

Multi-omic machine learning predictor of breast cancer therapy response
- PMID: 34875674
- PMCID: PMC8791834
- DOI: 10.1038/s41586-021-04278-5
Multi-omic machine learning predictor of breast cancer therapy response
Abstract
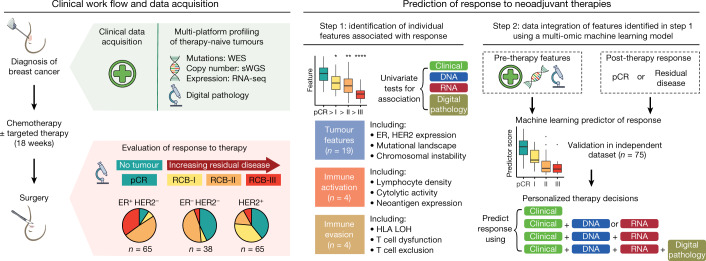
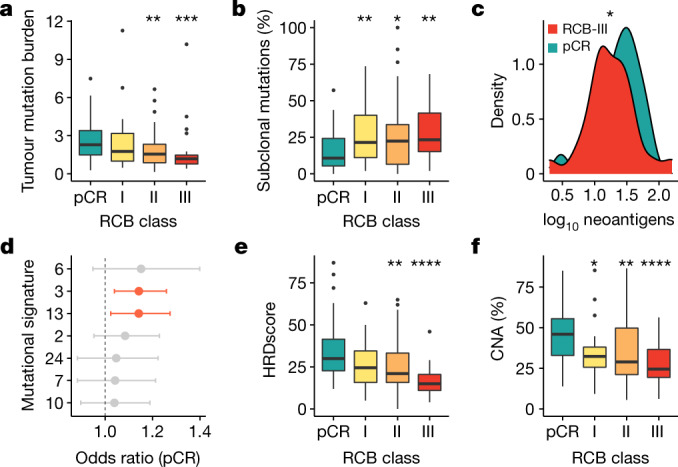
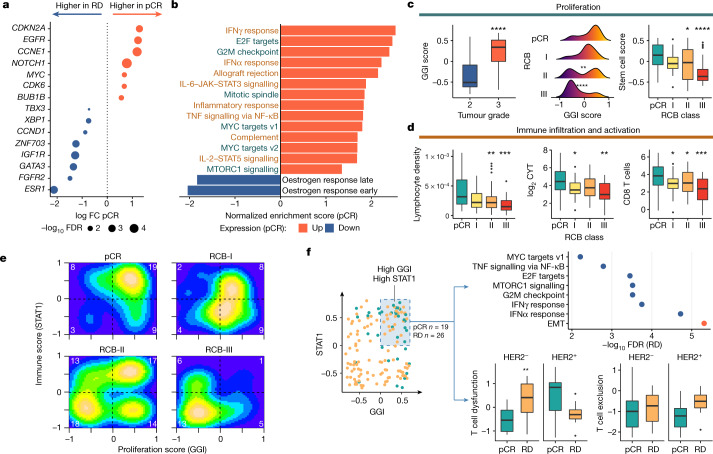
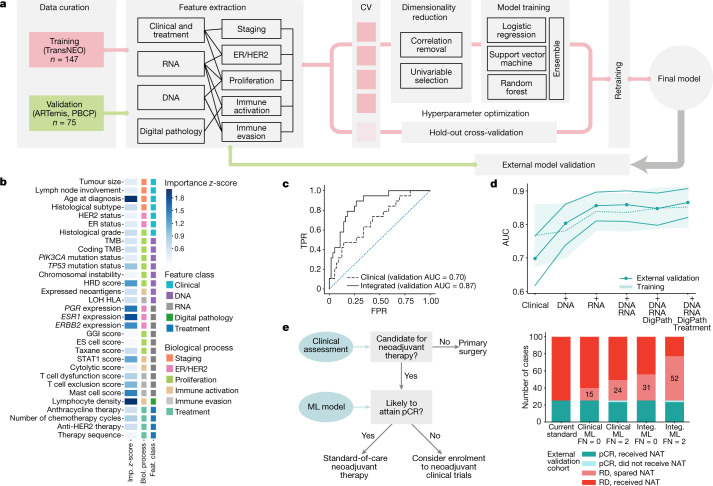
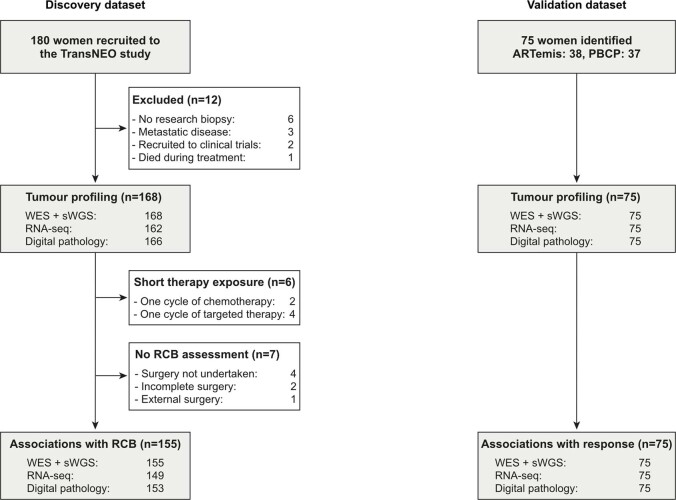
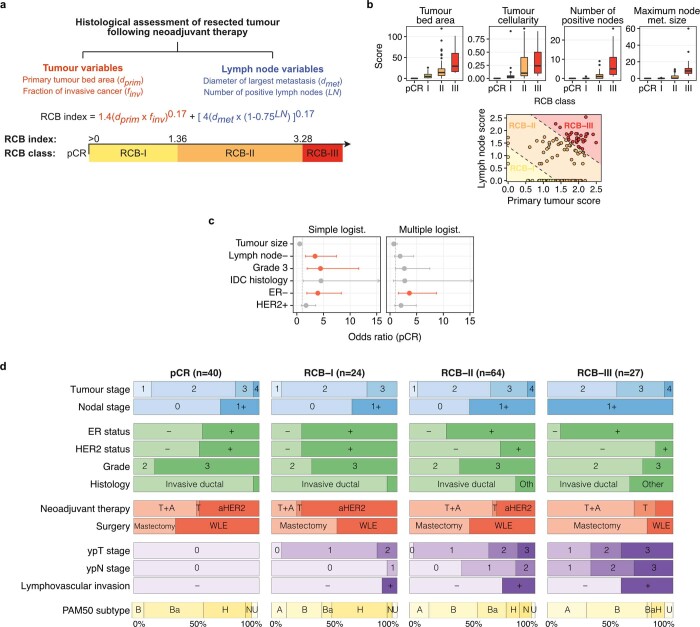
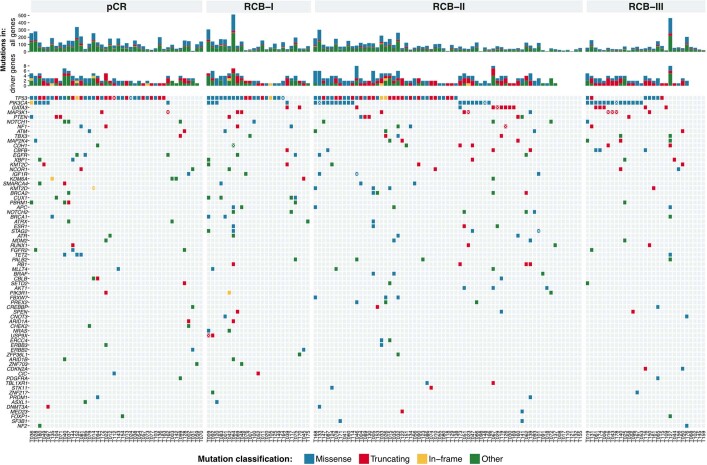
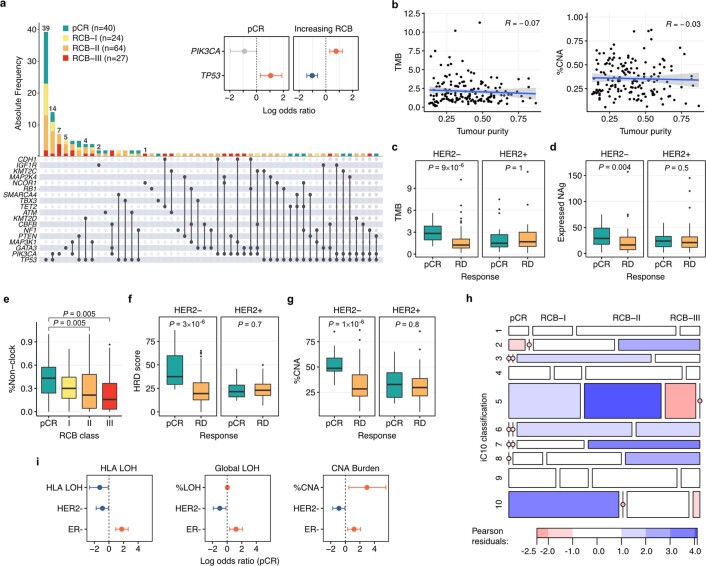
