

Deep co-supervision and attention fusion strategy for automatic COVID-19 lung infection segmentation on CT images
- PMID: 34848897
- PMCID: PMC8612757
- DOI: 10.1016/j.patcog.2021.108452
Deep co-supervision and attention fusion strategy for automatic COVID-19 lung infection segmentation on CT images
Abstract
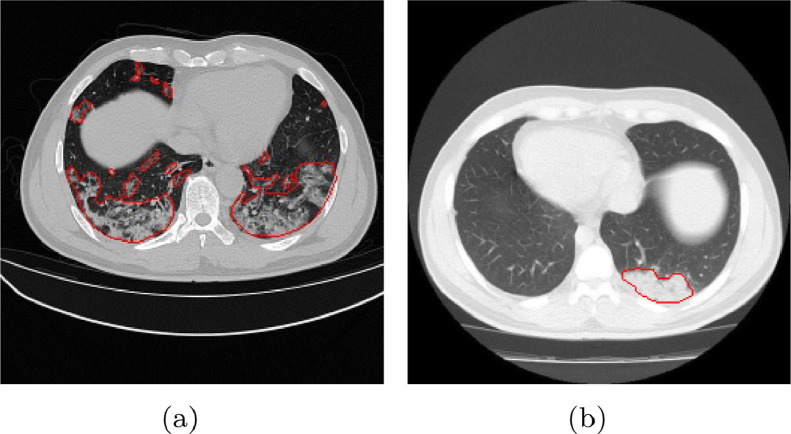
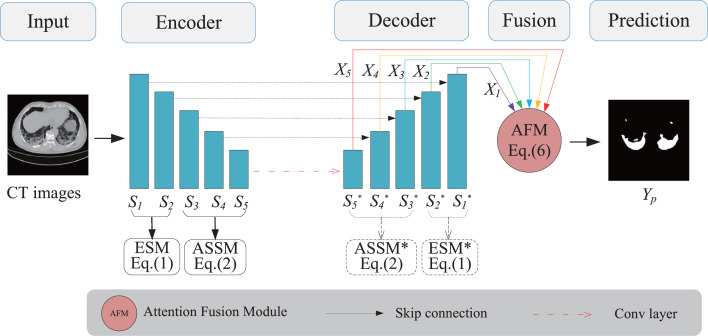
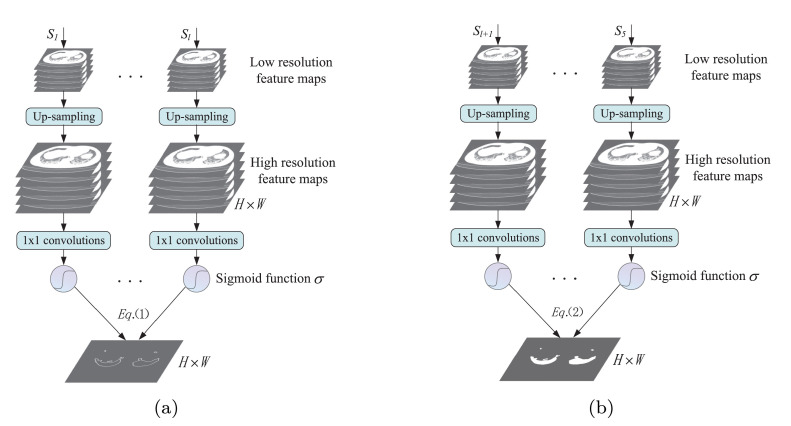
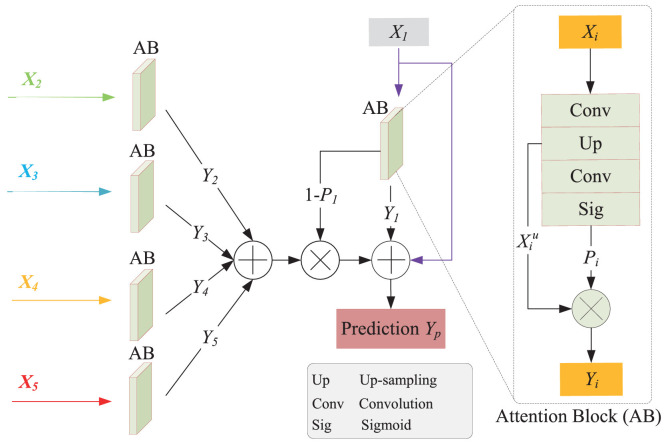
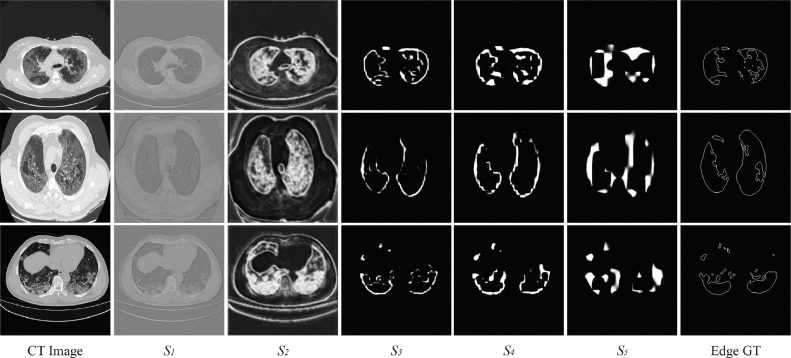
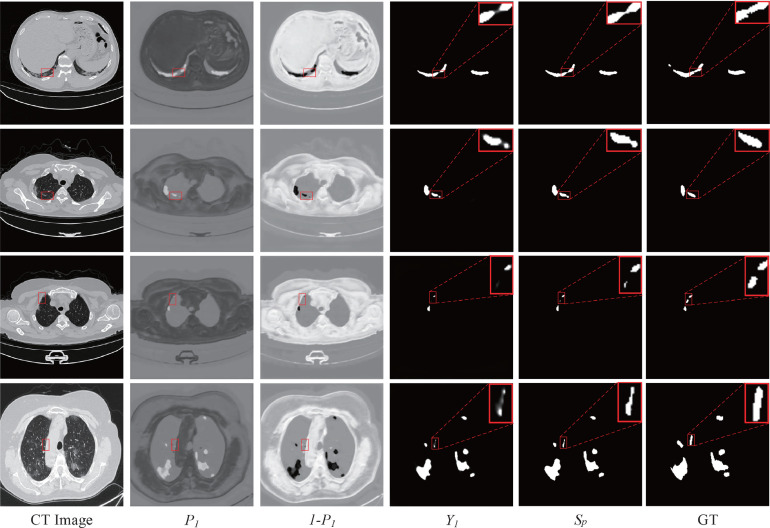
Due to the irregular shapes,various sizes and indistinguishable boundaries between the normal and infected tissues, it is still a challenging task to accurately segment the infected lesions of COVID-19 on CT images. In this paper, a novel segmentation scheme is proposed for the infections of COVID-19 by enhancing supervised information and fusing multi-scale feature maps of different levels based on the encoder-decoder architecture. To this end, a deep collaborative supervision (Co-supervision) scheme is proposed to guide the network learning the features of edges and semantics. More specifically, an Edge Supervised Module (ESM) is firstly designed to highlight low-level boundary features by incorporating the edge supervised information into the initial stage of down-sampling. Meanwhile, an Auxiliary Semantic Supervised Module (ASSM) is proposed to strengthen high-level semantic information by integrating mask supervised information into the later stage. Then an Attention Fusion Module (AFM) is developed to fuse multiple scale feature maps of different levels by using an attention mechanism to reduce the semantic gaps between high-level and low-level feature maps. Finally, the effectiveness of the proposed scheme is demonstrated on four various COVID-19 CT datasets. The results show that the proposed three modules are all promising. Based on the baseline (ResUnet), using ESM, ASSM, or AFM alone can respectively increase Dice metric by 1.12%, 1.95%,1.63% in our dataset, while the integration by incorporating three models together can rise 3.97%. Compared with the existing approaches in various datasets, the proposed method can obtain better segmentation performance in some main metrics, and can achieve the best generalization and comprehensive performance.
Keywords: Attention mechanism; COVID-19; Feature fusion; Multi-scale features; Semantic segmentation.
© 2021 Elsevier Ltd. All rights reserved.
Conflict of interest statement
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Figures



References
-
- He K., Zhao W., Xie X., Ji W., Liu M., Tang Z., Shi Y., Shi F., Gao Y., Liu J., Zhang J., Shen D. Synergistic learning of lung lobe segmentation and hierarchical multi-instance classification for automated severity assessment of COVID-19 in CT images. Pattern Recognit. 2021;113:107828. - PMC - PubMed
LinkOut - more resources
Full Text Sources
Miscellaneous