

Assessing Open-Ended Human-Computer Collaboration Systems: Applying a Hallmarks Approach
- PMID: 34738081
- PMCID: PMC8561722
- DOI: 10.3389/frai.2021.670009
Assessing Open-Ended Human-Computer Collaboration Systems: Applying a Hallmarks Approach
Abstract
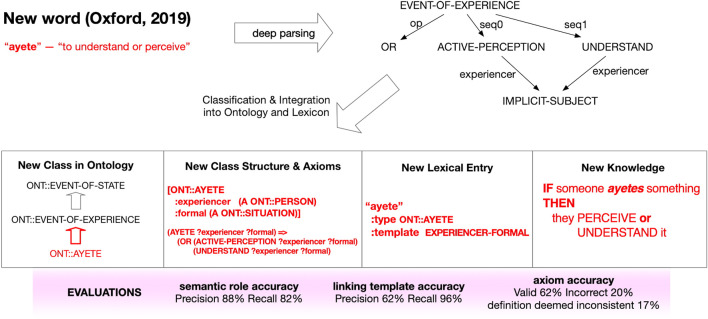
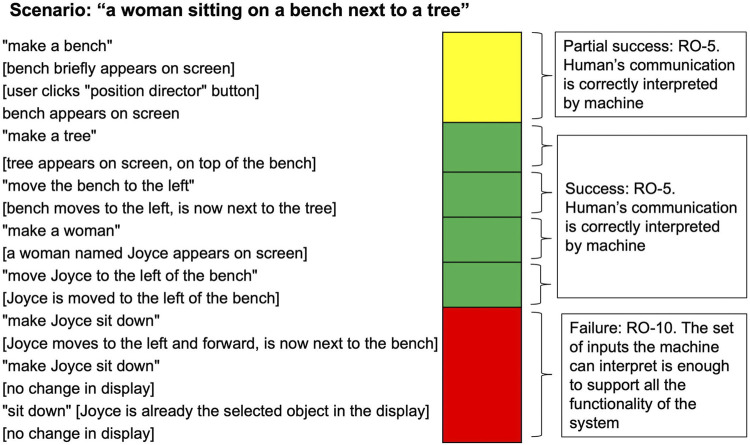
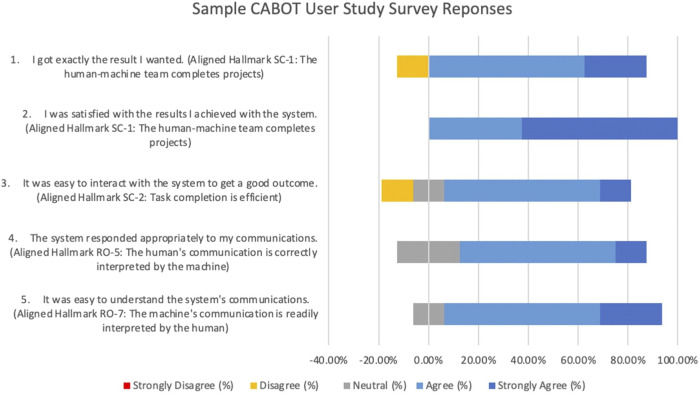
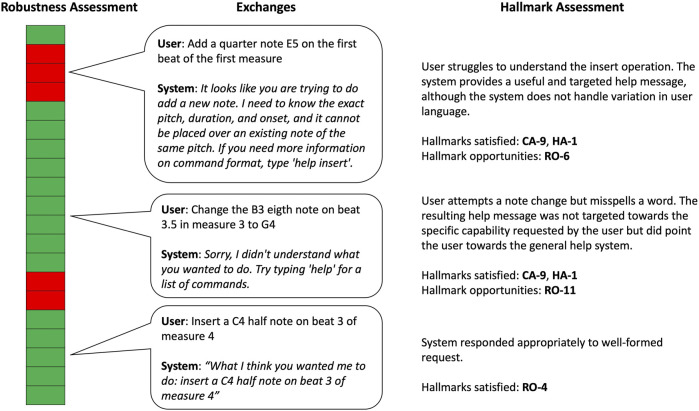
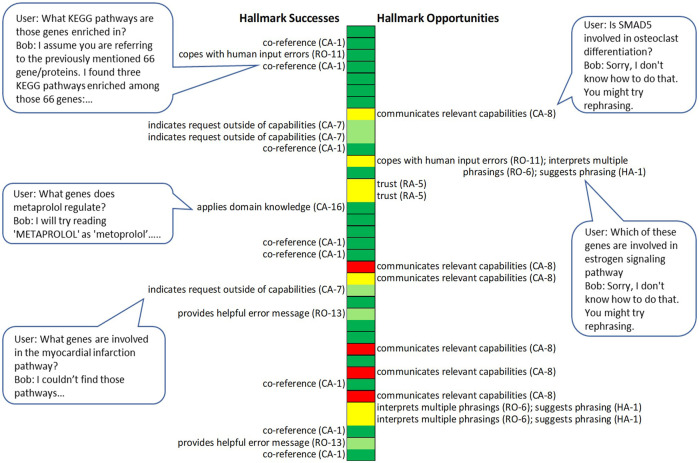
There is a growing desire to create computer systems that can collaborate with humans on complex, open-ended activities. These activities typically have no set completion criteria and frequently involve multimodal communication, extensive world knowledge, creativity, and building structures or compositions through multiple steps. Because these systems differ from question and answer (Q&A) systems, chatbots, and simple task-oriented assistants, new methods for evaluating such collaborative computer systems are needed. Here, we present a set of criteria for evaluating these systems, called Hallmarks of Human-Machine Collaboration. The Hallmarks build on the success of heuristic evaluation used by the user interface community and past evaluation techniques used in the spoken language and chatbot communities. They consist of observable characteristics indicative of successful collaborative communication, grouped into eight high-level properties: robustness; habitability; mutual contribution of meaningful content; context-awareness; consistent human engagement; provision of rationale; use of elementary concepts to teach and learn new concepts; and successful collaboration. We present examples of how we used these Hallmarks in the DARPA Communicating with Computers (CwC) program to evaluate diverse activities, including story and music generation, interactive building with blocks, and exploration of molecular mechanisms in cancer. We used the Hallmarks as guides for developers and as diagnostics, assessing systems with the Hallmarks to identify strengths and opportunities for improvement