

Accelerating simulations of cardiac electrical dynamics through a multi-GPU platform and an optimized data structure
- PMID: 34720756
- PMCID: PMC8552220
- DOI: 10.1002/cpe.5528
Accelerating simulations of cardiac electrical dynamics through a multi-GPU platform and an optimized data structure
Abstract
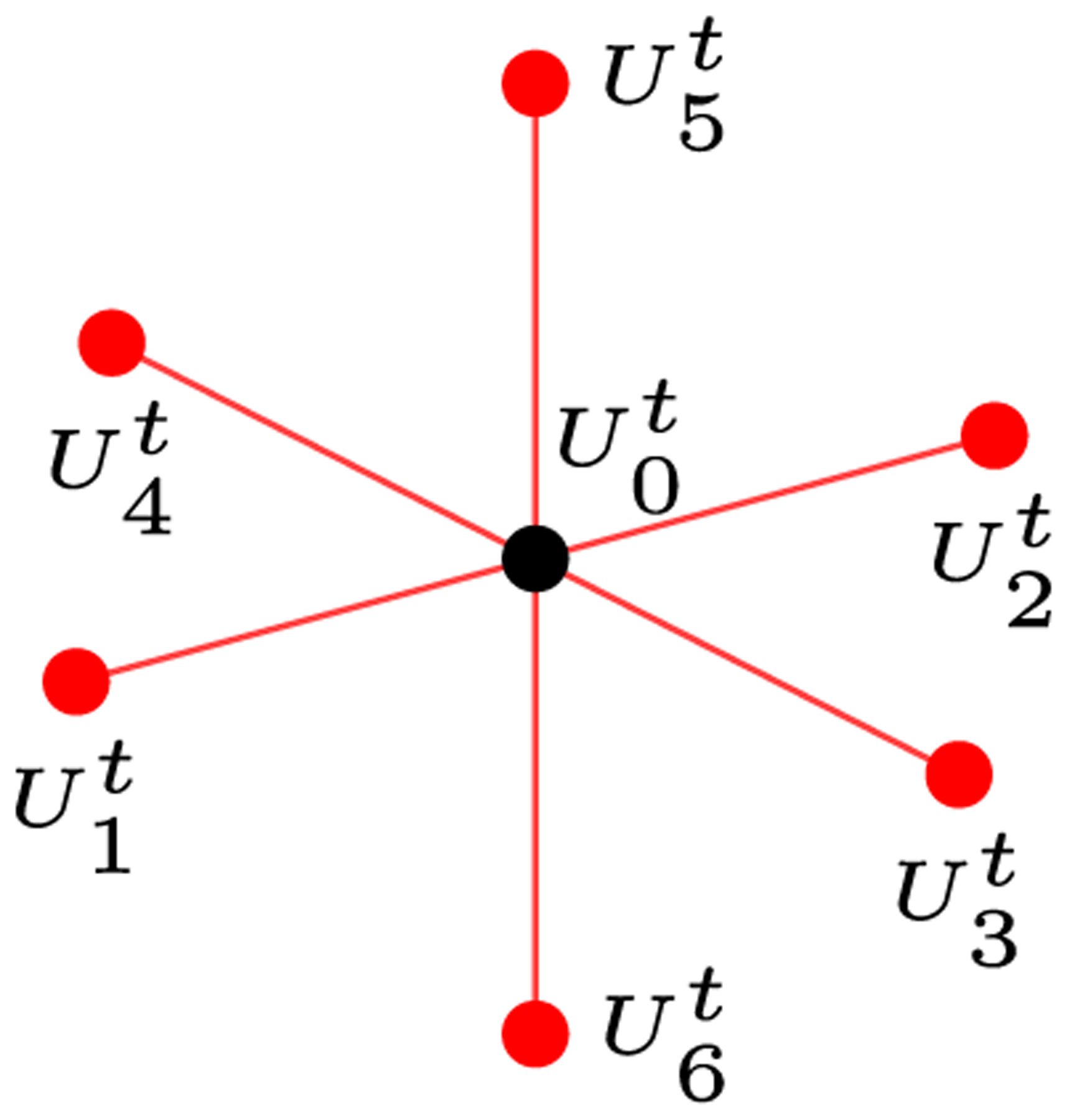
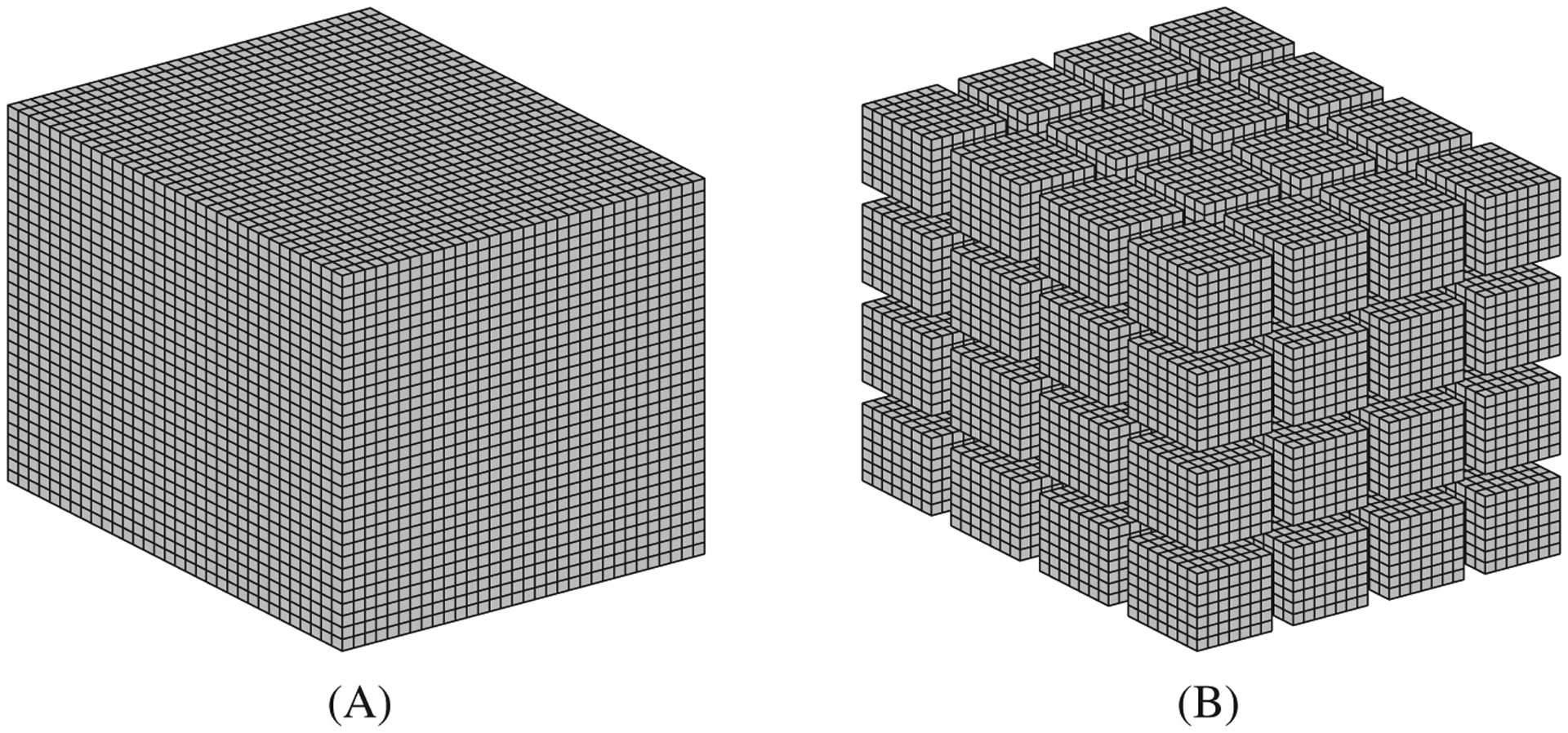
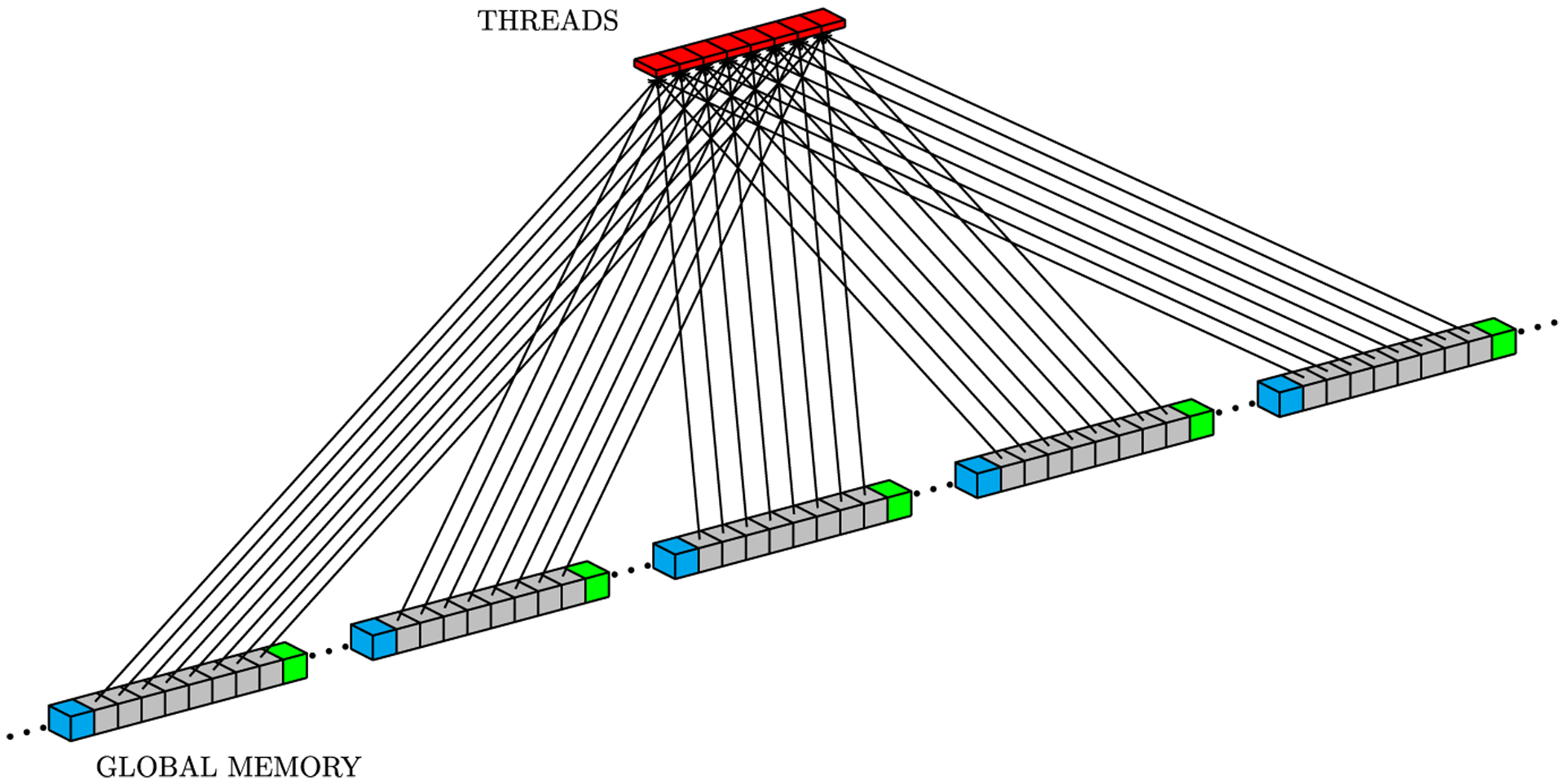
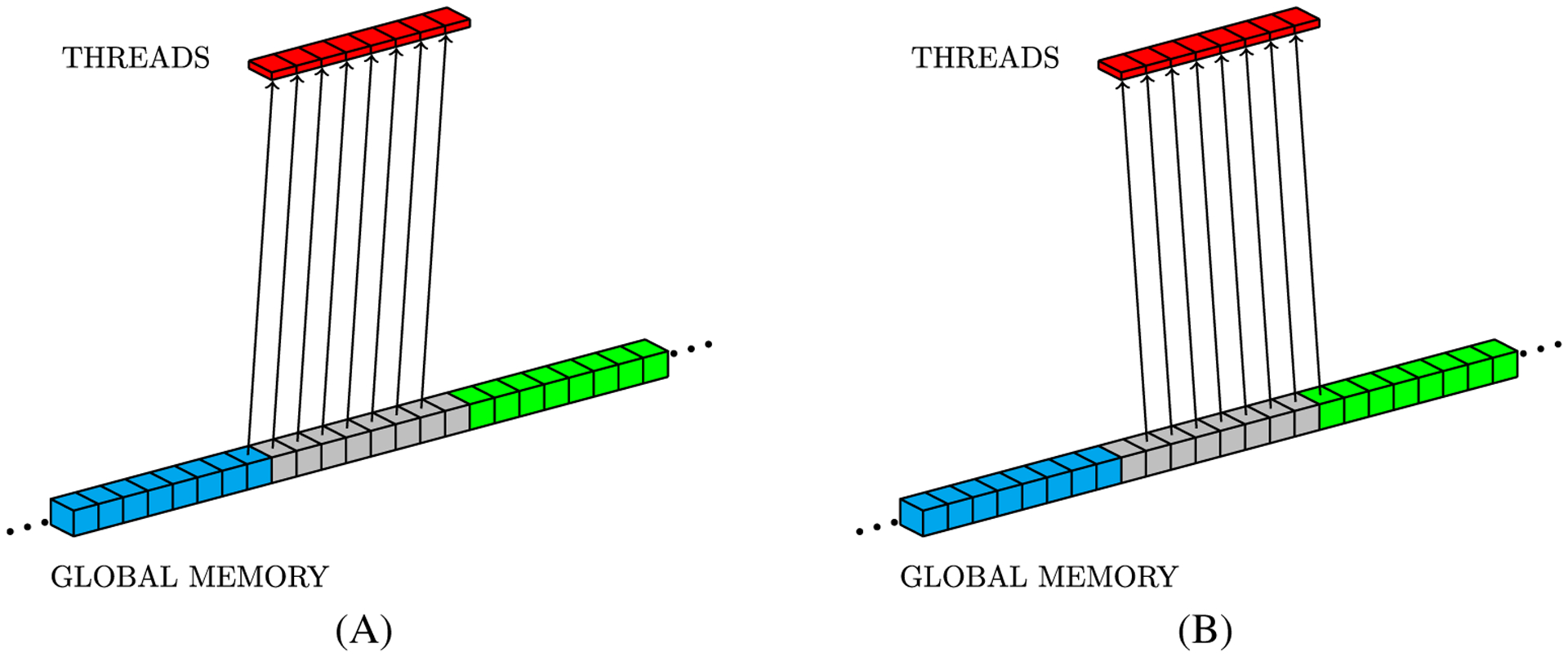
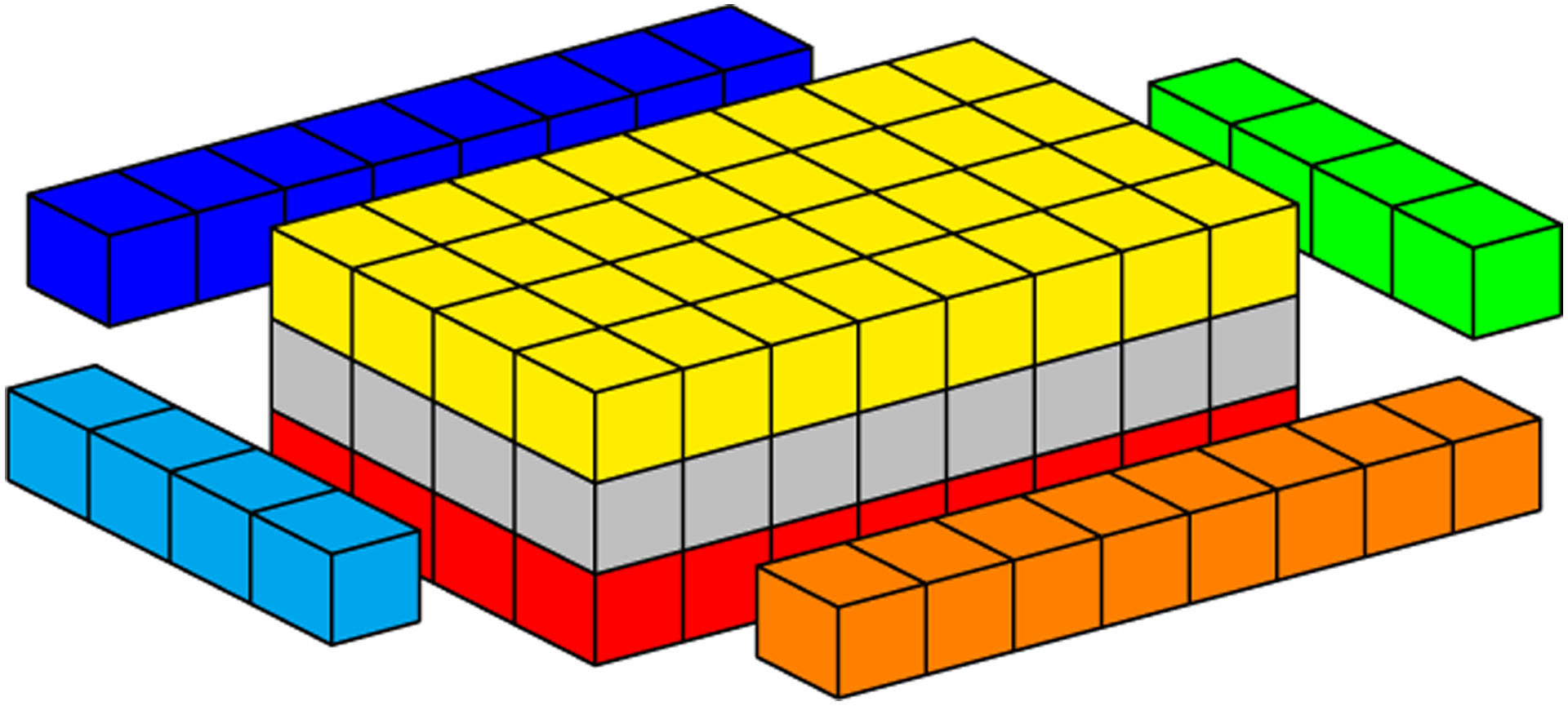
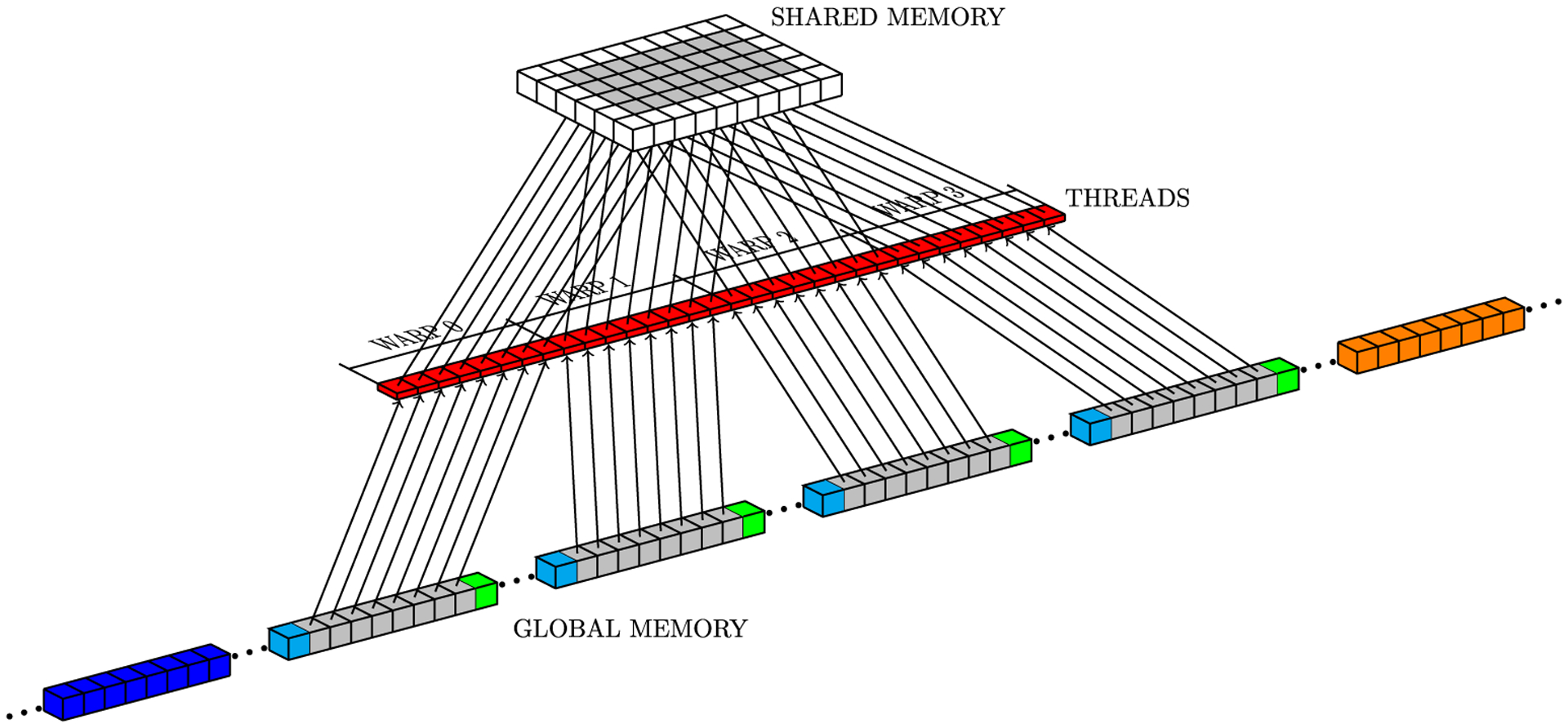
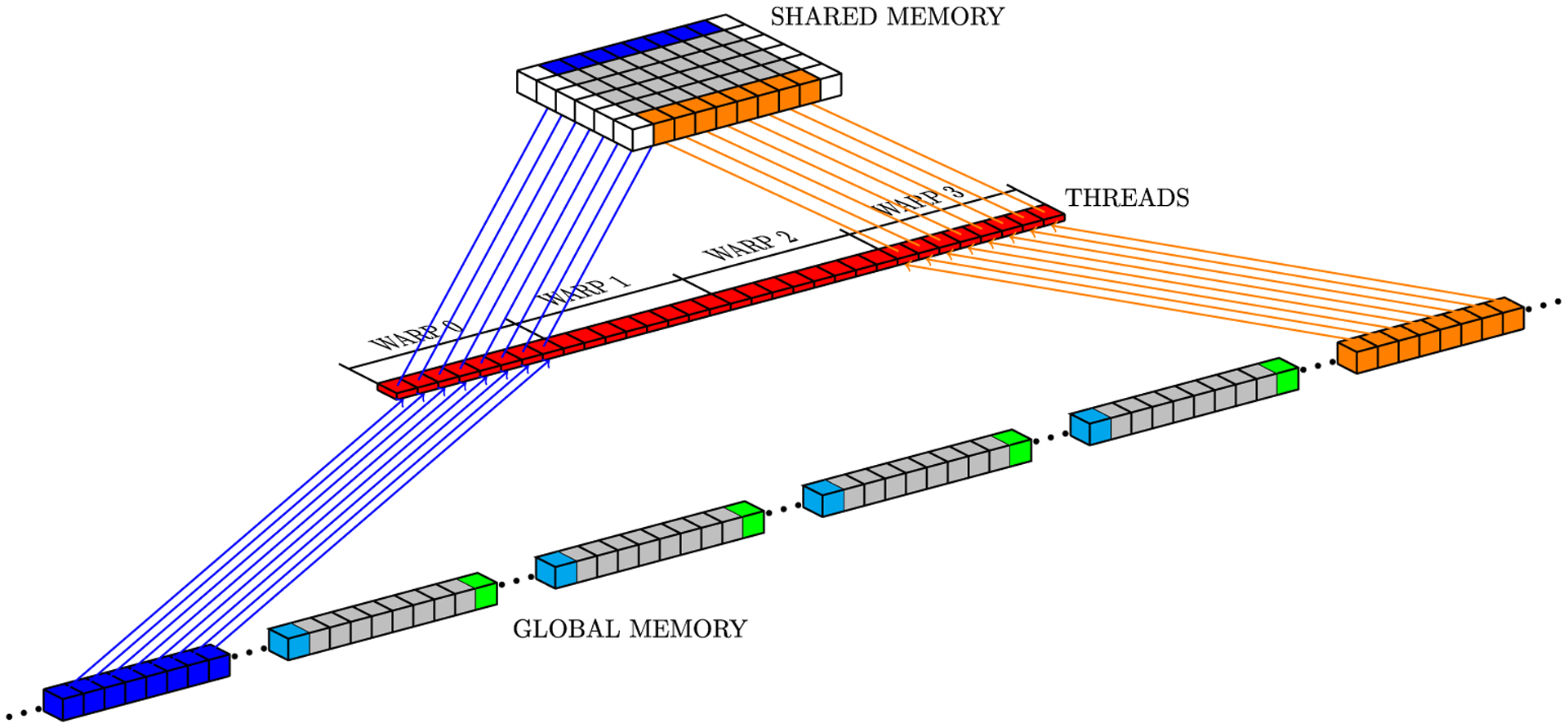
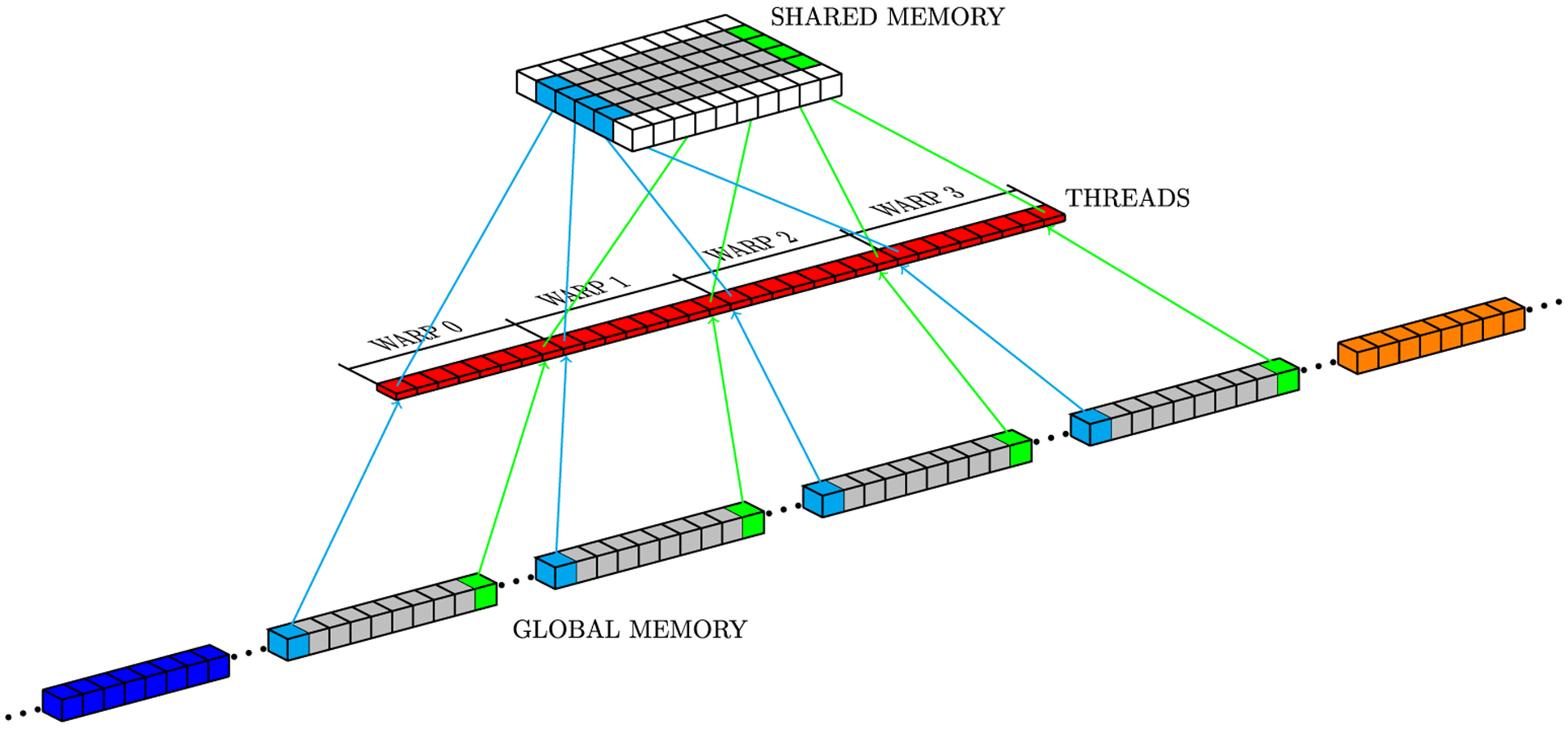
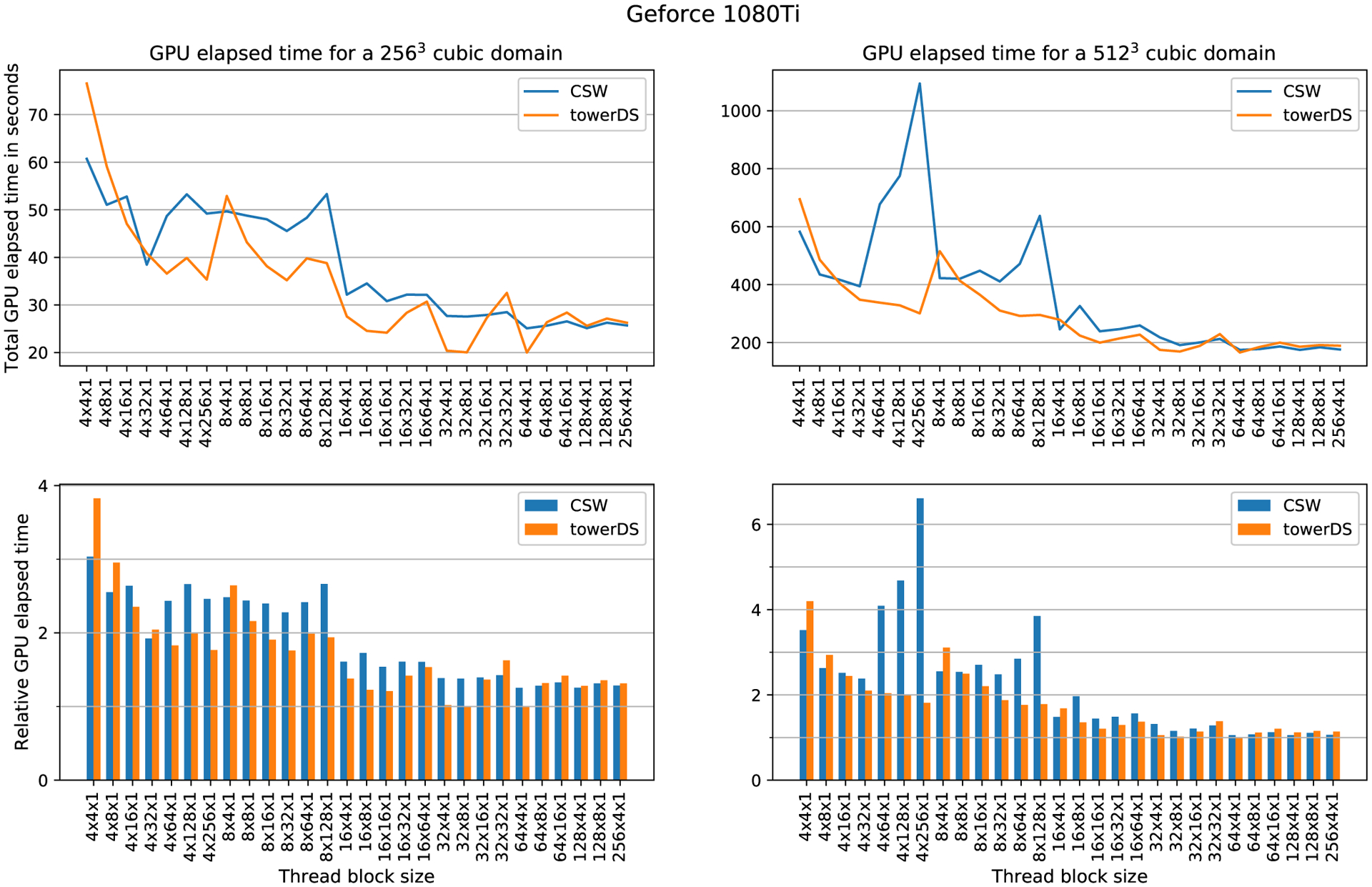
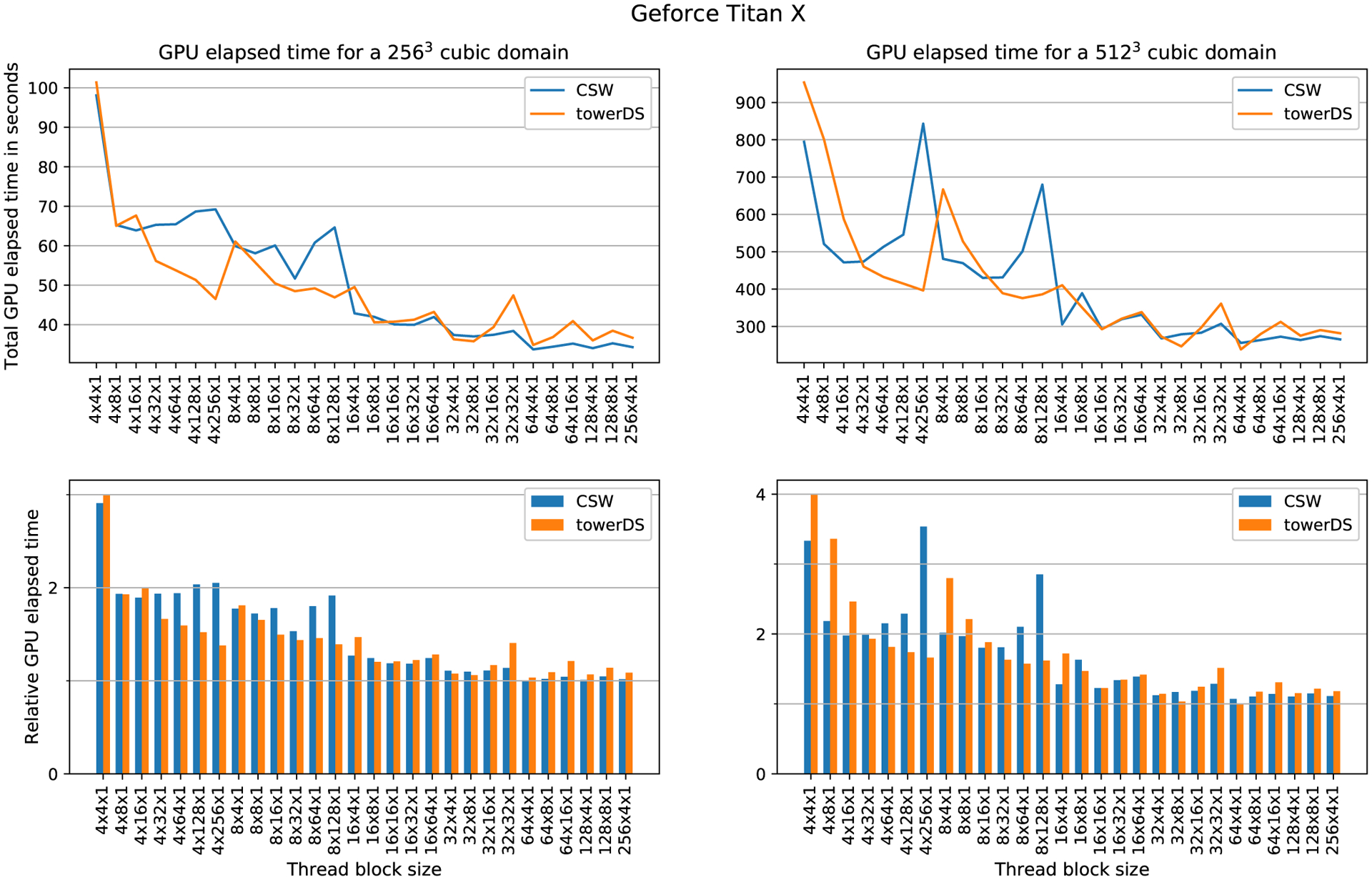
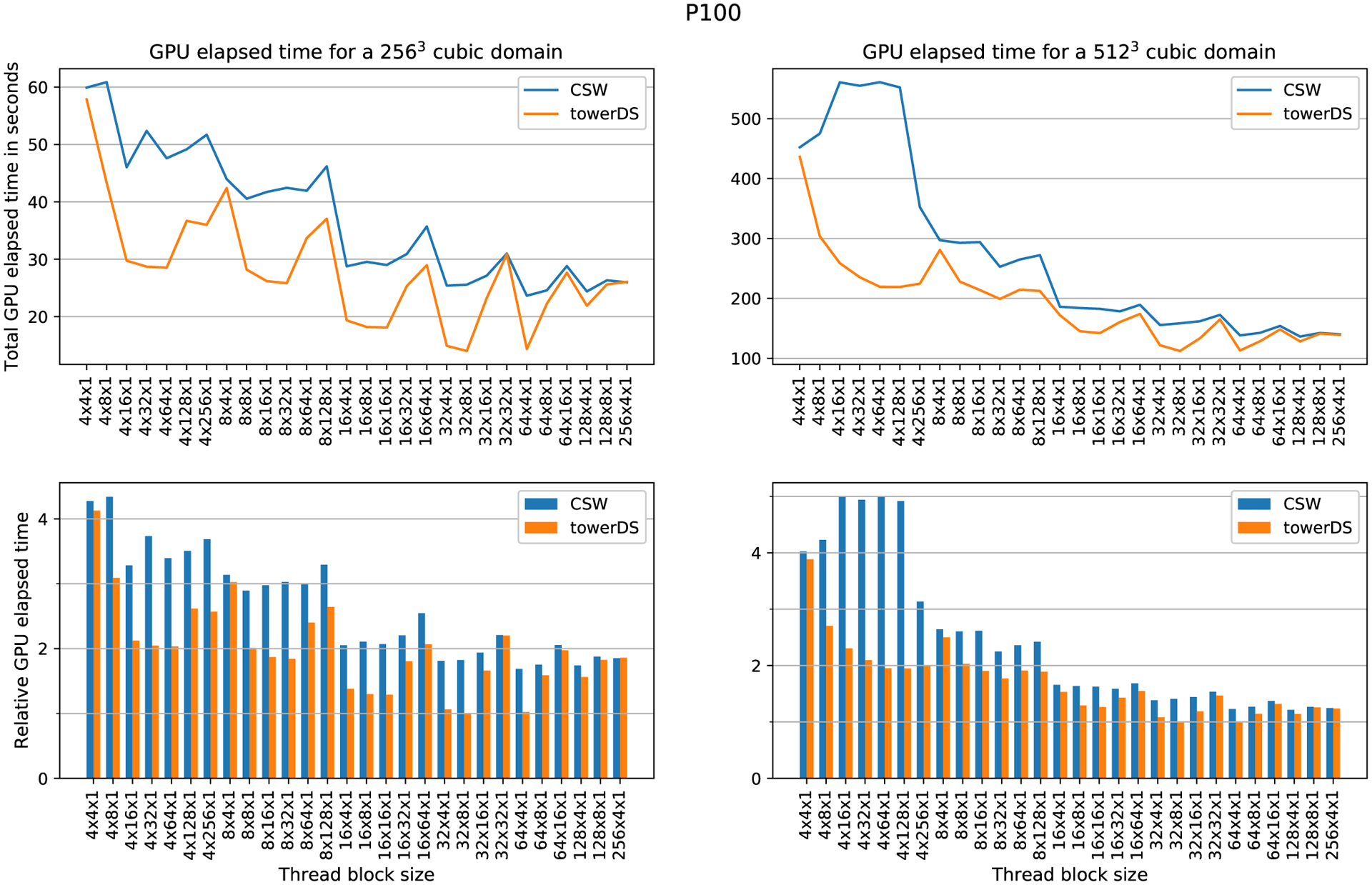
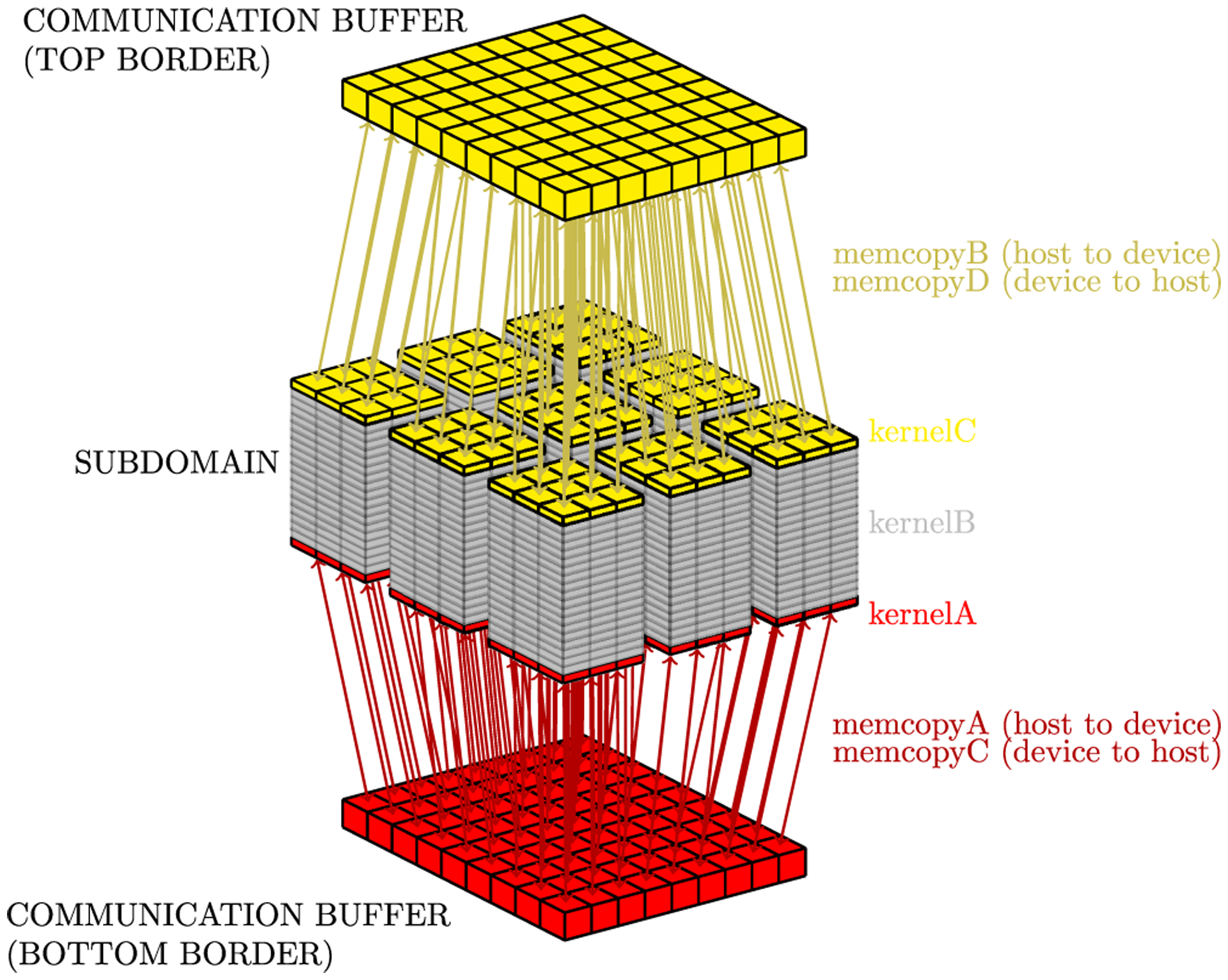
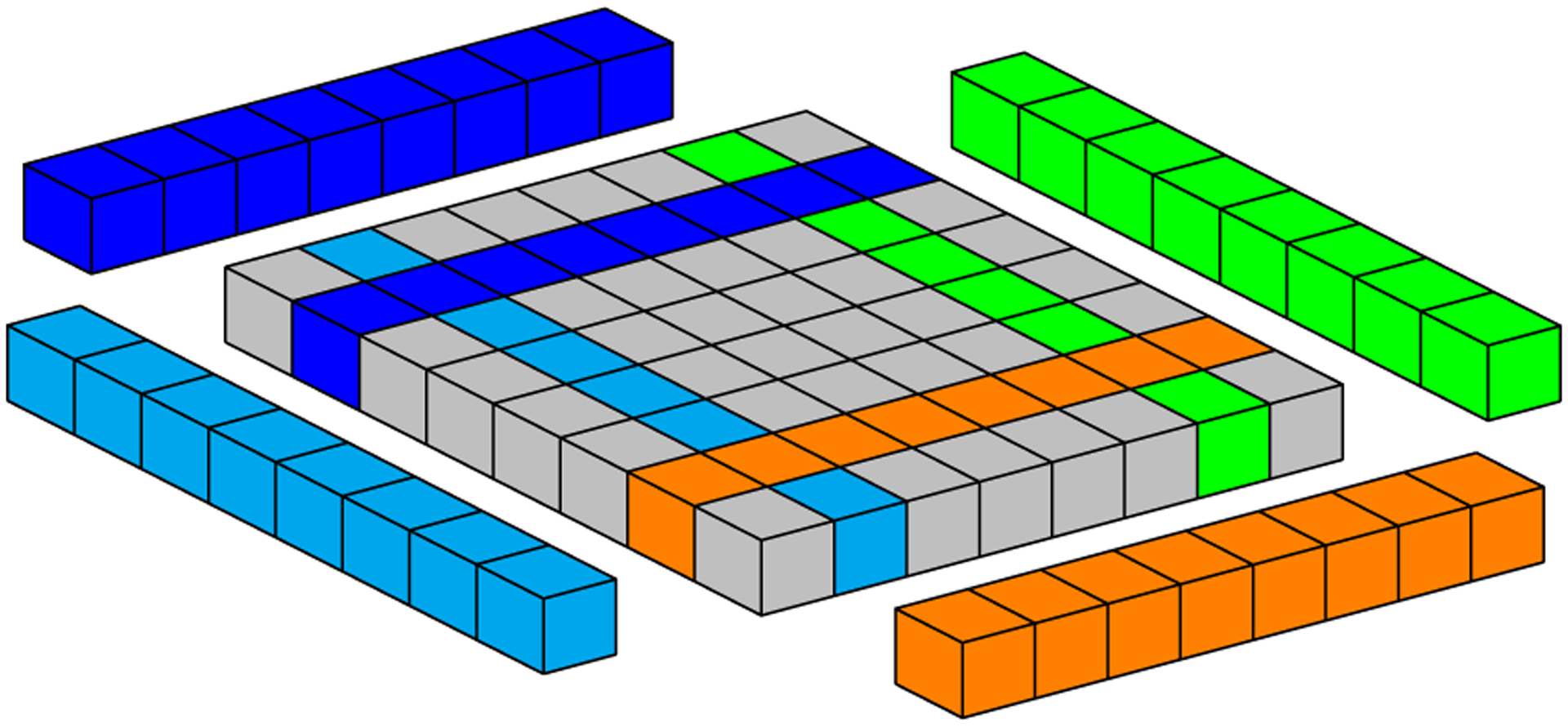
Simulations of cardiac electrophysiological models in tissue, particularly in 3D require the solutions of billions of differential equations even for just a couple of milliseconds, thus highly demanding in computational resources. In fact, even studies in small domains with very complex models may take several hours to reproduce seconds of electrical cardiac behavior. Today's Graphics Processor Units (GPUs) are becoming a way to accelerate such simulations, and give the added possibilities to run them locally without the need for supercomputers. Nevertheless, when using GPUs, bottlenecks related to global memory access caused by the spatial discretization of the large tissue domains being simulated, become a big challenge. For simulations in a single GPU, we propose a strategy to accelerate the computation of the diffusion term through a data-structure and memory access pattern designed to maximize coalescent memory transactions and minimize branch divergence, achieving results approximately 1.4 times faster than a standard GPU method. We also combine this data structure with a designed communication strategy to take advantage in the case of simulations in multi-GPU platforms. We demonstrate that, in the multi-GPU approach performs, simulations in 3D tissue can be just 4× slower than real time.
Keywords: GPU Computing; cardiac electrophysiology models; memory access optimization; parallel cardiac dynamics simulations.
Conflict of interest statement
CONFLICT OF INTEREST The authors declare no potential conflict of interests.
