

The data-index: An author-level metric that values impactful data and incentivizes data sharing
- PMID: 34765110
- PMCID: PMC8571609
- DOI: 10.1002/ece3.8126
The data-index: An author-level metric that values impactful data and incentivizes data sharing
Abstract
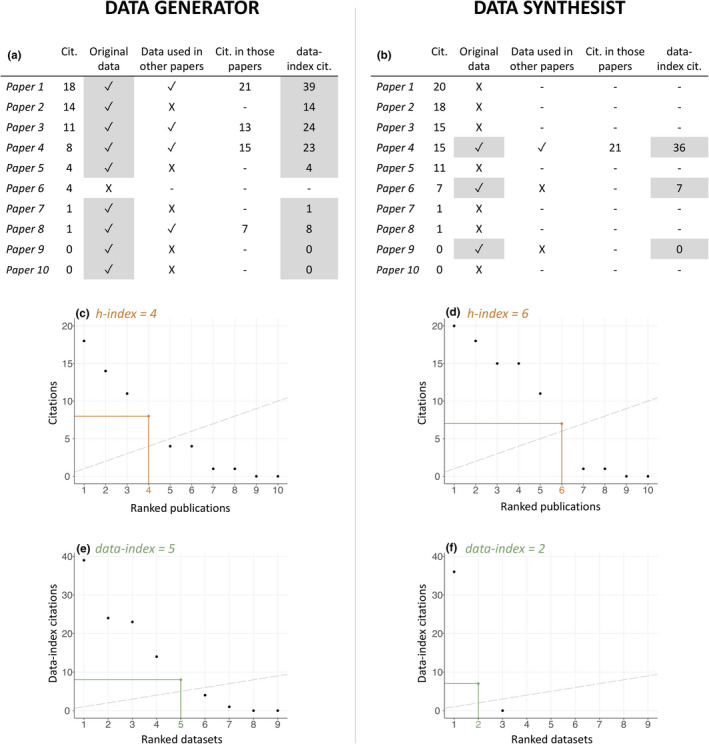
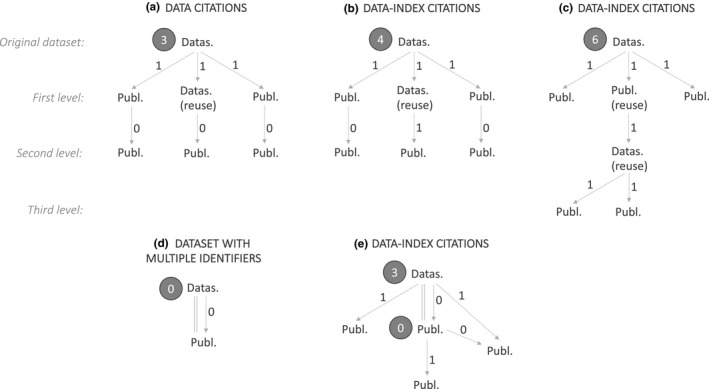
Author-level metrics are a widely used measure of scientific success. The h-index and its variants measure publication output (number of publications) and research impact (number of citations). They are often used to influence decisions, such as allocating funding or jobs. Here, we argue that the emphasis on publication output and impact hinders scientific progress in the fields of ecology and evolution because it disincentivizes two fundamental practices: generating impactful (and therefore often long-term) datasets and sharing data. We describe a new author-level metric, the data-index, which values both dataset output (number of datasets) and impact (number of data-index citations), so promotes generating and sharing data as a result. We discuss how it could be implemented and provide user guidelines. The data-index is designed to complement other metrics of scientific success, as scientific contributions are diverse and our value system should reflect that both for the benefit of scientific progress and to create a value system that is more equitable, diverse, and inclusive. Future work should focus on promoting other scientific contributions, such as communicating science, informing policy, mentoring other scientists, and providing open-access code and tools.
Keywords: FAIR research data; author‐level metrics; bibliometrics; data citation; data metrics; data sharing; dataset repositories; h‐index; open science.
© 2021 The Authors. Ecology and Evolution published by John Wiley & Sons Ltd.
Conflict of interest statement
None declared.
Figures
References
-
- Barto, E. K. , & Rillig, M. C. (2012). Dissemination biases in ecology: Effect sizes matter more than quality. Oikos, 121, 228–235. 10.1111/j.1600-0706.2011.19401.x - DOI
LinkOut - more resources
Full Text Sources
