

Obstacle Detection Using a Facet-Based Representation from 3-D LiDAR Measurements
- PMID: 34696073
- PMCID: PMC8539039
- DOI: 10.3390/s21206861
Obstacle Detection Using a Facet-Based Representation from 3-D LiDAR Measurements
Abstract
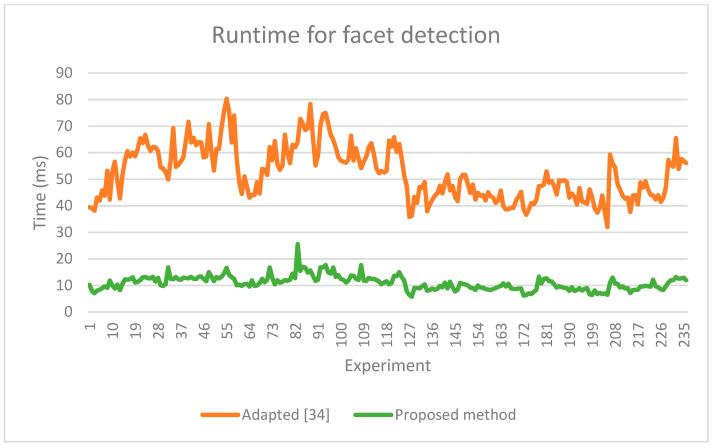
In this paper, we propose an obstacle detection approach that uses a facet-based obstacle representation. The approach has three main steps: ground point detection, clustering of obstacle points, and facet extraction. Measurements from a 64-layer LiDAR are used as input. First, ground points are detected and eliminated in order to select obstacle points and create object instances. To determine the objects, obstacle points are grouped using a channel-based clustering approach. For each object instance, its contour is extracted and, using an RANSAC-based approach, the obstacle facets are selected. For each processing stage, optimizations are proposed in order to obtain a better runtime. For the evaluation, we compare our proposed approach with an existing approach, using the KITTI benchmark dataset. The proposed approach has similar or better results for some obstacle categories but a lower computational complexity.
Keywords: LiDAR point cloud; facet representation; object contour; obstacle detection.
Conflict of interest statement
The authors declare no conflict of interest.
Figures





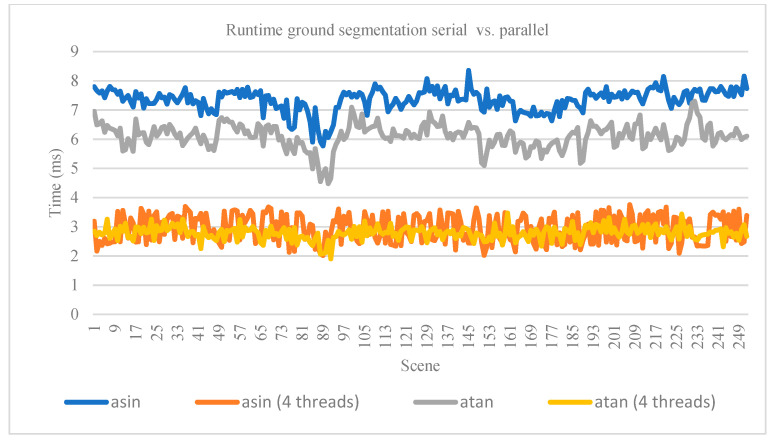
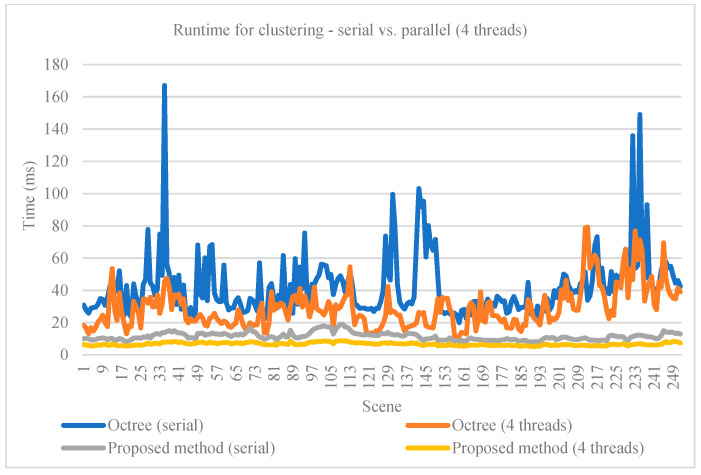