Figures
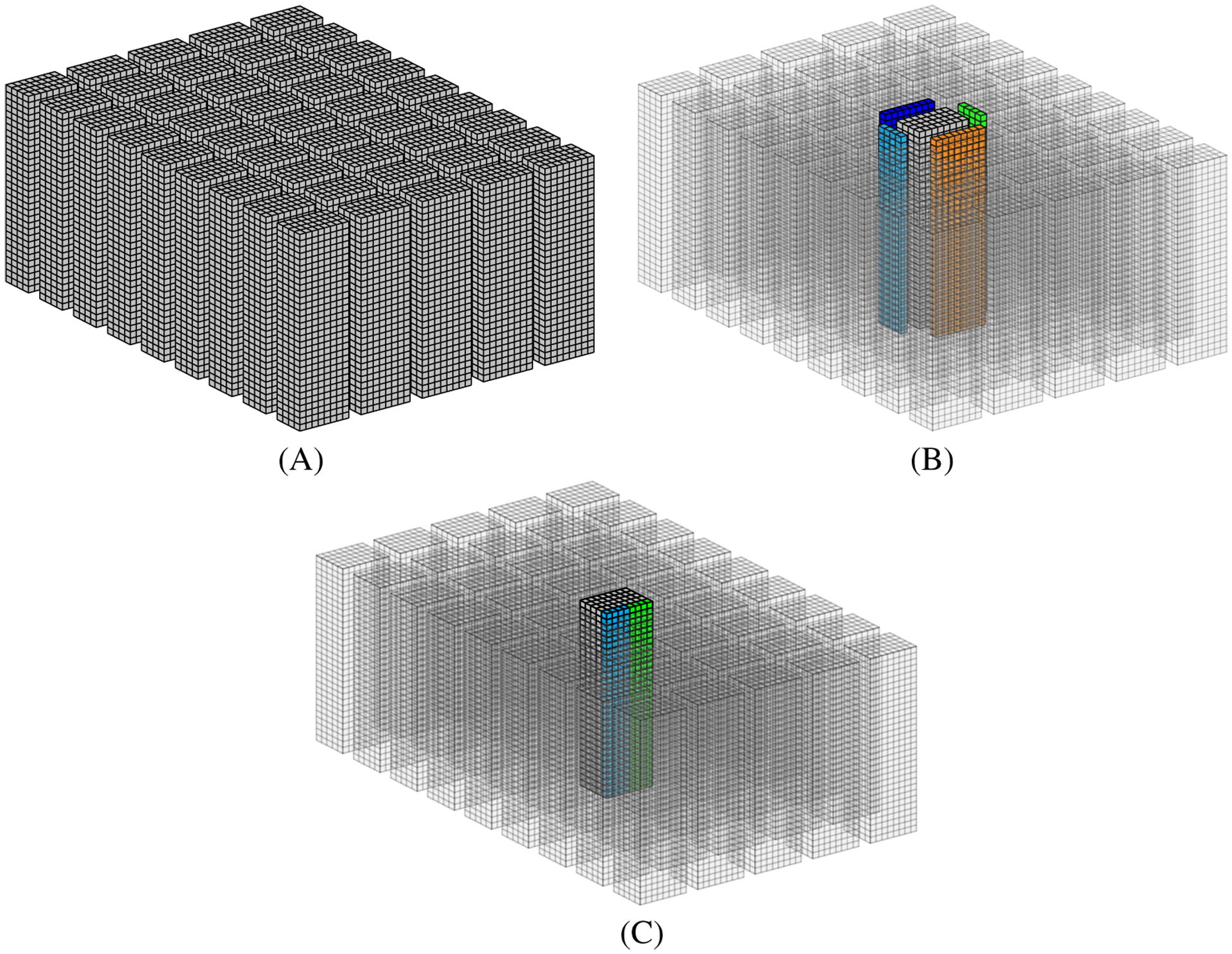
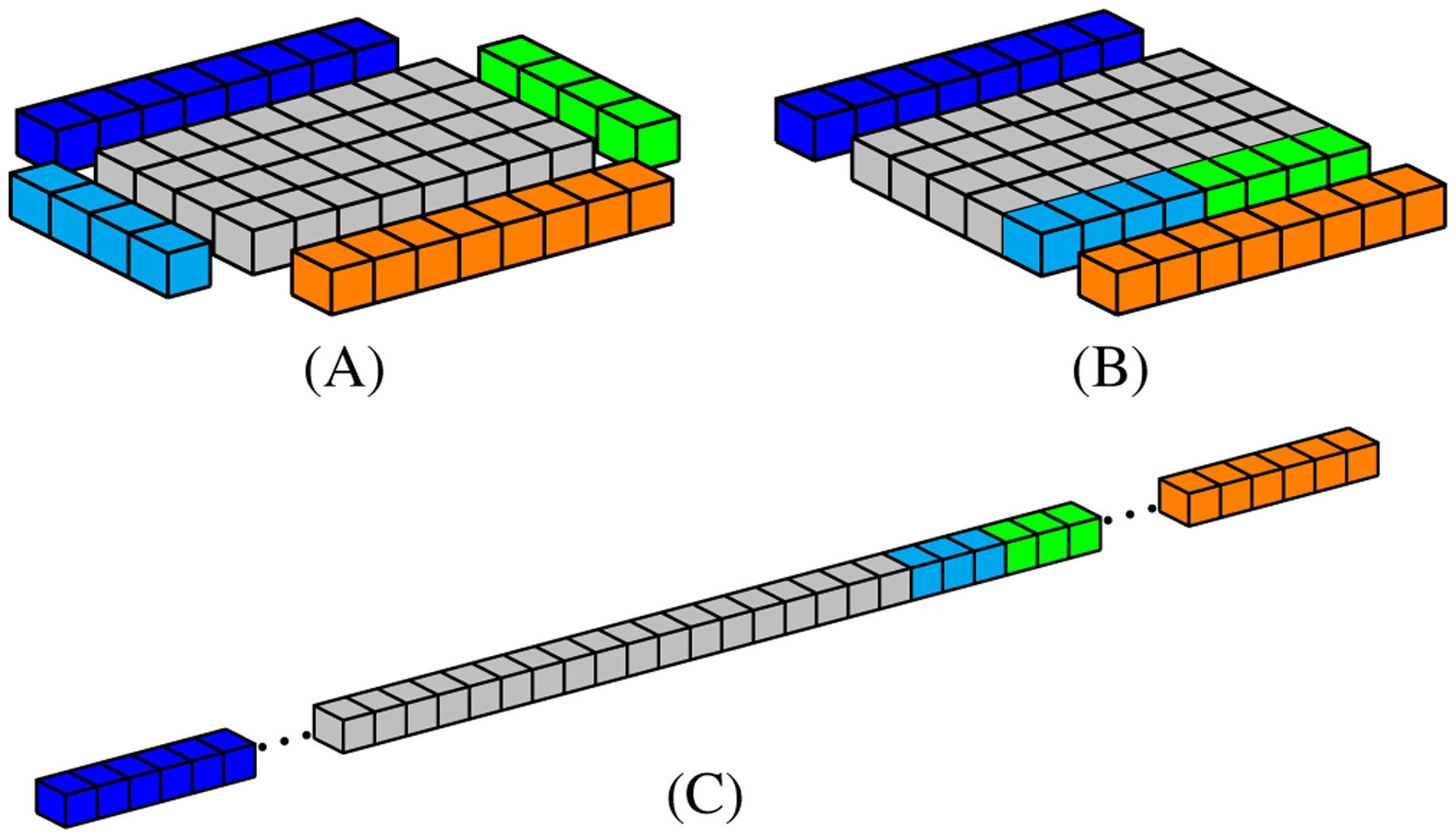
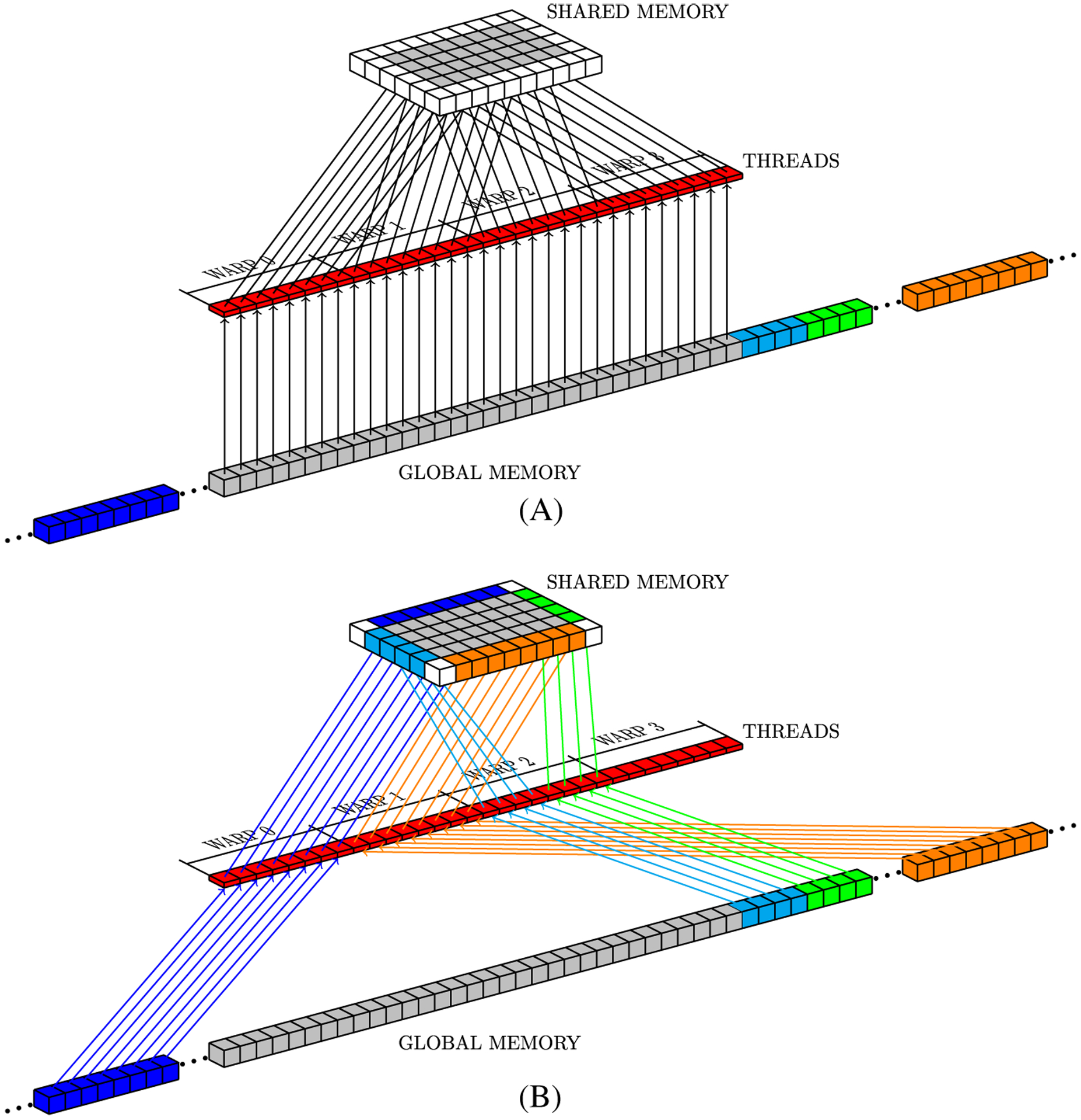
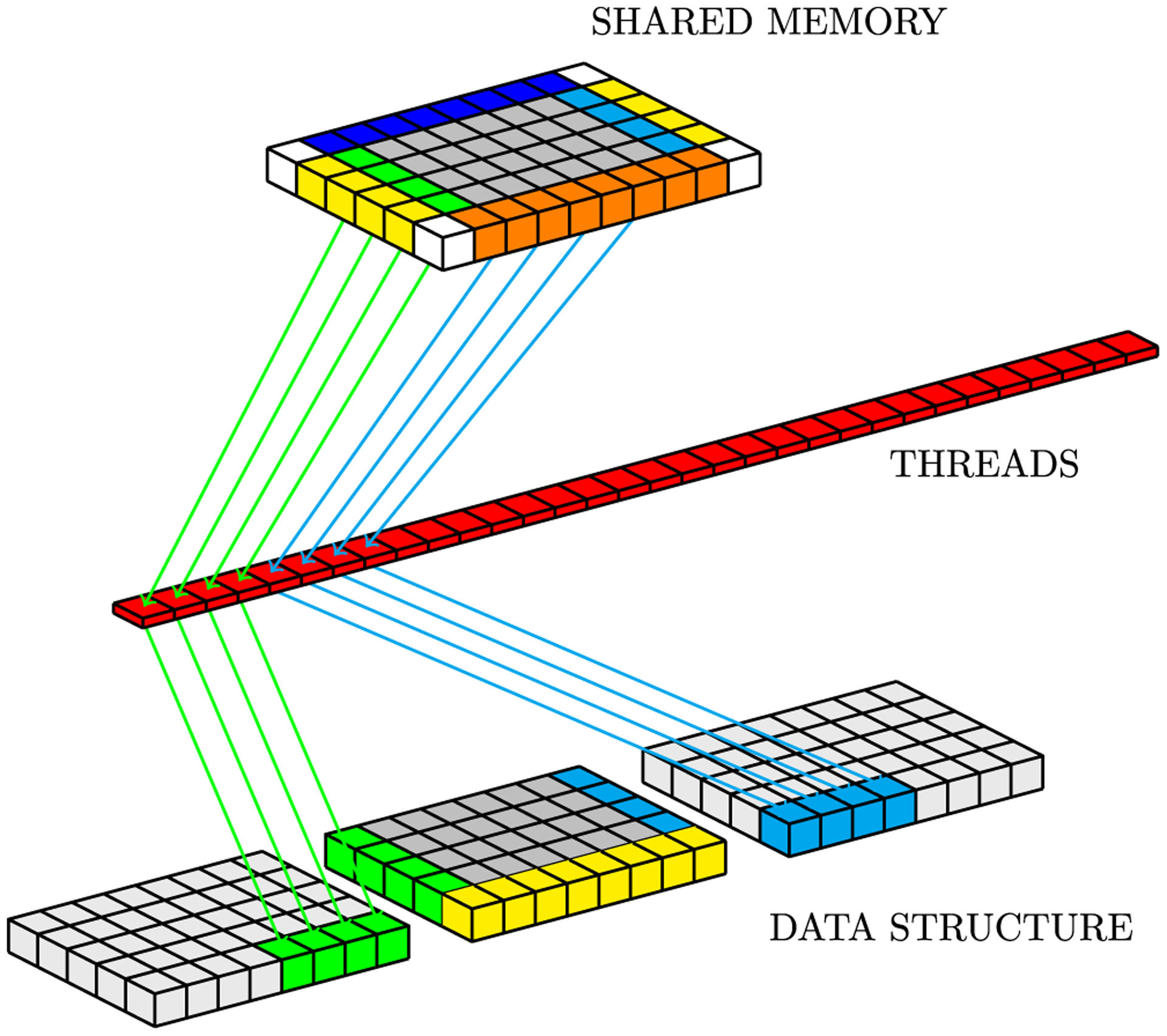
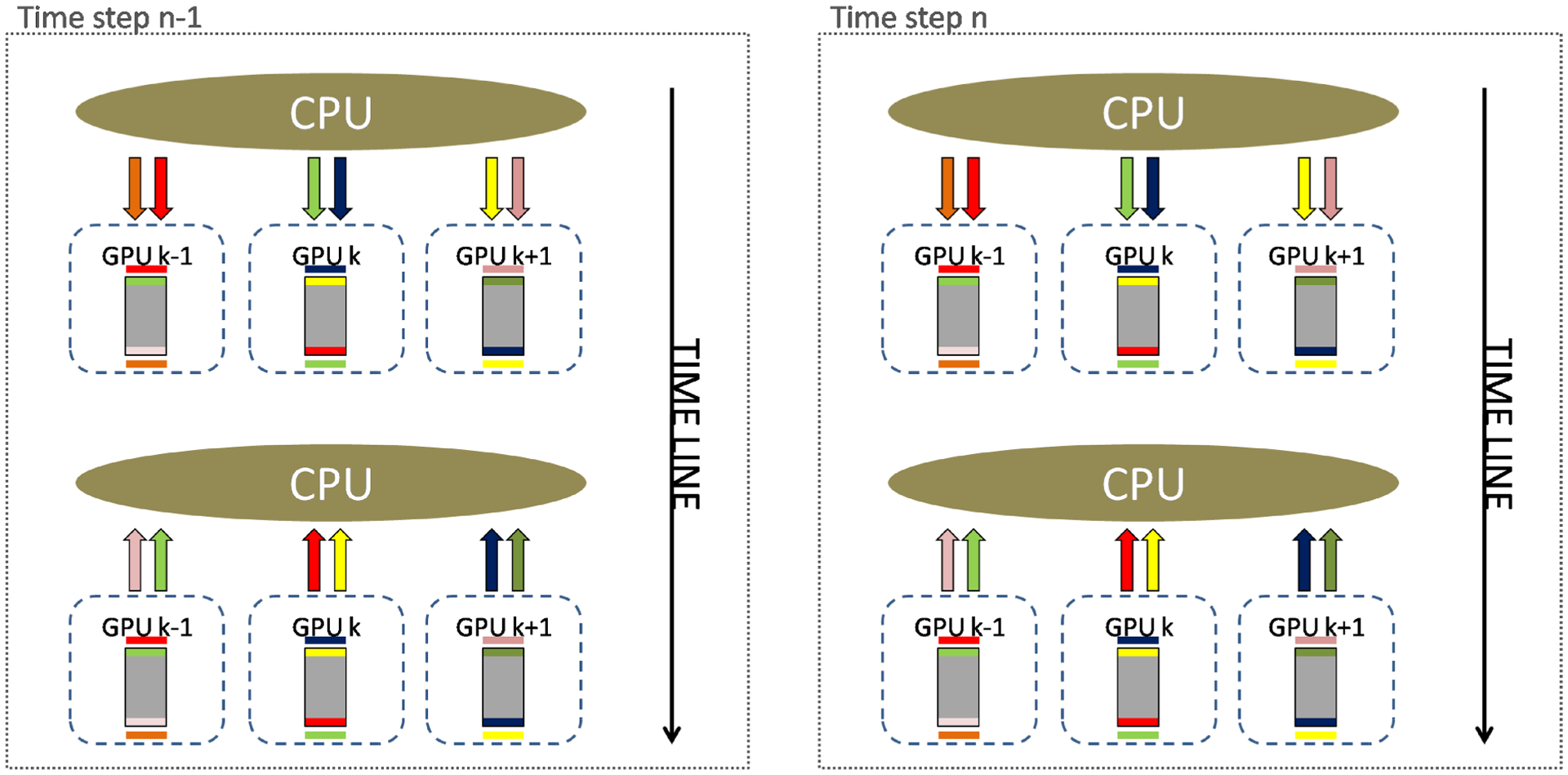
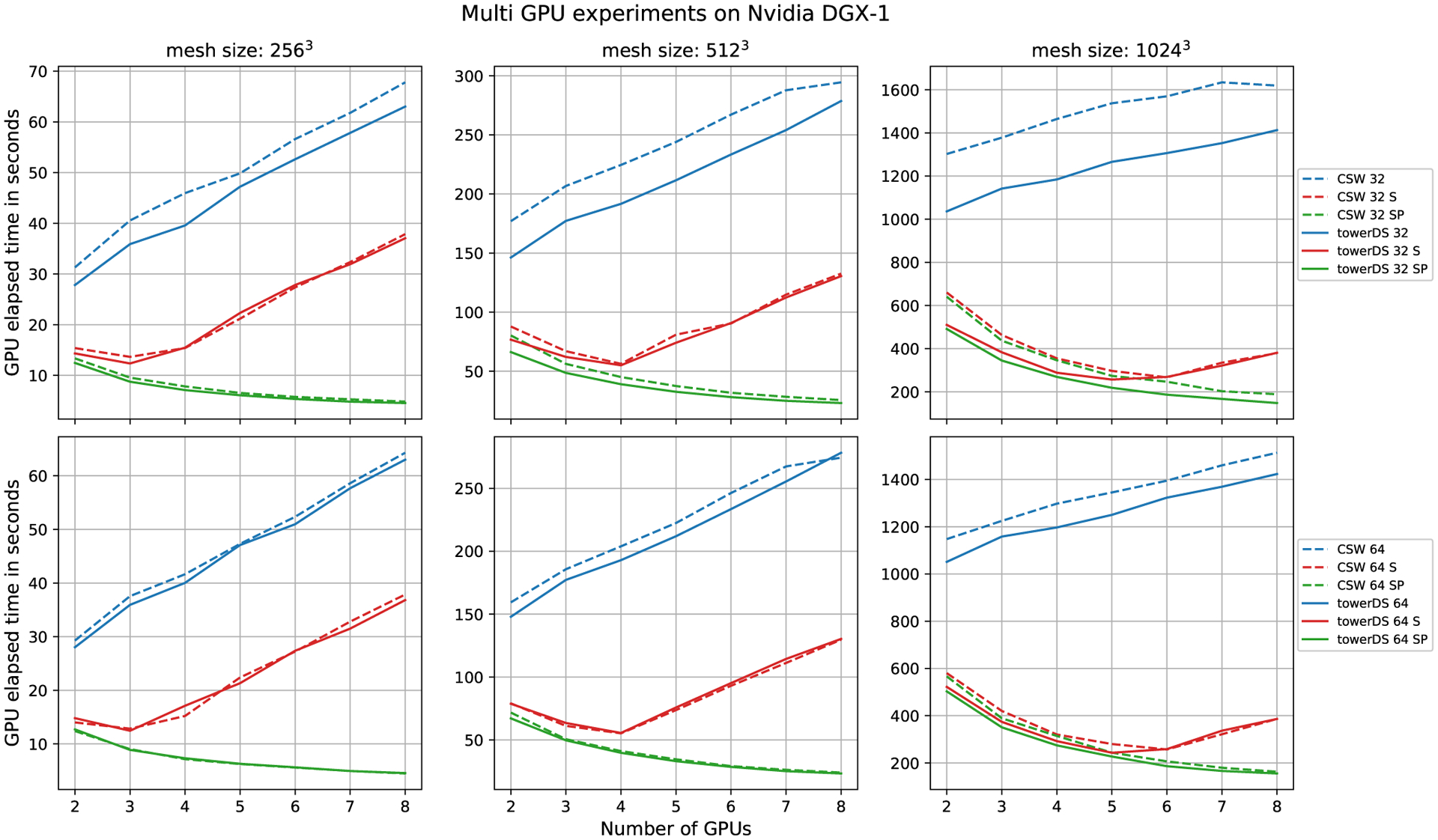
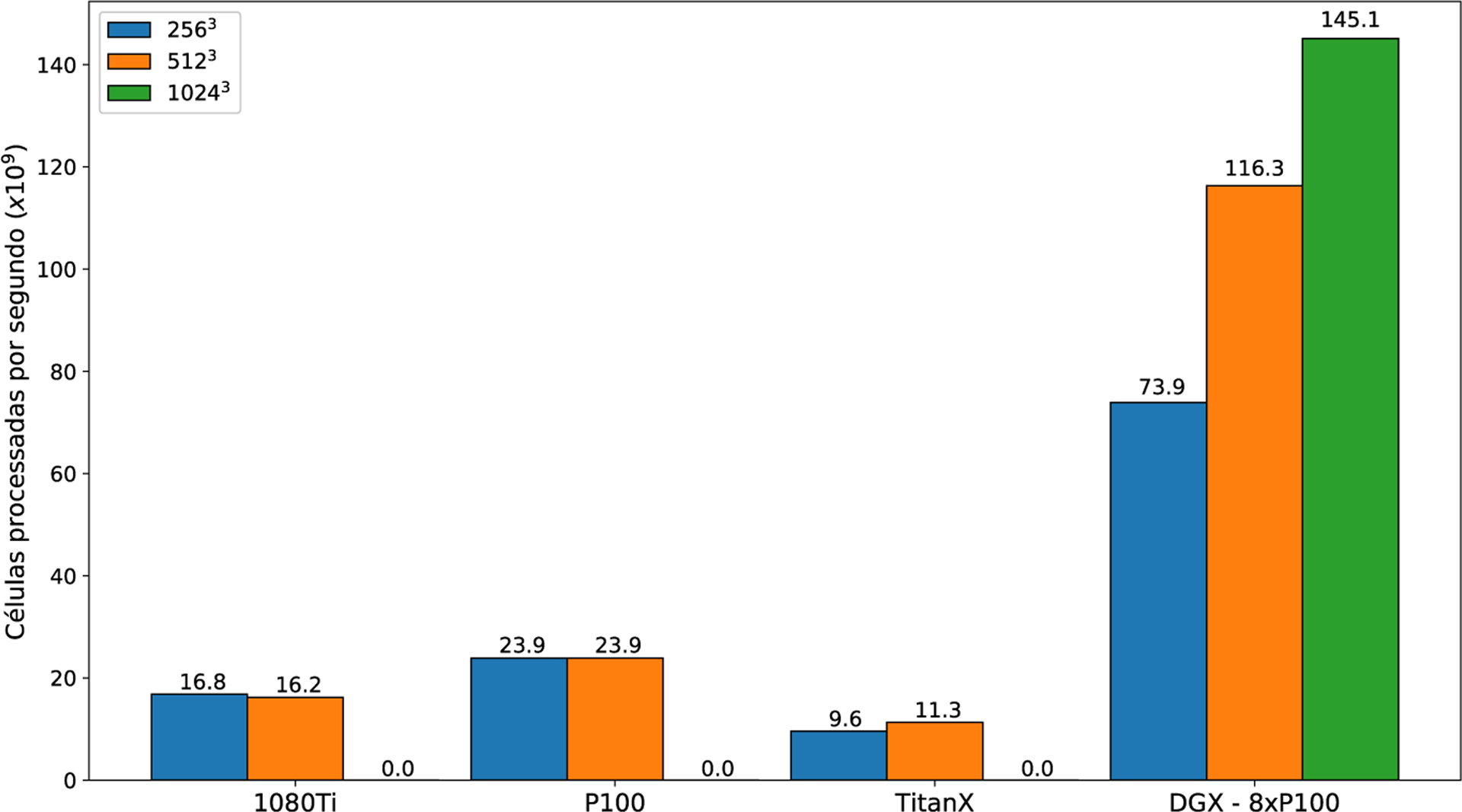
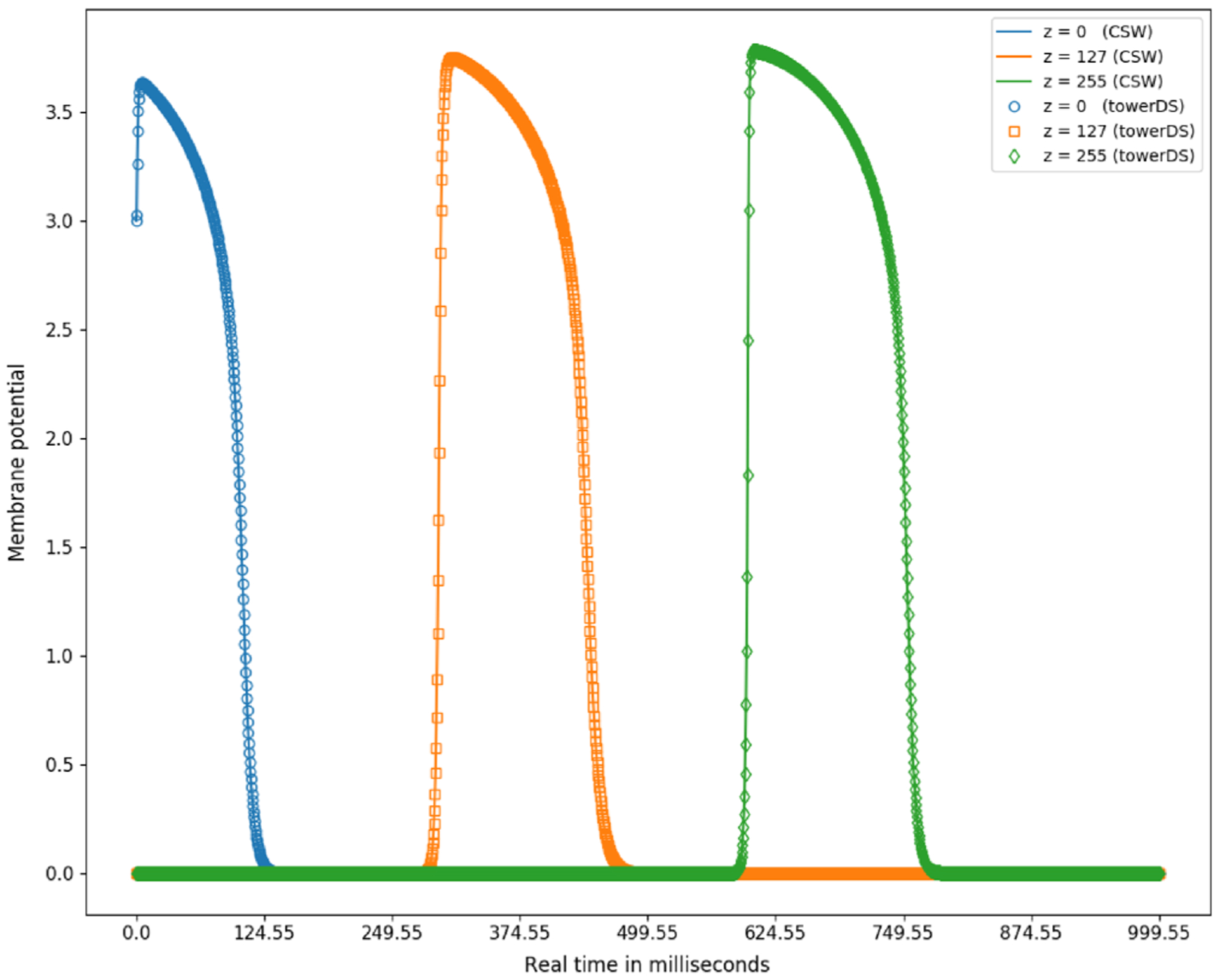

References
-
- Patterson D, Anderson T, Cardwell N, et al. A case for intelligent RAM. IEEE Micro. 1997;17(2):34–44.
-
- Patterson DA, Hennessy JL. Computer Organization and Design. Cambridge, MA: Morgan Kaufmann; 2007:474–476.
-
- Whaley RC, Dongarra JJ. Automatically tuned linear algebra software. In: Proceedings of the 1998 ACM/IEEE Conference on Supercomputing; 1998; Orlando, FL.
-
- Dongarra J Sparse matrix storage formats. Templates for the Solution of Algebraic Eigenvalue Problems: A Practical Guide. Philadelphia, PA: SIAM; 2000:445–448.
-
- Silva J, Boeres C, Drummond L, Pessoa AA. Memory aware load balance strategy on a parallel branch-and-bound application. Concurr Comput Pract Exp. 2015;27(5):1122–1144.
Grants and funding
LinkOut - more resources
Full Text Sources