using logs from user studies, surveying the human partner, third-party review of creative products, and direct tests. Informal feedback from CwC technology developers indicates that the use of the Hallmarks for program evaluation helped guide development. The Hallmarks also made it possible to identify areas of progress and major gaps in developing systems where the machine is an equal, creative partner.
Keywords: assessment; collaborative assistants; dialogue; evaluation; human-machine teaming; multimodal.
Copyright © 2021 The MITRE Corporation.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures






References
-
- Abowd G. D., Dey A. K., Brown P. J., Davies N., Smith M., Steggles P. (1999). “Towards a Better Understanding of Context and Context-Awareness,” in Proceedings of the 1st International Symposium on Handheld and Ubiquitous Computing, Karlsruhe, Germany, September 27–29, 1999 (Berlin, Heidelberg: Springer-Verlag; ), 304–307. HUC ’99. 10.1007/3-540-48157-5_29 - DOI
-
- Adamopoulou E., Moussiades L. (2020). Chatbots: History, Technology, and Applications. Machine Learn. Appl. 2 (December), 100006. 10.1016/j.mlwa.2020.100006 - DOI
-
- Allen J., Hannah A., Bose R., de Beaumont W., Teng C. M. (2020). “A Broad-Coverage Deep Semantic Lexicon for Verbs,” in Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, May 11–16, 2020 (Marseille, France: European Language Resources Association; ), 3243–3251. https://www.aclweb.org/anthology/2020.lrec-1.396.
-
- Amershi S., Weld D., Vorvoreanu M., Fourney A., Nushi B., Collisson P., et al. (2019). “Guidelines for Human-AI Interaction,” in Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, United Kingdom, May 4–9, 2019 (New York, NY, USA: Association for Computing Machinery; ), 1–13. CHI ’19. 10.1145/3290605.3300233 - DOI
-
- Ammari T., Kaye J., Tsai J. Y., Bentley F. (2019). Music, Search, and IoT: How 922 People (Really) Use Voice Assistants. ACM Trans. Comput.-Hum. Interact. 26 (3), 1–28. 10.1145/3311956 - DOI
Publication types
LinkOut - more resources
Full Text Sources
Miscellaneous