

Accurate recognition of colorectal cancer with semi-supervised deep learning on pathological images
- PMID: 34728629
- PMCID: PMC8563931
- DOI: 10.1038/s41467-021-26643-8
Accurate recognition of colorectal cancer with semi-supervised deep learning on pathological images
Abstract
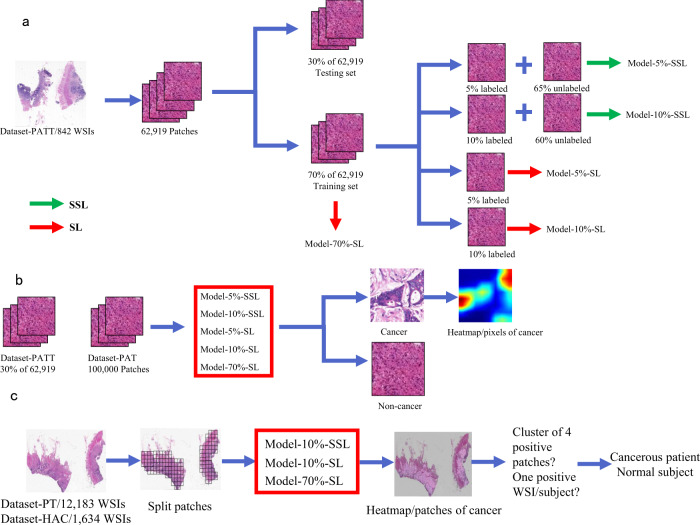
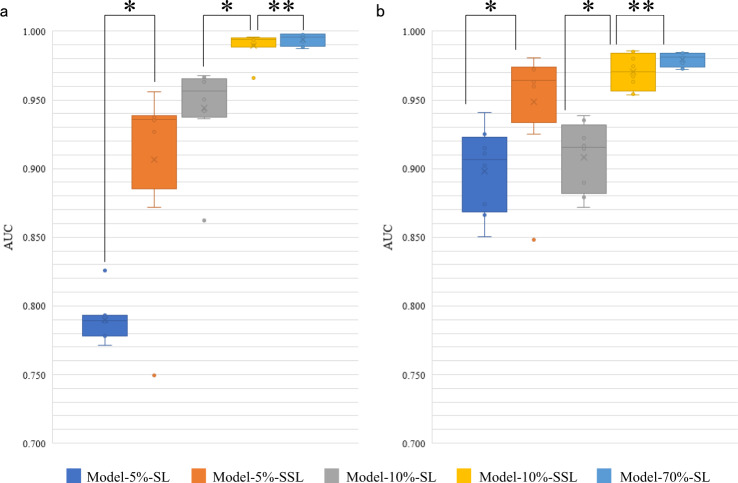
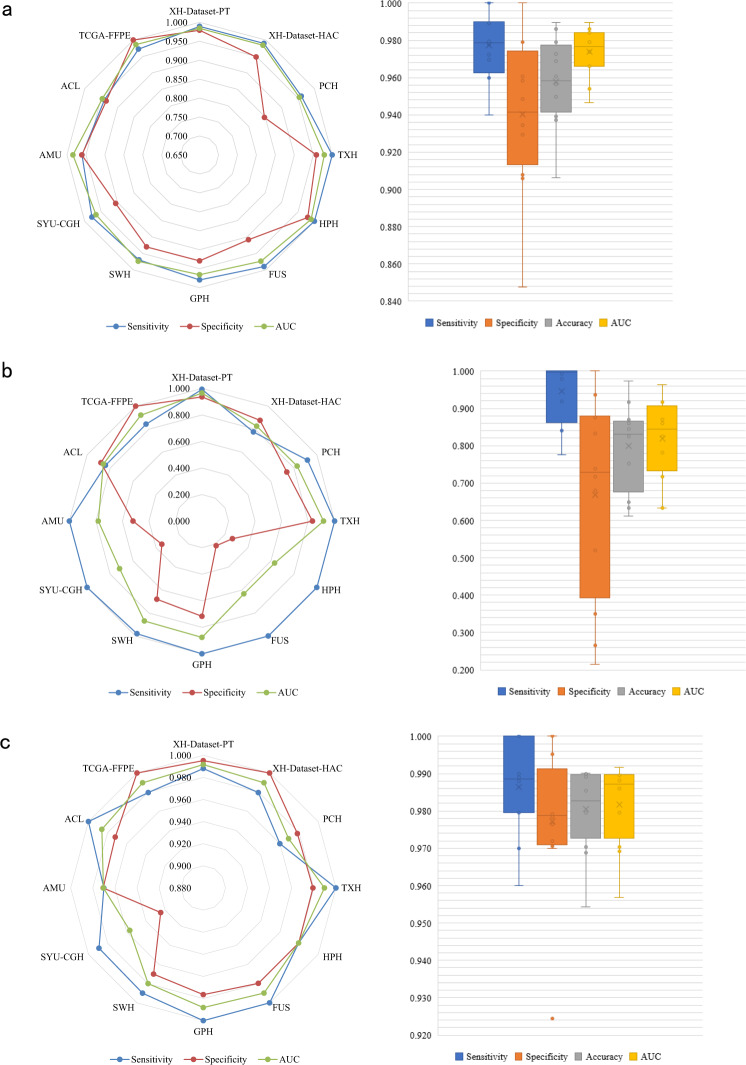
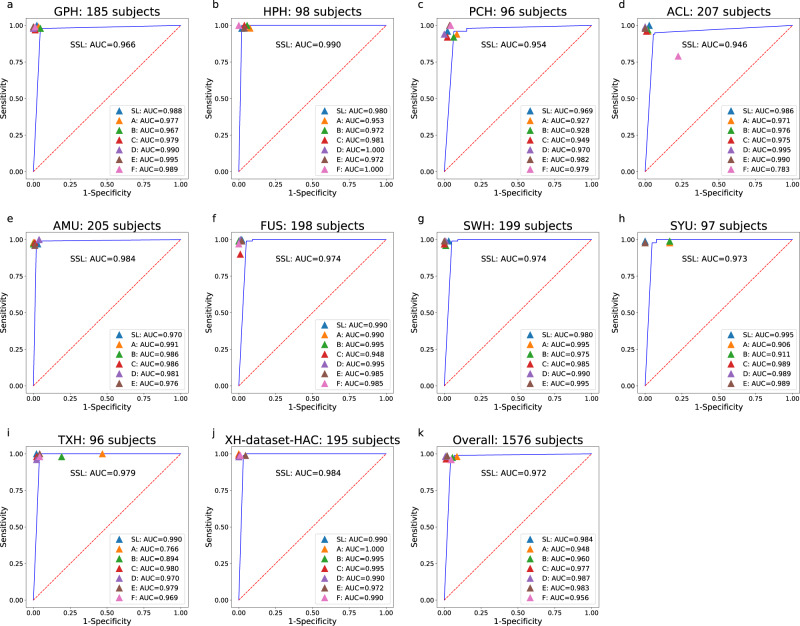
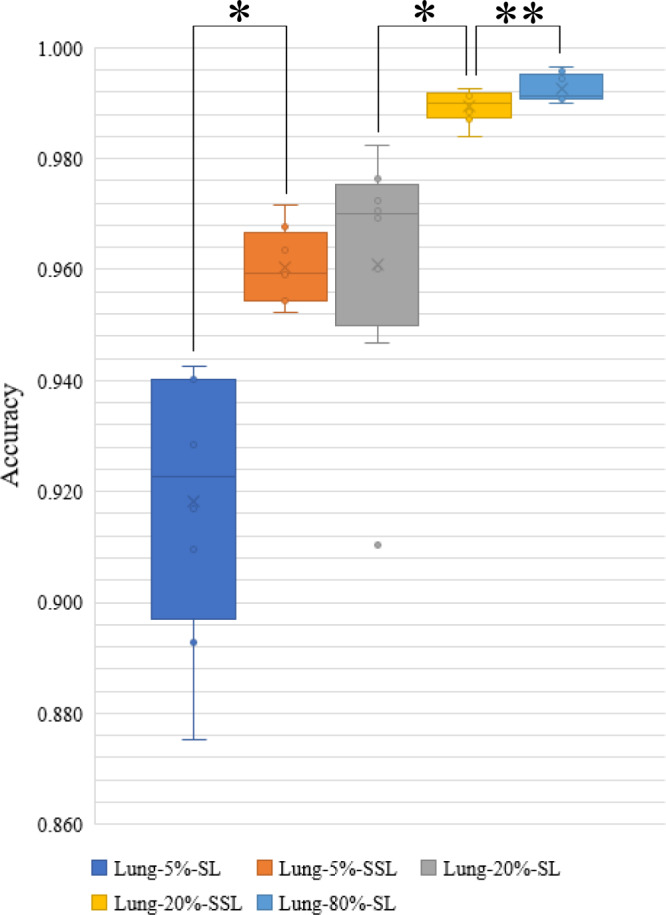
Machine-assisted pathological recognition has been focused on supervised learning (SL) that suffers from a significant annotation bottleneck. We propose a semi-supervised learning (SSL) method based on the mean teacher architecture using 13,111 whole slide images of colorectal cancer from 8803 subjects from 13 independent centers. SSL (~3150 labeled, ~40,950 unlabeled; ~6300 labeled, ~37,800 unlabeled patches) performs significantly better than the SL. No significant difference is found between SSL (~6300 labeled, ~37,800 unlabeled) and SL (~44,100 labeled) at patch-level diagnoses (area under the curve (AUC): 0.980 ± 0.014 vs. 0.987 ± 0.008, P value = 0.134) and patient-level diagnoses (AUC: 0.974 ± 0.013 vs. 0.980 ± 0.010, P value = 0.117), which is close to human pathologists (average AUC: 0.969). The evaluation on 15,000 lung and 294,912 lymph node images also confirm SSL can achieve similar performance as that of SL with massive annotations. SSL dramatically reduces the annotations, which has great potential to effectively build expert-level pathological artificial intelligence platforms in practice.
© 2021. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures

References
-
- Damjanov I. Robbins review of pathology. Mod. Pathol. 2000;13:1028. doi: 10.1038/modpathol.3880185. - DOI
Publication types
MeSH terms
Associated data
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
