

Underdiagnosis bias of artificial intelligence algorithms applied to chest radiographs in under-served patient populations
- PMID: 34893776
- PMCID: PMC8674135
- DOI: 10.1038/s41591-021-01595-0
Underdiagnosis bias of artificial intelligence algorithms applied to chest radiographs in under-served patient populations
Abstract
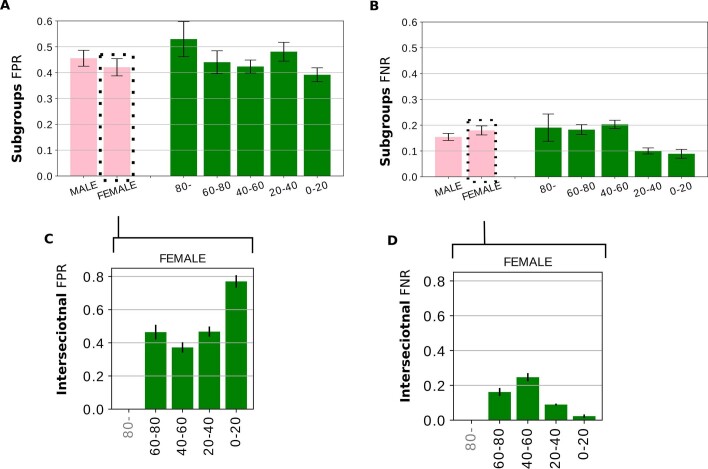
Artificial intelligence (AI) systems have increasingly achieved expert-level performance in medical imaging applications. However, there is growing concern that such AI systems may reflect and amplify human bias, and reduce the quality of their performance in historically under-served populations such as female patients, Black patients, or patients of low socioeconomic status. Such biases are especially troubling in the context of underdiagnosis, whereby the AI algorithm would inaccurately label an individual with a disease as healthy, potentially delaying access to care. Here, we examine algorithmic underdiagnosis in chest X-ray pathology classification across three large chest X-ray datasets, as well as one multi-source dataset. We find that classifiers produced using state-of-the-art computer vision techniques consistently and selectively underdiagnosed under-served patient populations and that the underdiagnosis rate was higher for intersectional under-served subpopulations, for example, Hispanic female patients. Deployment of AI systems using medical imaging for disease diagnosis with such biases risks exacerbation of existing care biases and can potentially lead to unequal access to medical treatment, thereby raising ethical concerns for the use of these models in the clinic.
