

Toward Generalizability in the Deployment of Artificial Intelligence in Radiology: Role of Computation Stress Testing to Overcome Underspecification
- PMID: 34870222
- PMCID: PMC8637230
- DOI: 10.1148/ryai.2021210097
Toward Generalizability in the Deployment of Artificial Intelligence in Radiology: Role of Computation Stress Testing to Overcome Underspecification
Abstract
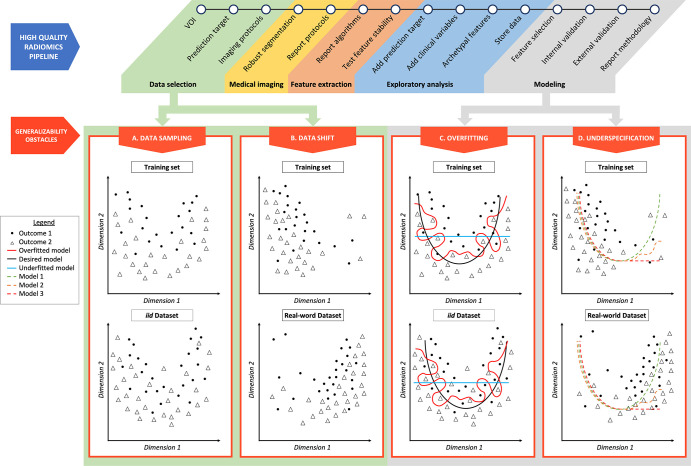
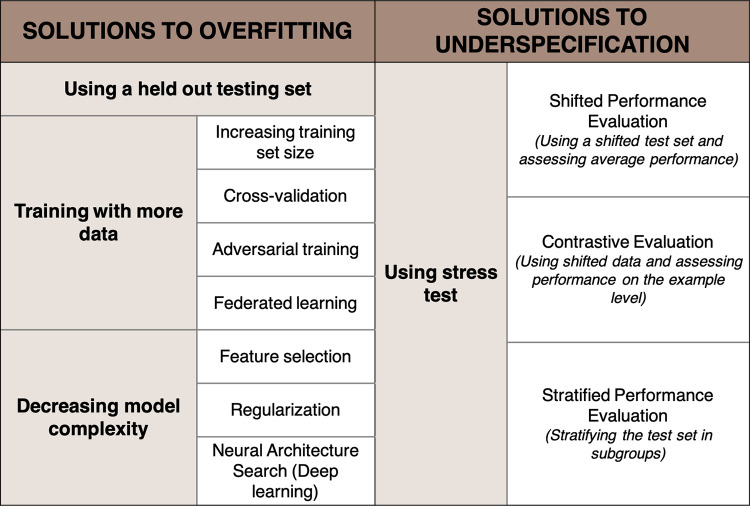
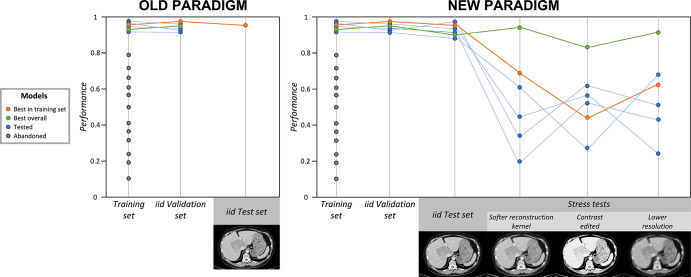
The clinical deployment of artificial intelligence (AI) applications in medical imaging is perhaps the greatest challenge facing radiology in the next decade. One of the main obstacles to the incorporation of automated AI-based decision-making tools in medicine is the failure of models to generalize when deployed across institutions with heterogeneous populations and imaging protocols. The most well-understood pitfall in developing these AI models is overfitting, which has, in part, been overcome by optimizing training protocols. However, overfitting is not the only obstacle to the success and generalizability of AI. Underspecification is also a serious impediment that requires conceptual understanding and correction. It is well known that a single AI pipeline, with prescribed training and testing sets, can produce several models with various levels of generalizability. Underspecification defines the inability of the pipeline to identify whether these models have embedded the structure of the underlying system by using a test set independent of, but distributed identically, to the training set. An underspecified pipeline is unable to assess the degree to which the models will be generalizable. Stress testing is a known tool in AI that can limit underspecification and, importantly, assure broad generalizability of AI models. However, the application of stress tests is new in radiologic applications. This report describes the concept of underspecification from a radiologist perspective, discusses stress testing as a specific strategy to overcome underspecification, and explains how stress tests could be designed in radiology-by modifying medical images or stratifying testing datasets. In the upcoming years, stress tests should become in radiology the standard that crash tests have become in the automotive industry. Keywords: Computer Applications-General, Informatics, Computer-aided Diagnosis © RSNA, 2021.
Keywords: Computer Applications-General; Computer-aided Diagnosis; Informatics.
2021 by the Radiological Society of North America, Inc.
Conflict of interest statement
Disclosures of conflicts of interest: T.E. No relevant relationships. L.H.S. Consultant for Merck and Regeneron (member, DSMB and endpoint analysis committees). F.Z.M. No relevant relationships. L.D. No relevant relationships.
Figures
References
-
- Bluemke DA, Moy L, Bredella MA, et al. . Assessing radiology research on artificial intelligence: a brief guide for authors, reviewers, and readers—from the Radiology editorial board. Radiology 2020;294(3):487–489. - PubMed
-
- Collins GS, Reitsma JB, Altman DG, Moons KGM;Members of the TRIPOD Group . Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): the TRIPOD statement. Eur Urol 2015;67(6):1142–1151. - PubMed
-
- Park SH, Han K. Methodologic guide for evaluating clinical performance and effect of artificial intelligence technology for medical diagnosis and prediction. Radiology 2018;286(3):800–809. - PubMed
-
- Soffer S, Ben-Cohen A, Shimon O, Amitai MM, Greenspan H, Klang E. Convolutional neural networks for radiologic images: a radiologist's guide. Radiology 2019;290(3):590–606. - PubMed
-
- Chang PJ. Moving artificial intelligence from feasible to real: time to drill for gas and build roads. Radiology 2020;294(2):432–433. - PubMed
LinkOut - more resources
Full Text Sources
