

PathAL: An Active Learning Framework for Histopathology Image Analysis
- PMID: 34898432
- PMCID: PMC9199991
- DOI: 10.1109/TMI.2021.3135002
PathAL: An Active Learning Framework for Histopathology Image Analysis
Abstract
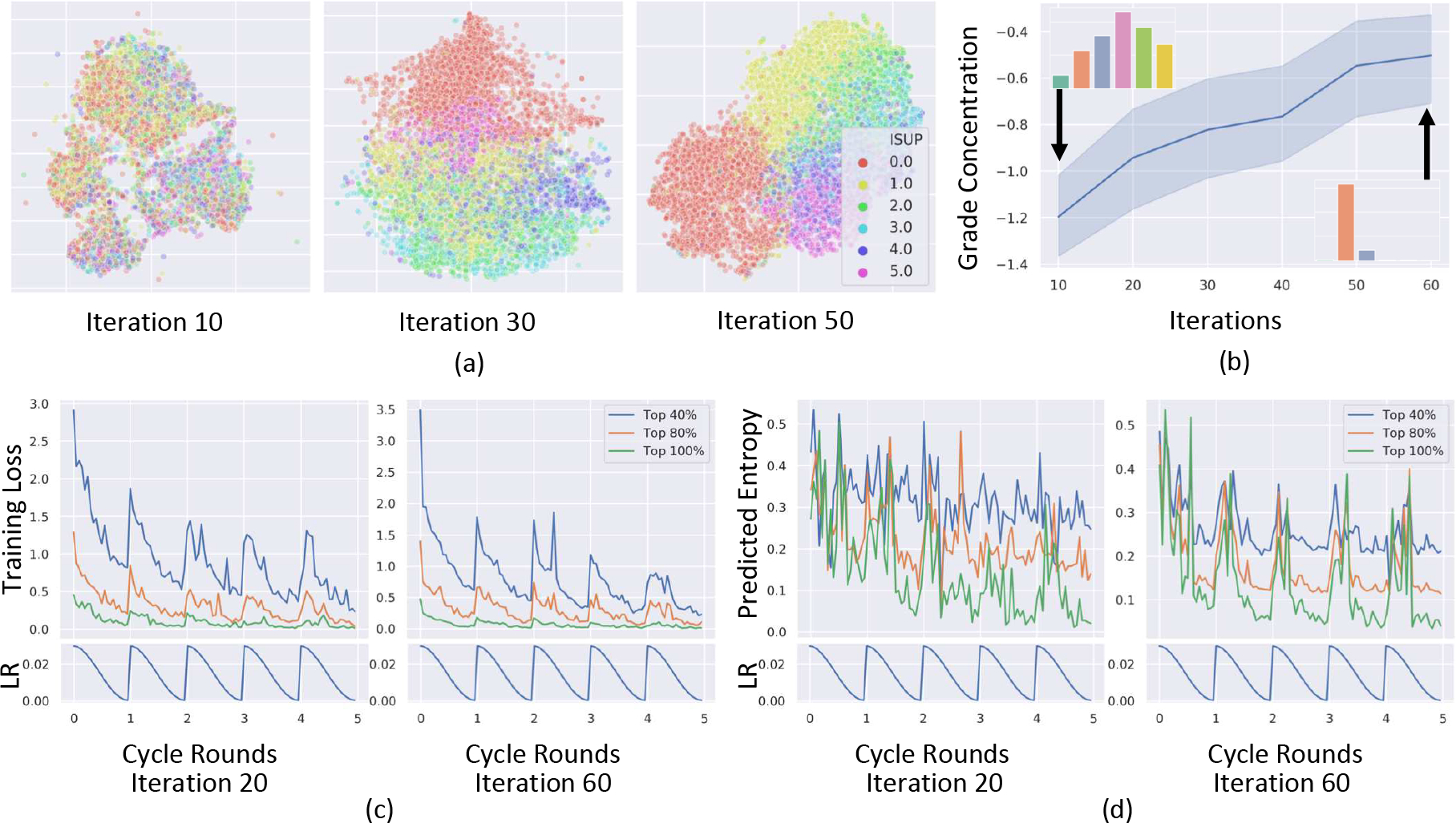
Deep neural networks, in particular convolutional networks, have rapidly become a popular choice for analyzing histopathology images. However, training these models relies heavily on a large number of samples manually annotated by experts, which is cumbersome and expensive. In addition, it is difficult to obtain a perfect set of labels due to the variability between expert annotations. This paper presents a novel active learning (AL) framework for histopathology image analysis, named PathAL. To reduce the required number of expert annotations, PathAL selects two groups of unlabeled data in each training iteration: one "informative" sample that requires additional expert annotation, and one "confident predictive" sample that is automatically added to the training set using the model's pseudo-labels. To reduce the impact of the noisy-labeled samples in the training set, PathAL systematically identifies noisy samples and excludes them to improve the generalization of the model. Our model advances the existing AL method for medical image analysis in two ways. First, we present a selection strategy to improve classification performance with fewer manual annotations. Unlike traditional methods focusing only on finding the most uncertain samples with low prediction confidence, we discover a large number of high confidence samples from the unlabeled set and automatically add them for training with assigned pseudo-labels. Second, we design a method to distinguish between noisy samples and hard samples using a heuristic approach. We exclude the noisy samples while preserving the hard samples to improve model performance. Extensive experiments demonstrate that our proposed PathAL framework achieves promising results on a prostate cancer Gleason grading task, obtaining similar performance with 40% fewer annotations compared to the fully supervised learning scenario. An ablation study is provided to analyze the effectiveness of each component in PathAL, and a pathologist reader study is conducted to validate our proposed algorithm.
Figures




References
-
- Litjens G, Kooi T, Bejnordi BE, Setio AAA, Ciompi F, Ghafoorian M, Van Der Laak JA, Van Ginneken B, and Sánchez CI, “A survey on deep learning in medical image analysis,” Medical image analysis, vol. 42, pp. 60–88, 2017. - PubMed
-
- Yang C-W, Lin T-P, Huang Y-H, Chung H-J, Kuo J-Y, Huang WJ, Wu HH, Chang Y-H, Lin AT, and Chen K-K, “Does extended prostate needle biopsy improve the concordance of gleason scores between biopsy and prostatectomy in the taiwanese population?” Journal of the Chinese Medical Association, vol. 75, no. 3, pp. 97–101, 2012. - PubMed
-
- Cheplygina V, de Bruijne M, and Pluim JP, “Not-so-supervised: a survey of semi-supervised, multi-instance, and transfer learning in medical image analysis,” Medical image analysis, vol. 54, pp. 280–296, 2019. - PubMed
-
- Budd S, Robinson EC, and Kainz B, “A survey on active learning and human-in-the-loop deep learning for medical image analysis,” arXiv preprint arXiv:1910.02923, 2019. - PubMed
-
- Dgani Y, Greenspan H, and Goldberger J, “Training a neural network based on unreliable human annotation of medical images,” in 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018). IEEE, 2018, pp. 39–42.