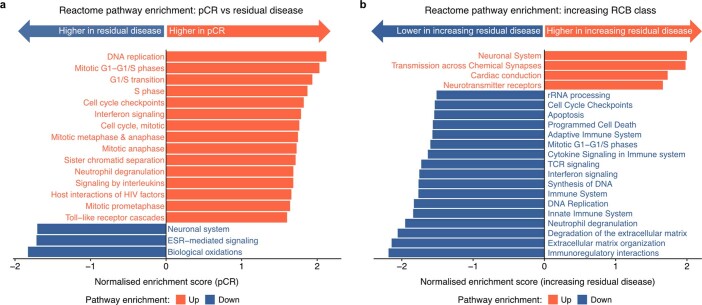
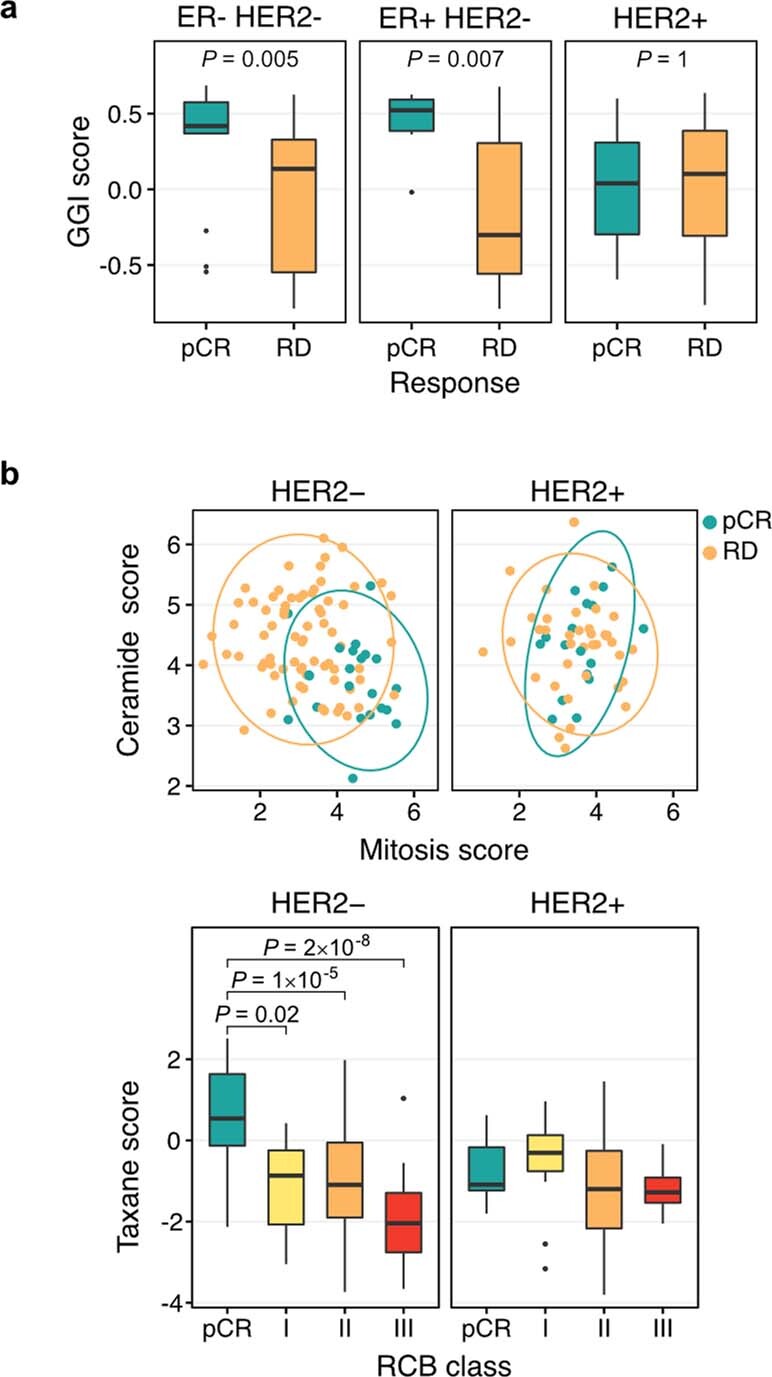
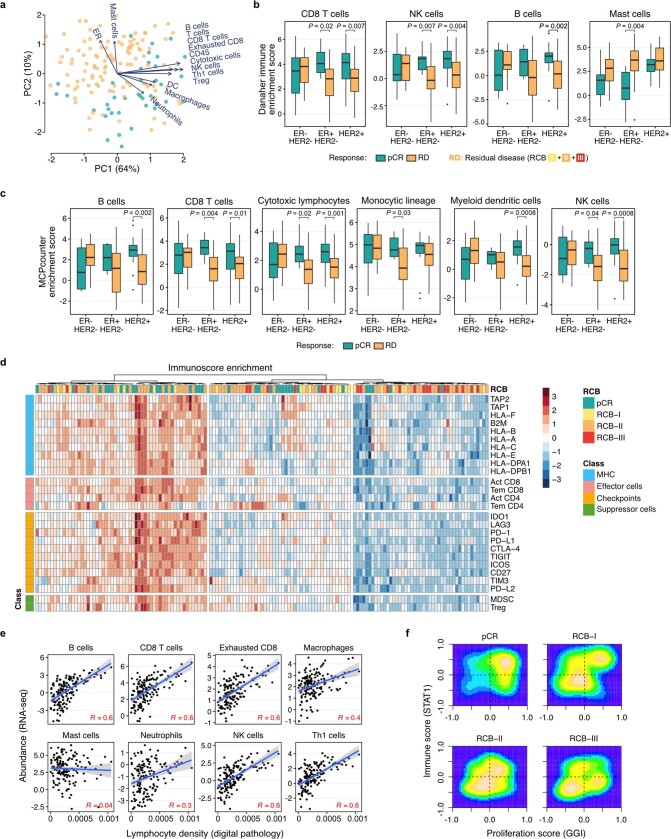
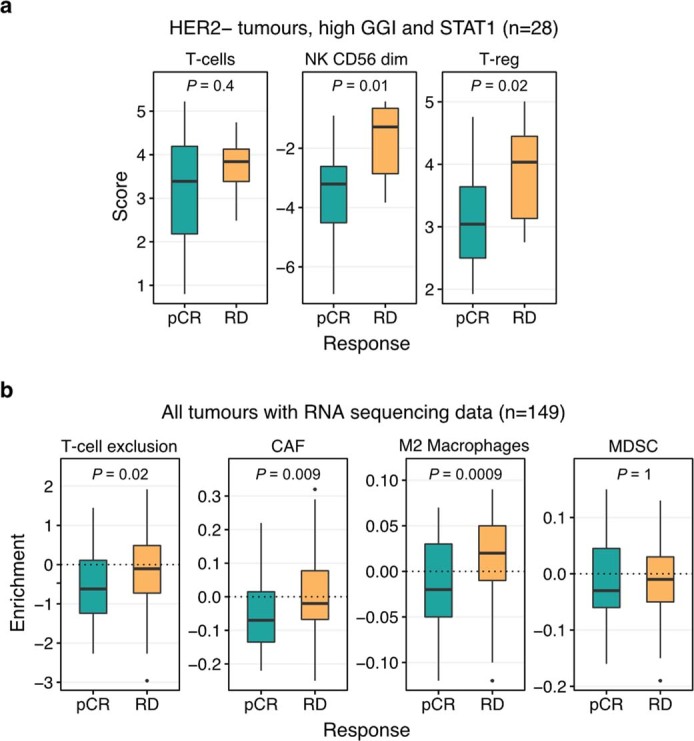
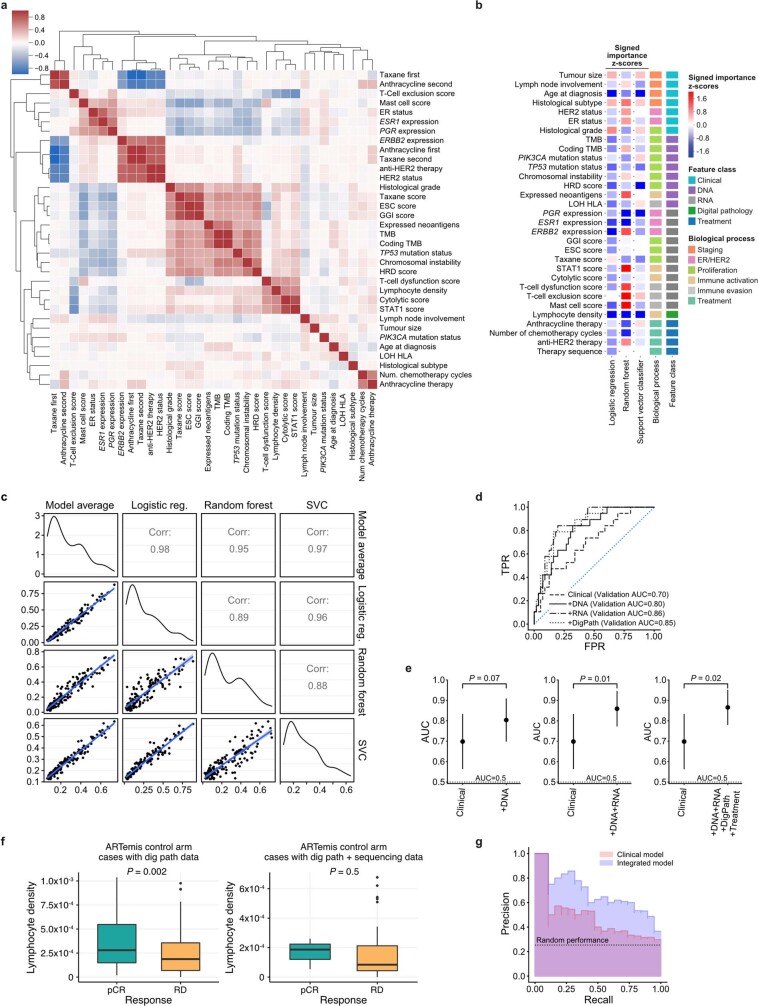
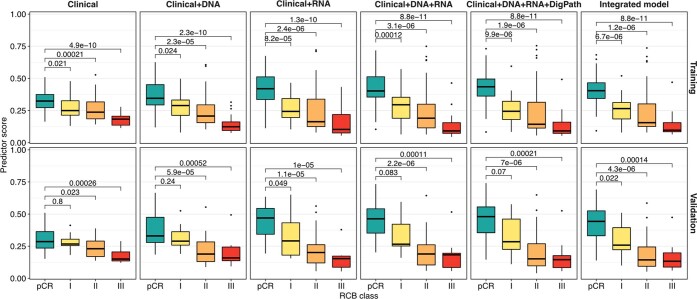
Breast cancers are complex ecosystems of malignant cells and the tumour microenvironment1. The composition of these tumour ecosystems and interactions within them contribute to responses to cytotoxic therapy2. Efforts to build response predictors have not incorporated this knowledge. We collected clinical, digital pathology, genomic and