

Modeling the effects of age and hearing loss on concurrent vowel scores
- PMID: 34852572
- PMCID: PMC8594952
- DOI: 10.1121/10.0007046
Modeling the effects of age and hearing loss on concurrent vowel scores
Abstract
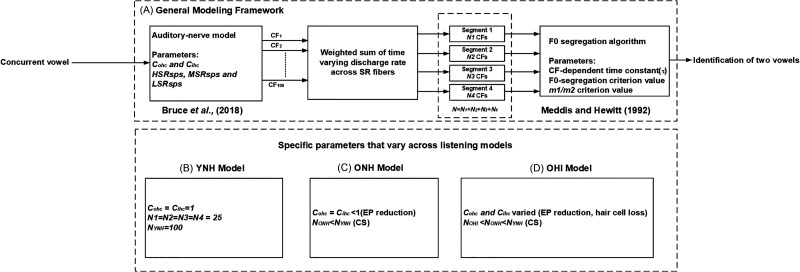
A difference in fundamental frequency (F0) between two vowels is an important segregation cue prior to identifying concurrent vowels. To understand the effects of this cue on identification due to age and hearing loss, Chintanpalli, Ahlstrom, and Dubno [(2016). J. Acoust. Soc. Am. 140, 4142-4153] collected concurrent vowel scores across F0 differences for younger adults with normal hearing (YNH), older adults with normal hearing (ONH), and older adults with hearing loss (OHI). The current modeling study predicts these concurrent vowel scores to understand age and hearing loss effects. The YNH model cascaded the temporal responses of an auditory-nerve model from Bruce, Efrani, and Zilany [(2018). Hear. Res. 360, 40-45] with a modified F0-guided segregation algorithm from Meddis and Hewitt [(1992). J. Acoust. Soc. Am. 91, 233-245] to predict concurrent vowel scores. The ONH model included endocochlear-potential loss, while the OHI model also included hair cell damage; however, both models incorporated cochlear synaptopathy, with a larger effect for OHI. Compared with the YNH model, concurrent vowel scores were reduced across F0 differences for ONH and OHI models, with the lowest scores for OHI. These patterns successfully captured the age and hearing loss effects in the concurrent-vowel data. The predictions suggest that the inability to utilize an F0-guided segregation cue, resulting from peripheral changes, may reduce scores for ONH and OHI listeners.
Figures




Similar articles
-
Modeling the level-dependent changes of concurrent vowel scores.J Acoust Soc Am. 2018 Jan;143(1):440. doi: 10.1121/1.5021330. J Acoust Soc Am. 2018. PMID: 29390795 Free PMC article.
-
Effects of age and hearing loss on concurrent vowel identification.J Acoust Soc Am. 2016 Dec;140(6):4142. doi: 10.1121/1.4968781. J Acoust Soc Am. 2016. PMID: 28040038 Free PMC article.
-
Computational model predictions of cues for concurrent vowel identification.J Assoc Res Otolaryngol. 2014 Oct;15(5):823-37. doi: 10.1007/s10162-014-0475-7. Epub 2014 Jul 8. J Assoc Res Otolaryngol. 2014. PMID: 25002128 Free PMC article.
-
Modeling the perception of concurrent vowels: Role of formant transitions.J Acoust Soc Am. 1996 Aug;100(2 Pt 1):1141-52. doi: 10.1121/1.416299. J Acoust Soc Am. 1996. PMID: 8759967
-
The use of confusion patterns to evaluate the neural basis for concurrent vowel identification.J Acoust Soc Am. 2013 Oct;134(4):2988-3000. doi: 10.1121/1.4820888. J Acoust Soc Am. 2013. PMID: 24116434 Free PMC article.
References
-
- Arehart, K. H. , Arriaga, C. , Kelly, K. , and Mclean-Mudgett, S. (1997). “ Role of fundamental frequency differences in the perceptual separation of competing vowel sounds by listeners with normal hearing and listeners with hearing loss,” J. Speech, Lang. Hear. Res. 40, 1434–1444.10.1044/jslhr.4006.1434 - DOI - PubMed
-
- Arehart, K. H. , Rossi-Katz, J. , and Swensson-Prutsman, J. (2005). “ Double-vowel perception in listeners with cochlear hearing loss: Differences in fundamental frequency, ear of presentation, and relative amplitude,” J. Speech. Lang. Hear. Res. 48, 236–252.10.1044/1092-4388(2005/017) - DOI - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical