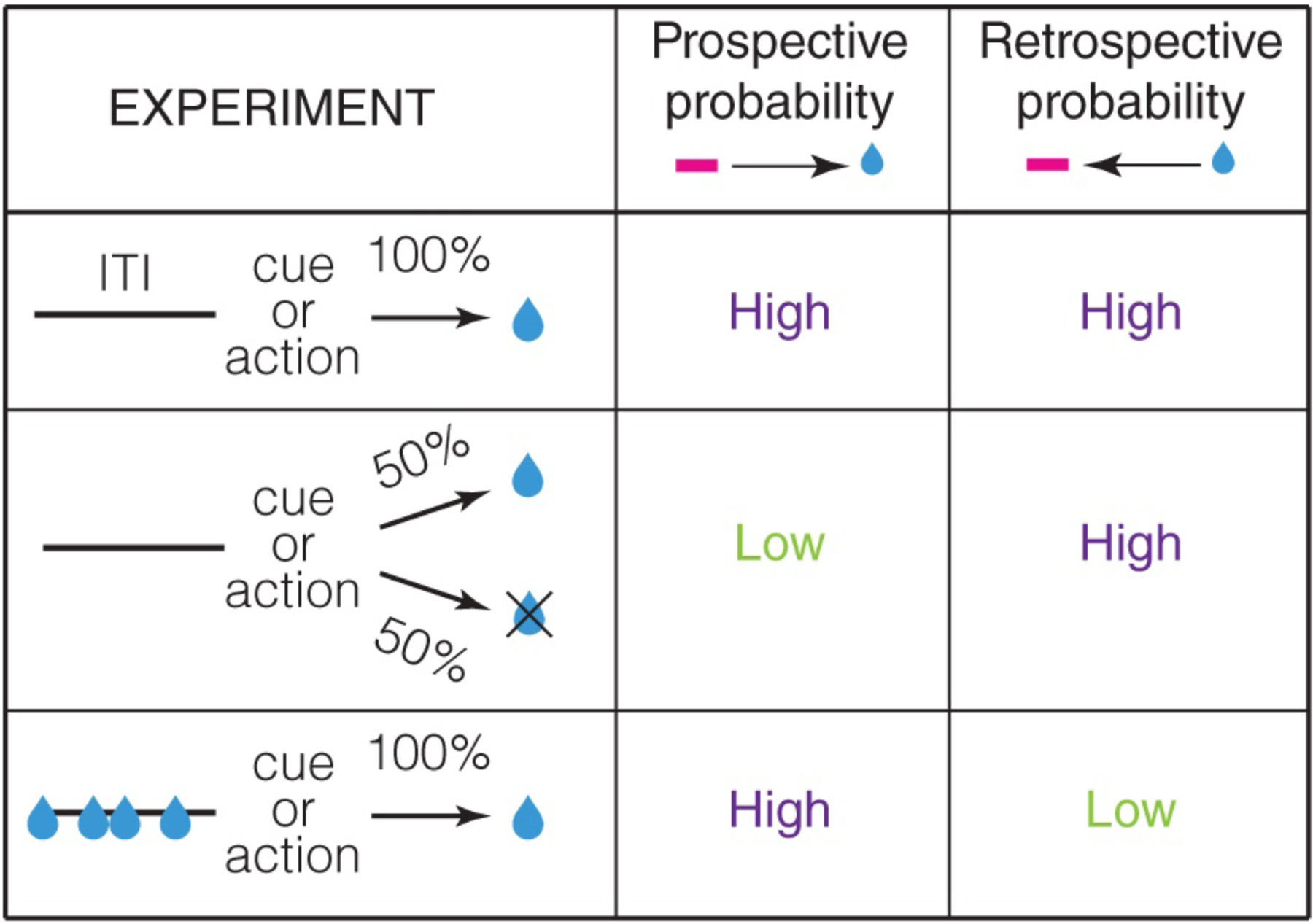
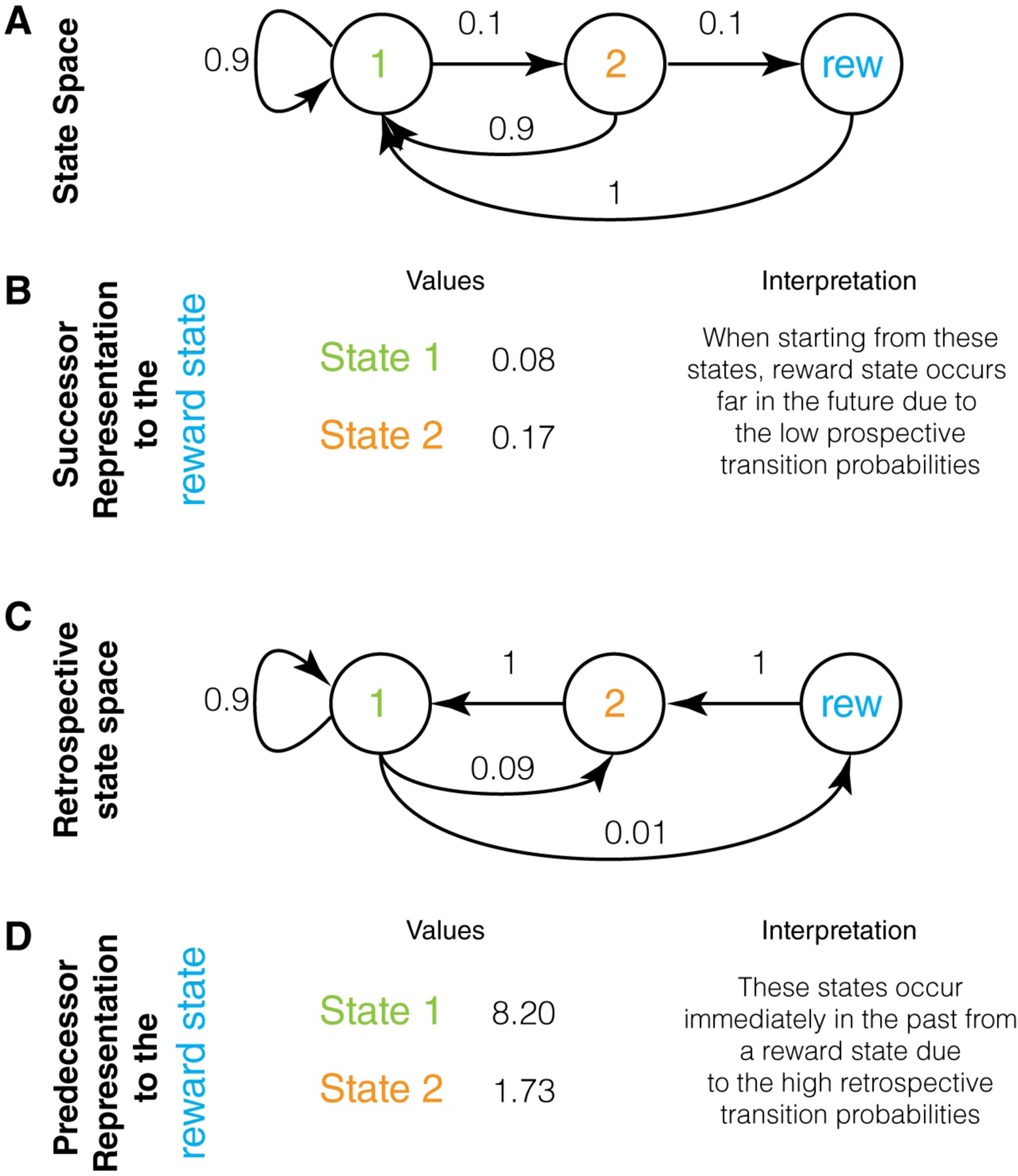
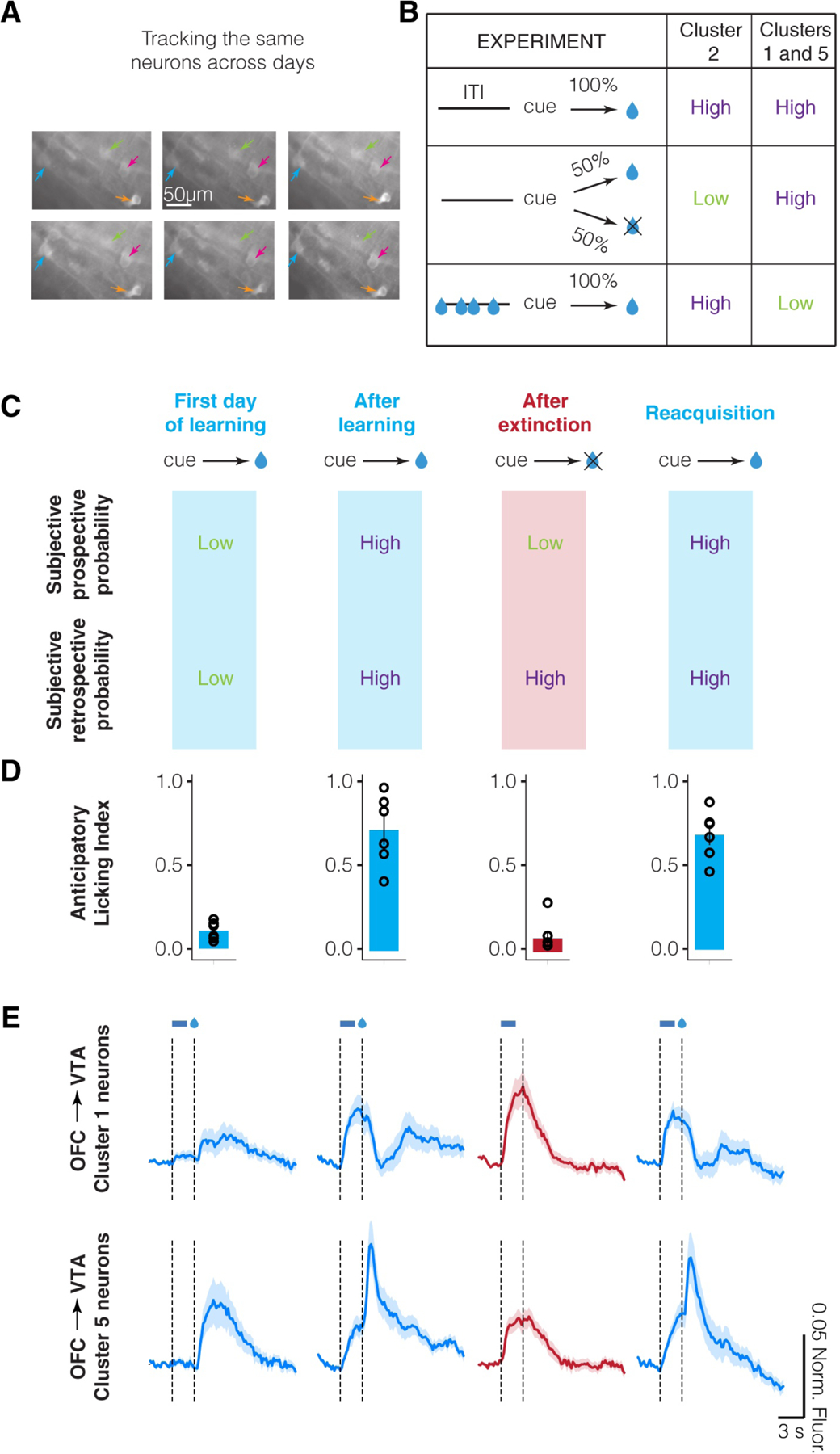
Brain circuits are thought to form a "cognitive map" to process and store statistical relationships in the environment. A cognitive map is commonly defined as a mental representation that describes environmental states (i.e., variables or events) and the relationship between these states. This process is commonly conceptualized as a prospective process, as it is based on the relationships between states in chronological order (e.g., does reward follow a given state?). In this perspective, we expand this concept on the basis of recent findings to postulate that in addition to a prospective map, the brain forms and uses a retrospective cognitive map (e.g., does a given state precede reward?). In doing so, we demonstrate that many neural signals and behaviors (e.g., habits) that seem inflexible and non-cognitive can result from retrospective cognitive maps. Together, we present a significant conceptual reframing of the neurobiological study of associative learning, memory, and decision making.
