

Characterization of Genetically Modified Microorganisms Using Short- and Long-Read Whole-Genome Sequencing Reveals Contaminations of Related Origin in Multiple Commercial Food Enzyme Products
- PMID: 34828918
- PMCID: PMC8624754
- DOI: 10.3390/foods10112637
Characterization of Genetically Modified Microorganisms Using Short- and Long-Read Whole-Genome Sequencing Reveals Contaminations of Related Origin in Multiple Commercial Food Enzyme Products
Abstract
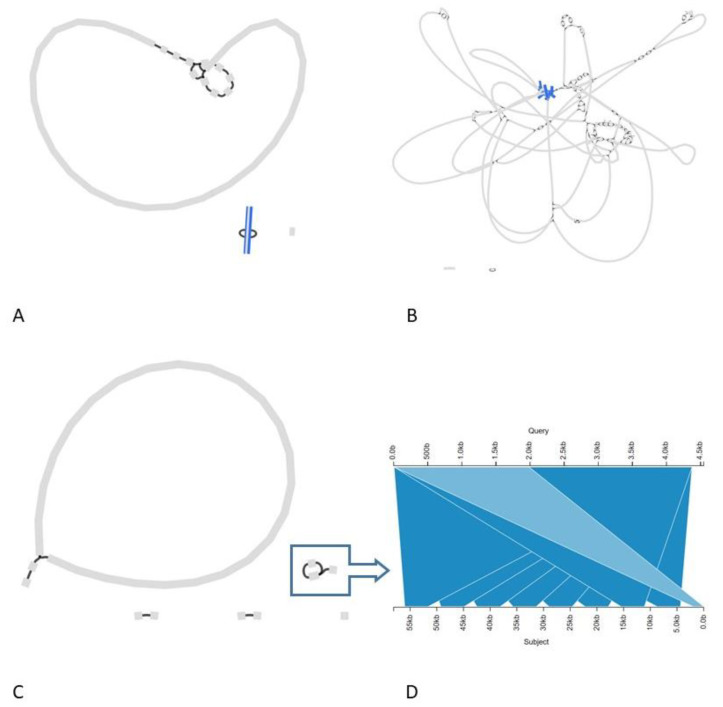
Despite their presence being unauthorized on the European market, contaminations with genetically modified (GM) microorganisms have repeatedly been reported in diverse commercial microbial fermentation produce types. Several of these contaminations are related to a GM Bacillus velezensis used to synthesize a food enzyme protease, for which genomic characterization remains currently incomplete, and it is unknown whether these contaminations have a common origin. In this study, GM B. velezensis isolates from multiple food enzyme products were characterized by short- and long-read whole-genome sequencing (WGS), demonstrating that they harbor a free recombinant pUB110-derived plasmid carrying antimicrobial resistance genes. Additionally, single-nucleotide polymorphism (SNP) and whole-genome based comparative analyses showed that the isolates likely originate from the same parental GM strain. This study highlights the added value of a hybrid WGS approach for accurate genomic characterization of GMM (e.g., genomic location of the transgenic construct), and of SNP-based phylogenomic analysis for source-tracking of GMM.
Keywords: Bacillus velezensis; SNP phylogenomic analysis; food enzyme; genetically modified microorganism (GMM); hybrid genome assembly; whole-genome sequencing.
Conflict of interest statement
The authors declare no conflict of interest.
Figures



Similar articles
-
Metagenomics-based tracing of genetically modified microorganism contaminations in commercial fermentation products.Food Chem (Oxf). 2024 Dec 24;10:100236. doi: 10.1016/j.fochms.2024.100236. eCollection 2025 Jun. Food Chem (Oxf). 2024. PMID: 39834589 Free PMC article.
-
Metagenomic Characterization of Multiple Genetically Modified Bacillus Contaminations in Commercial Microbial Fermentation Products.Life (Basel). 2022 Nov 25;12(12):1971. doi: 10.3390/life12121971. Life (Basel). 2022. PMID: 36556336 Free PMC article.
-
DNA walking strategy to identify unauthorized genetically modified bacteria in microbial fermentation products.Int J Food Microbiol. 2021 Jan 16;337:108913. doi: 10.1016/j.ijfoodmicro.2020.108913. Epub 2020 Oct 21. Int J Food Microbiol. 2021. PMID: 33126077
-
Genetically Modified Micro-Organisms for Industrial Food Enzyme Production: An Overview.Foods. 2020 Mar 11;9(3):326. doi: 10.3390/foods9030326. Foods. 2020. PMID: 32168815 Free PMC article. Review.
-
Safety and nutritional assessment of GM plants and derived food and feed: the role of animal feeding trials.Food Chem Toxicol. 2008 Mar;46 Suppl 1:S2-70. doi: 10.1016/j.fct.2008.02.008. Epub 2008 Feb 13. Food Chem Toxicol. 2008. PMID: 18328408 Review.
Cited by
-
Comparison of 6 DNA extraction methods for isolation of high yield of high molecular weight DNA suitable for shotgun metagenomics Nanopore sequencing to detect bacteria.BMC Genomics. 2023 Aug 4;24(1):438. doi: 10.1186/s12864-023-09537-5. BMC Genomics. 2023. PMID: 37537550 Free PMC article.
-
Metagenomics-based tracing of genetically modified microorganism contaminations in commercial fermentation products.Food Chem (Oxf). 2024 Dec 24;10:100236. doi: 10.1016/j.fochms.2024.100236. eCollection 2025 Jun. Food Chem (Oxf). 2024. PMID: 39834589 Free PMC article.
-
Metagenomic Characterization of Multiple Genetically Modified Bacillus Contaminations in Commercial Microbial Fermentation Products.Life (Basel). 2022 Nov 25;12(12):1971. doi: 10.3390/life12121971. Life (Basel). 2022. PMID: 36556336 Free PMC article.
-
Assessing the authenticity and purity of a commercial Bacillus thuringiensis bioinsecticide through whole genome sequencing and metagenomics approaches.Front Microbiol. 2025 Jan 31;16:1532788. doi: 10.3389/fmicb.2025.1532788. eCollection 2025. Front Microbiol. 2025. PMID: 39963497 Free PMC article.
-
Pilot market surveillance of GMM contaminations in alpha-amylase food enzyme products: A detection strategy strengthened by a newly developed qPCR method targeting a GM Bacillus licheniformis producing alpha-amylase.Food Chem (Oxf). 2023 Dec 6;8:100186. doi: 10.1016/j.fochms.2023.100186. eCollection 2024 Jul 30. Food Chem (Oxf). 2023. PMID: 38179151 Free PMC article.
References
-
- Fraiture M.-A., Bogaerts B., Winand R., Deckers M., Papazova N., Vanneste K., de Keersmaecker S.C.J., Roosens N.H.C. Identification of an unauthorized genetically modified bacteria in food enzyme through whole-genome sequencing. Sci. Rep. 2020;10:7094. doi: 10.1038/s41598-020-63987-5. - DOI - PMC - PubMed
-
- Fraiture M.-A., Deckers M., Papazova N., Roosens N.H.C. Detection strategy targeting a chloramphenicol resistance gene from genetically modified bacteria in food and feed products. Food Control. 2020;108:106873. doi: 10.1016/j.foodcont.2019.106873. - DOI
-
- Fraiture M.-A., Deckers M., Papazova N., Roosens N.H.C. Strategy to detect genetically modified bacteria carrying tetracycline resistance gene in fermentation products. Food Anal. Methods. 2020;13:1929–1937. doi: 10.1007/s12161-020-01803-6. - DOI
LinkOut - more resources
Full Text Sources