© 2021. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
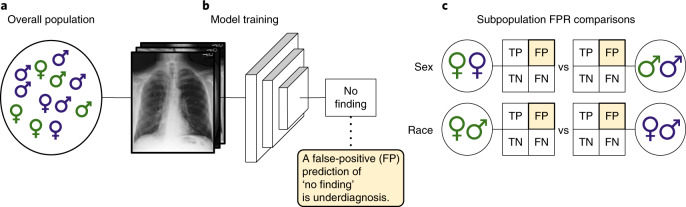
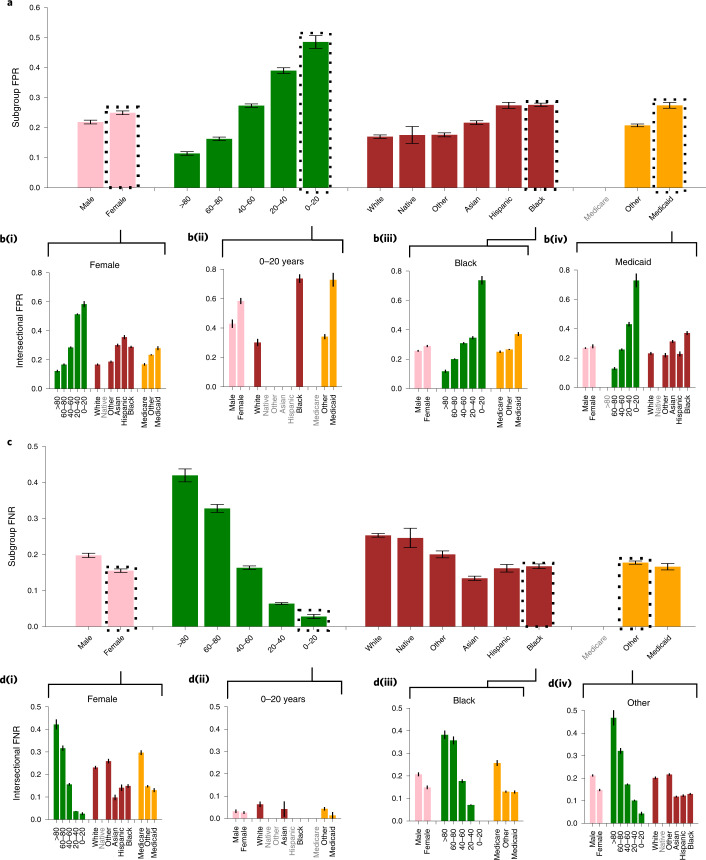
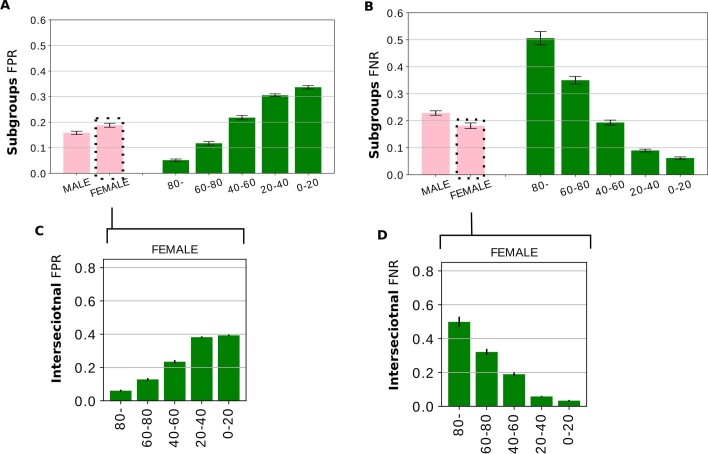
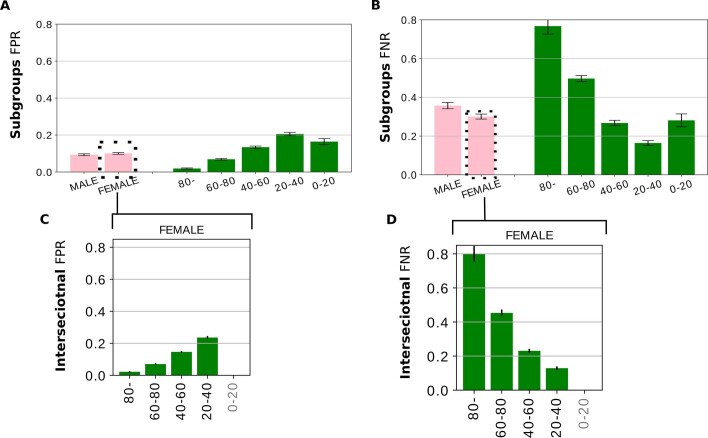
Comment in
-
Rising to the challenge of bias in health care AI.Nat Med. 2021 Dec;27(12):2079-2081. doi: 10.1038/s41591-021-01577-2. Nat Med. 2021. PMID: 34893774 Free PMC article.
-
Reply to: 'Potential sources of dataset bias complicate investigation of underdiagnosis by machine learning algorithms' and 'Confounding factors need to be accounted for in assessing bias by machine learning algorithms'.Nat Med. 2022 Jun;28(6):1161-1162. doi: 10.1038/s41591-022-01854-8. Epub 2022 Jun 16. Nat Med. 2022. PMID: 35710992 No abstract available.
-
Potential sources of dataset bias complicate investigation of underdiagnosis by machine learning algorithms.Nat Med. 2022 Jun;28(6):1157-1158. doi: 10.1038/s41591-022-01846-8. Epub 2022 Jun 16. Nat Med. 2022. PMID: 35710993 No abstract available.
-
Confounding factors need to be accounted for in assessing bias by machine learning algorithms.Nat Med. 2022 Jun;28(6):1159-1160. doi: 10.1038/s41591-022-01847-7. Epub 2022 Jun 16. Nat Med. 2022. PMID: 35710994 No abstract available.
References
-
- Raghavan, M., Barocas, S., Kleinberg, J. & Levy, K. Mitigating bias in algorithmic hiring: evaluating claims and practices. In FAT* ’20: Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency 469–481 (Association for Computing Machinery, 2020).
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
