

Adaptive kernel fuzzy clustering for missing data
- PMID: 34767560
- PMCID: PMC8589222
- DOI: 10.1371/journal.pone.0259266
Adaptive kernel fuzzy clustering for missing data
Abstract
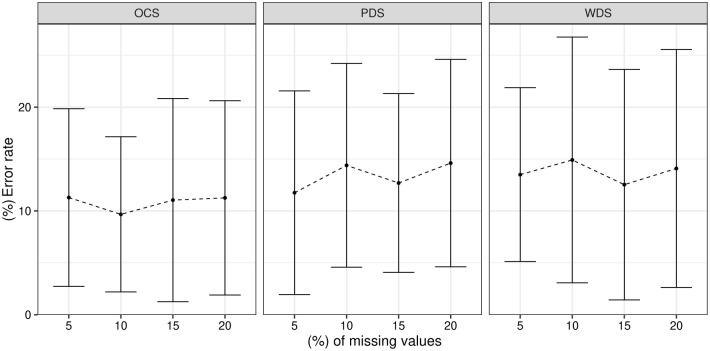
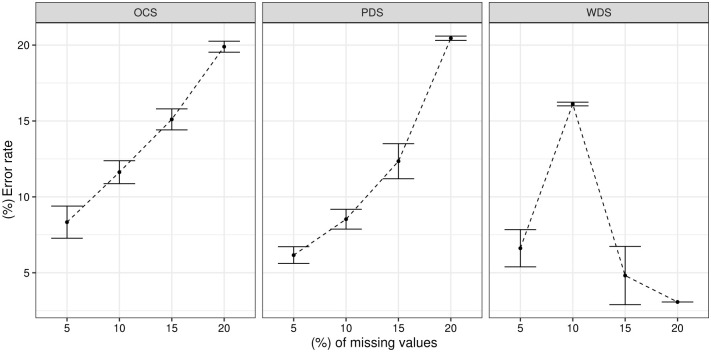
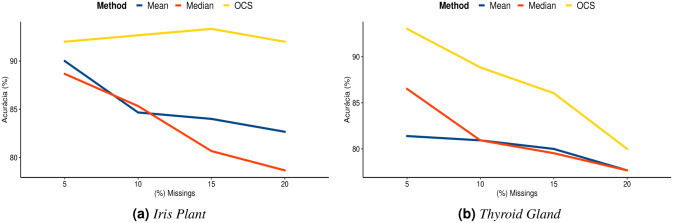
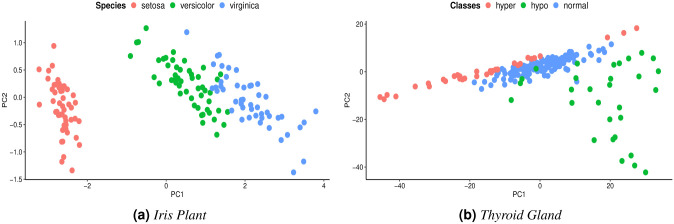
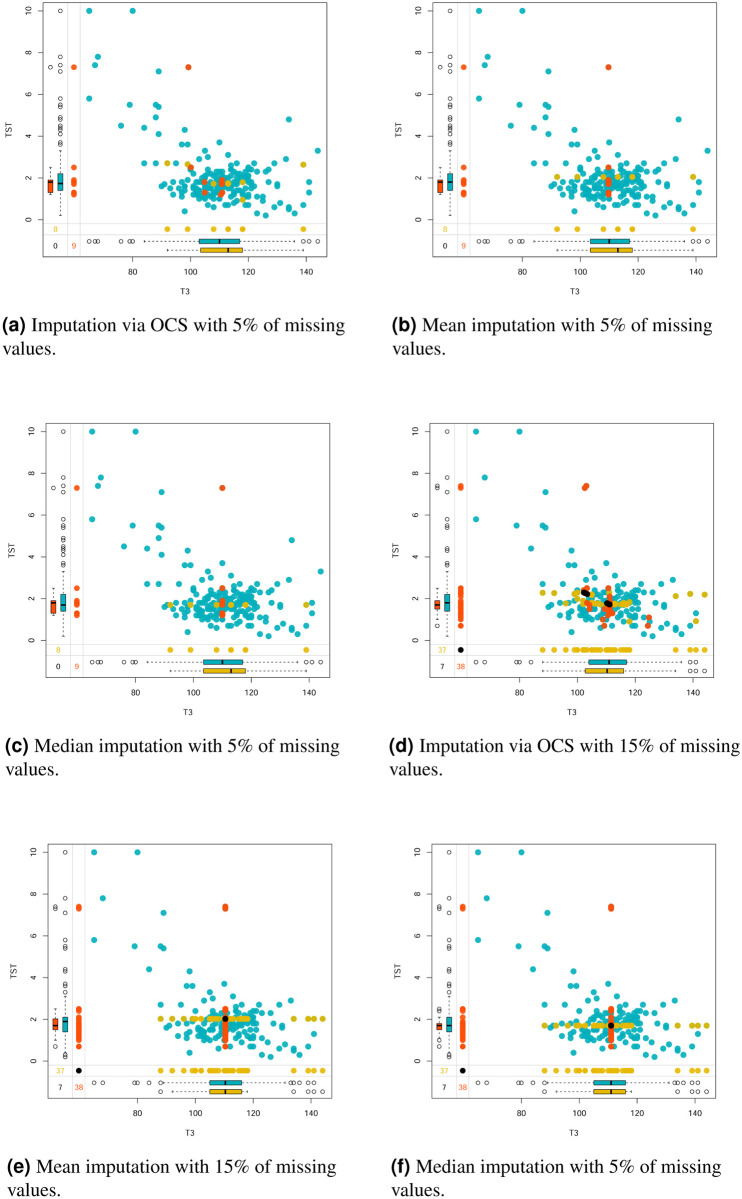
Many machine learning procedures, including clustering analysis are often affected by missing values. This work aims to propose and evaluate a Kernel Fuzzy C-means clustering algorithm considering the kernelization of the metric with local adaptive distances (VKFCM-K-LP) under three types of strategies to deal with missing data. The first strategy, called Whole Data Strategy (WDS), performs clustering only on the complete part of the dataset, i.e. it discards all instances with missing data. The second approach uses the Partial Distance Strategy (PDS), in which partial distances are computed among all available resources and then re-scaled by the reciprocal of the proportion of observed values. The third technique, called Optimal Completion Strategy (OCS), computes missing values iteratively as auxiliary variables in the optimization of a suitable objective function. The clustering results were evaluated according to different metrics. The best performance of the clustering algorithm was achieved under the PDS and OCS strategies. Under the OCS approach, new datasets were derive and the missing values were estimated dynamically in the optimization process. The results of clustering under the OCS strategy also presented a superior performance when compared to the resulting clusters obtained by applying the VKFCM-K-LP algorithm on a version where missing values are previously imputed by the mean or the median of the observed values.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