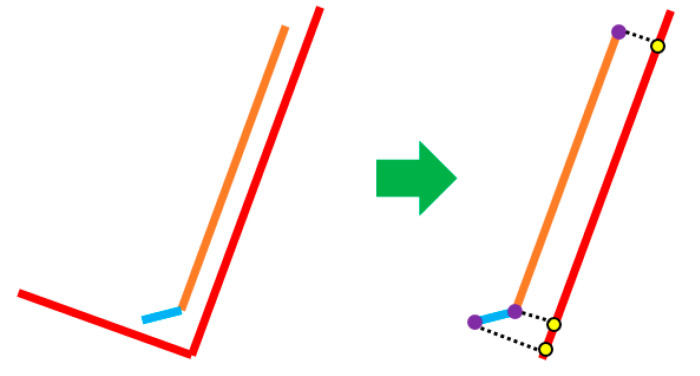

Similar articles
-
Background Point Filtering of Low-Channel Infrastructure-Based LiDAR Data Using a Slice-Based Projection Filtering Algorithm.Sensors (Basel). 2020 May 28;20(11):3054. doi: 10.3390/s20113054. Sensors (Basel). 2020. PMID: 32481575 Free PMC article.
-
PTA-Det: Point Transformer Associating Point Cloud and Image for 3D Object Detection.Sensors (Basel). 2023 Mar 17;23(6):3229. doi: 10.3390/s23063229. Sensors (Basel). 2023. PMID: 36991940 Free PMC article.
-
Pre-Segmented Down-Sampling Accelerates Graph Neural Network-Based 3D Object Detection in Autonomous Driving.Sensors (Basel). 2024 Feb 23;24(5):1458. doi: 10.3390/s24051458. Sensors (Basel). 2024. PMID: 38474994 Free PMC article.
-
Real-Time LIDAR-Based Urban Road and Sidewalk Detection for Autonomous Vehicles.Sensors (Basel). 2021 Dec 28;22(1):194. doi: 10.3390/s22010194. Sensors (Basel). 2021. PMID: 35009736 Free PMC article.
-
Sensor and Sensor Fusion Technology in Autonomous Vehicles: A Review.Sensors (Basel). 2021 Mar 18;21(6):2140. doi: 10.3390/s21062140. Sensors (Basel). 2021. PMID: 33803889 Free PMC article. Review.
Cited by
-
Experimental Validation of LiDAR Sensors Used in Vehicular Applications by Using a Mobile Platform for Distance and Speed Measurements.Sensors (Basel). 2021 Dec 6;21(23):8147. doi: 10.3390/s21238147. Sensors (Basel). 2021. PMID: 34884154 Free PMC article.
References
-
- Li Y., Ibanez-Guzman J. Lidar for Autonomous Driving: The Principles, Challenges, and Trends for Automotive Lidar and Perception Systems. IEEE Signal Process. Mag. 2020;37:50–61.
-
- Chen L., Yang J., Kong H. Lidar-histogram for fast road and obstacle detection; Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA); Singapore. 29 May–3 June 2017; pp. 1343–1348.
-
- Chu P., Cho S., Sim S., Kwak K., Cho K. A Fast Ground Segmentation Method for 3D Point Cloud. J. Inf. Process. Syst. 2017;13:491–499.
-
- Asvadi A., Premebida C., Peixoto P., Nunes U. 3D Lidar-based Static and Moving Obstacle Detection in Driving Environments. Robot. Auton. Syst. 2016;83:299–311. doi: 10.1016/j.robot.2016.06.007. - DOI
-
- Zhe C., Zijing C. RBNet: A Deep Neural Network for Unified Road and Road Boundary Detection; Proceedings of the International Conference on Neural Information Processing; Guangzhou, China. 14–18 November 2017; pp. 677–687.
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