transcriptomic profiles of pre-treatment biopsies of breast tumours from 168 patients treated with chemotherapy with or without HER2 (encoded by ERBB2)-targeted therapy before surgery. Pathology end points (complete response or residual disease) at surgery3 were then correlated with multi-omic features in these diagnostic biopsies. Here we show that response to treatment is modulated by the pre-treated tumour ecosystem, and its multi-omics landscape can be integrated in predictive models using machine learning. The degree of residual disease following therapy is monotonically associated with pre-therapy features, including tumour mutational and copy number landscapes, tumour proliferation, immune infiltration and T cell dysfunction and exclusion. Combining these features into a multi-omic machine learning model predicted a pathological complete response in an external validation cohort (75 patients) with an area under the curve of 0.87. In conclusion, response to therapy is determined by the baseline characteristics of the totality of the tumour ecosystem captured through data integration and machine learning. This approach could be used to develop predictors for other cancers.
© 2021. The Author(s).
Conflict of interest statement
C.C. is a member of the iMED External Science Panel for AstraZeneca, a member of the Scientific Advisory Board for Illumina and a recipient of research grants (administered by the University of Cambridge) from Genentech, Roche, AstraZeneca and Servier. M.C.-O. has received research funding from Lilly. All other authors declare no competing interests.
Figures
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
Molecular Biology Databases
Research Materials
Miscellaneous