Similar articles
-
A generalized fuzzy clustering framework for incomplete data by integrating feature weighted and kernel learning.PeerJ Comput Sci. 2023 Oct 5;9:e1600. doi: 10.7717/peerj-cs.1600. eCollection 2023. PeerJ Comput Sci. 2023. PMID: 37869452 Free PMC article.
-
Fuzzy K-means clustering with missing values.Proc AMIA Symp. 2001:588-92. Proc AMIA Symp. 2001. PMID: 11825255 Free PMC article.
-
Apache Spark based kernelized fuzzy clustering framework for single nucleotide polymorphism sequence analysis.Comput Biol Chem. 2021 Jun;92:107454. doi: 10.1016/j.compbiolchem.2021.107454. Epub 2021 Feb 10. Comput Biol Chem. 2021. PMID: 33684695
-
A multiple kernel density clustering algorithm for incomplete datasets in bioinformatics.BMC Syst Biol. 2018 Nov 22;12(Suppl 6):111. doi: 10.1186/s12918-018-0630-6. BMC Syst Biol. 2018. PMID: 30463619 Free PMC article.
-
Fuzzy ensemble clustering based on random projections for DNA microarray data analysis.Artif Intell Med. 2009 Feb-Mar;45(2-3):173-83. doi: 10.1016/j.artmed.2008.07.014. Epub 2008 Sep 17. Artif Intell Med. 2009. PMID: 18801650
References
-
- Estivill-Castro V. Why so many clustering algorithms: a position paper. SIGKDD explorations. 2002;4(1):65–75. doi: 10.1145/568574.568575 - DOI
-
- Shen H, Yang J, Wang S, Liu X. Attribute weighted mercer kernel based fuzzy clustering algorithm for general non-spherical datasets. Soft Computing. 2006;10(11):1061–1073. doi: 10.1007/s00500-005-0043-5 - DOI
-
- Jain AK, Murty MN, Flynn PJ. Data clustering: a review. ACM computing surveys (CSUR). 1999;31(3):264–323. doi: 10.1145/331499.331504 - DOI
-
- Filippone M, Camastra F, Masulli F, Rovetta S. A survey of kernel and spectral methods for clustering. Pattern recognition. 2008;41(1):176–190. doi: 10.1016/j.patcog.2007.05.018 - DOI
MeSH terms
LinkOut - more resources
Full Text Sources
Miscellaneous