Copyright © 2021. Published by Elsevier Inc.
Figures
Similar articles
-
Cognitive strategies regulate fictive, but not reward prediction error signals in a sequential investment task.Hum Brain Mapp. 2014 Aug;35(8):3738-49. doi: 10.1002/hbm.22433. Epub 2013 Dec 31. Hum Brain Mapp. 2014. PMID: 24382784 Free PMC article.
-
The roles of valuation and reward processing in cognitive function and psychiatric disorders.Ann N Y Acad Sci. 2017 May;1395(1):33-48. doi: 10.1111/nyas.13327. Epub 2017 Apr 17. Ann N Y Acad Sci. 2017. PMID: 28415138 Free PMC article. Review.
-
Cognition and Reward Circuits in Schizophrenia: Synergistic, Not Separate.Biol Psychiatry. 2020 Feb 1;87(3):204-214. doi: 10.1016/j.biopsych.2019.09.021. Epub 2019 Oct 3. Biol Psychiatry. 2020. PMID: 31733788 Free PMC article. Review.
-
Hippocampal spatio-predictive cognitive maps adaptively guide reward generalization.Nat Neurosci. 2023 Apr;26(4):615-626. doi: 10.1038/s41593-023-01283-x. Epub 2023 Apr 3. Nat Neurosci. 2023. PMID: 37012381 Free PMC article.
-
Cognitive flexibility in adolescence: neural and behavioral mechanisms of reward prediction error processing in adaptive decision making during development.Neuroimage. 2015 Jan 1;104:347-54. doi: 10.1016/j.neuroimage.2014.09.018. Epub 2014 Sep 16. Neuroimage. 2015. PMID: 25234119 Free PMC article.
Cited by
-
Sensory cortical ensembles exhibit differential coupling to ripples in distinct hippocampal subregions.bioRxiv [Preprint]. 2023 Mar 18:2023.03.17.533028. doi: 10.1101/2023.03.17.533028. bioRxiv. 2023. Update in: Curr Biol. 2023 Dec 4;33(23):5185-5198.e4. doi: 10.1016/j.cub.2023.10.073. PMID: 36993665 Free PMC article. Updated. Preprint.
-
Mesolimbic dopamine release conveys causal associations.Science. 2022 Dec 23;378(6626):eabq6740. doi: 10.1126/science.abq6740. Epub 2022 Dec 23. Science. 2022. PMID: 36480599 Free PMC article.
-
Noise Resilience of Successor and Predecessor Feature Algorithms in One- and Two-Dimensional Environments.Sensors (Basel). 2025 Feb 6;25(3):979. doi: 10.3390/s25030979. Sensors (Basel). 2025. PMID: 39943618 Free PMC article.
-
Humans adaptively deploy forward and backward prediction.Nat Hum Behav. 2024 Sep;8(9):1726-1737. doi: 10.1038/s41562-024-01930-8. Epub 2024 Jul 16. Nat Hum Behav. 2024. PMID: 39014069 Free PMC article.
-
Learning temporal relationships between symbols with Laplace Neural Manifolds.ArXiv [Preprint]. 2024 Sep 22:arXiv:2302.10163v4. ArXiv. 2024. PMID: 36866224 Free PMC article. Preprint.
References
-
- Abramson CI (2009). A Study in Inspiration: Charles Henry Turner (1867–1923) and the Investigation of Insect Behavior. Annual Review of Entomology 54, 343–359. - PubMed
-
- Adams CD (1982). Variations in the sensitivity of instrumental responding to reinforcer devaluation. The Quarterly Journal of Experimental Psychology Section B 34, 77–98.
-
- Afsardeir A, and Keramati M (2018). Behavioural signatures of backward planning in animals. Eur J Neurosci 47, 479–487. - PubMed
