

Hyperbolic trade-off: The importance of balancing trial and subject sample sizes in neuroimaging
- PMID: 34906711
- PMCID: PMC9636536
- DOI: 10.1016/j.neuroimage.2021.118786
Hyperbolic trade-off: The importance of balancing trial and subject sample sizes in neuroimaging
Abstract
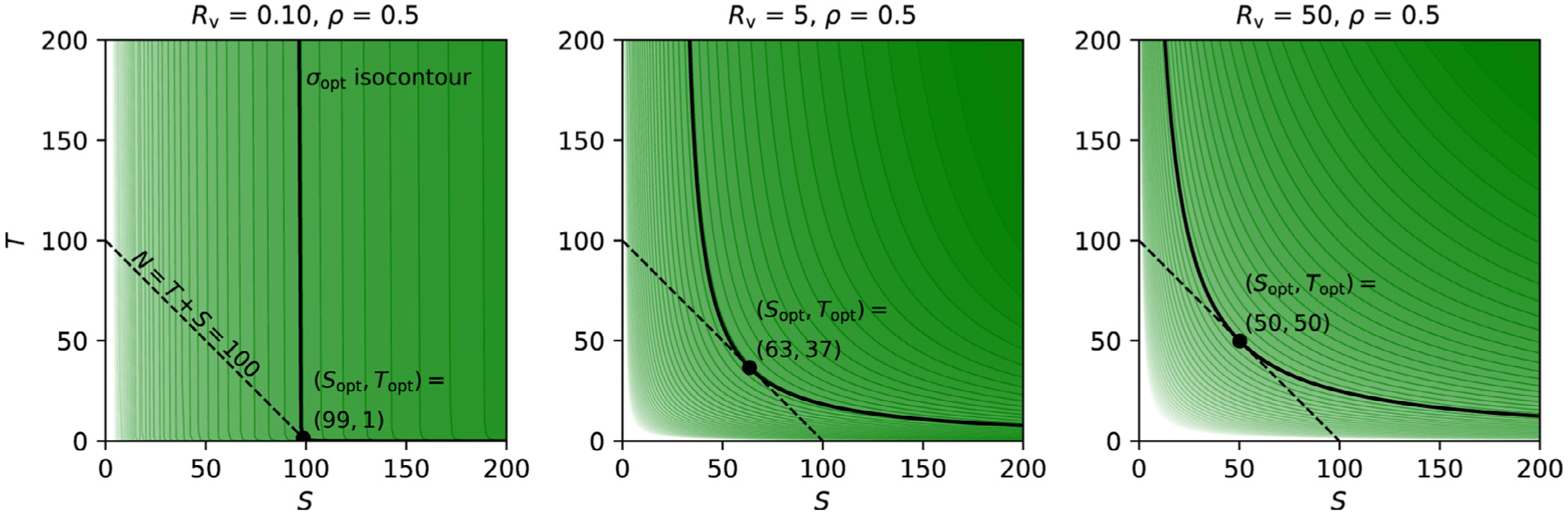
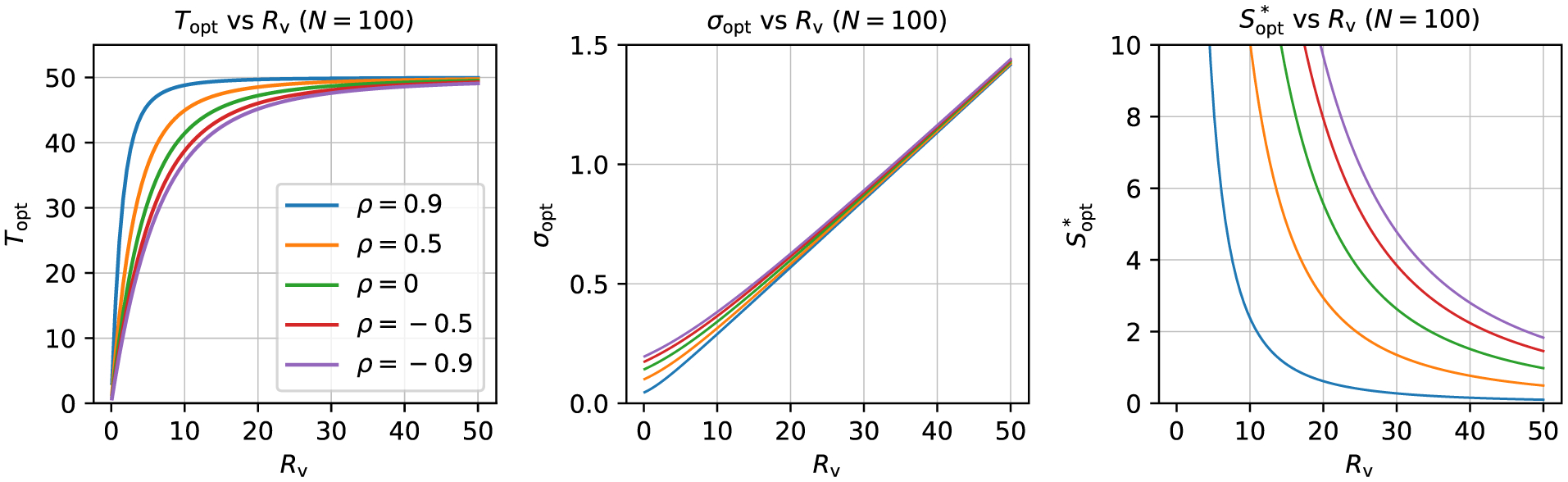
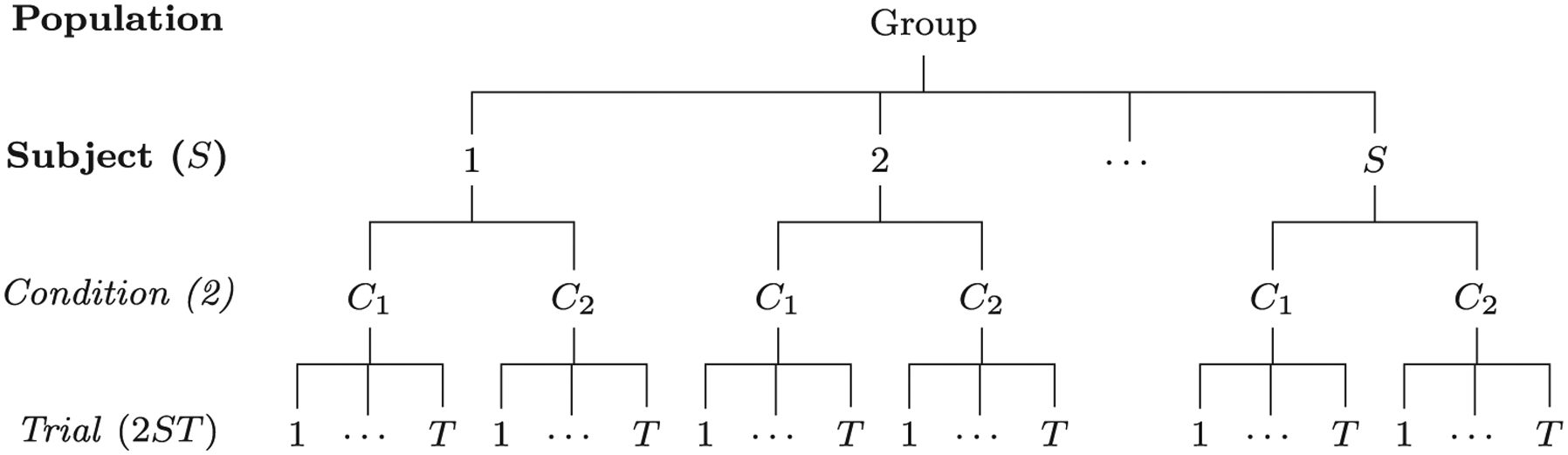
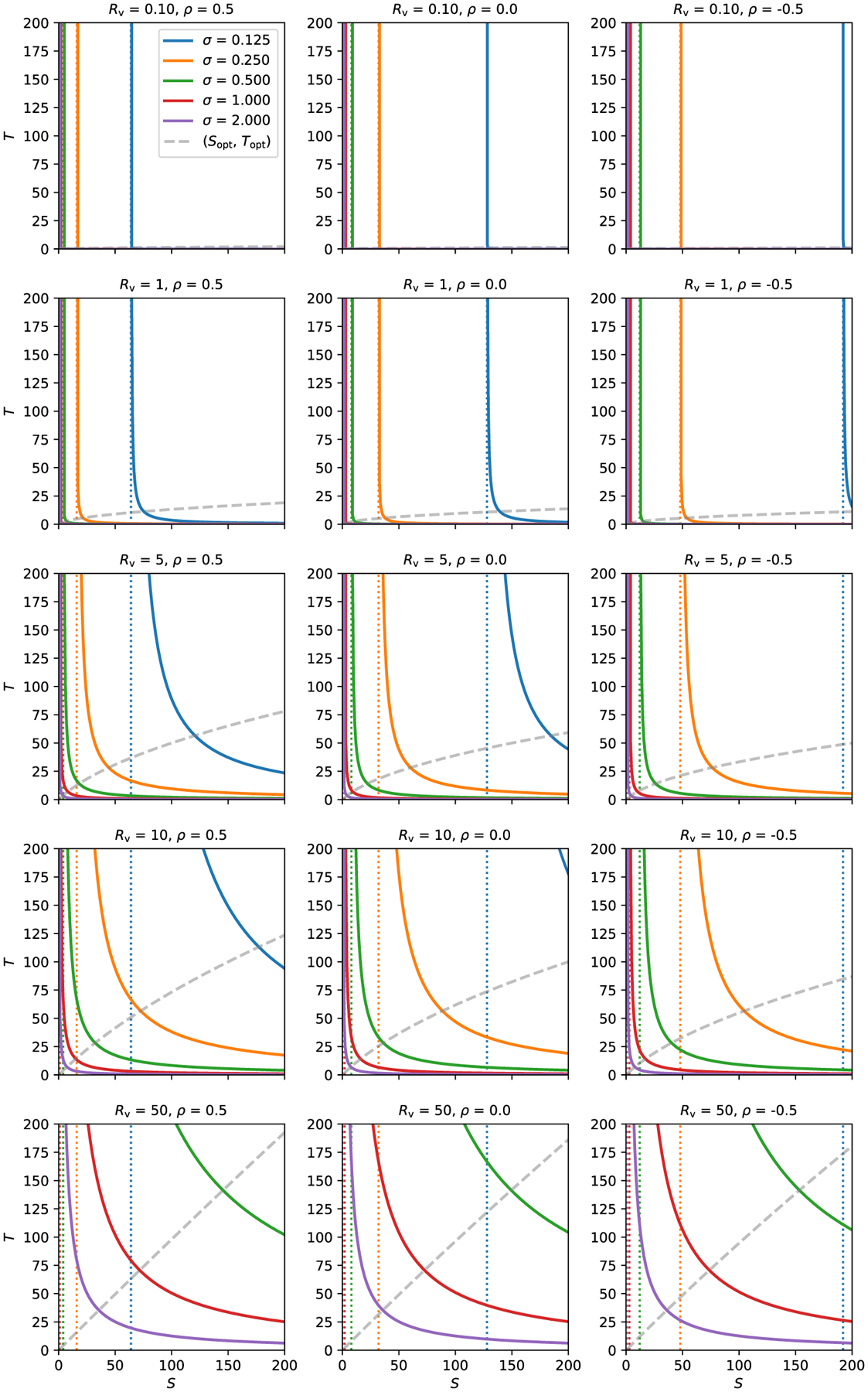
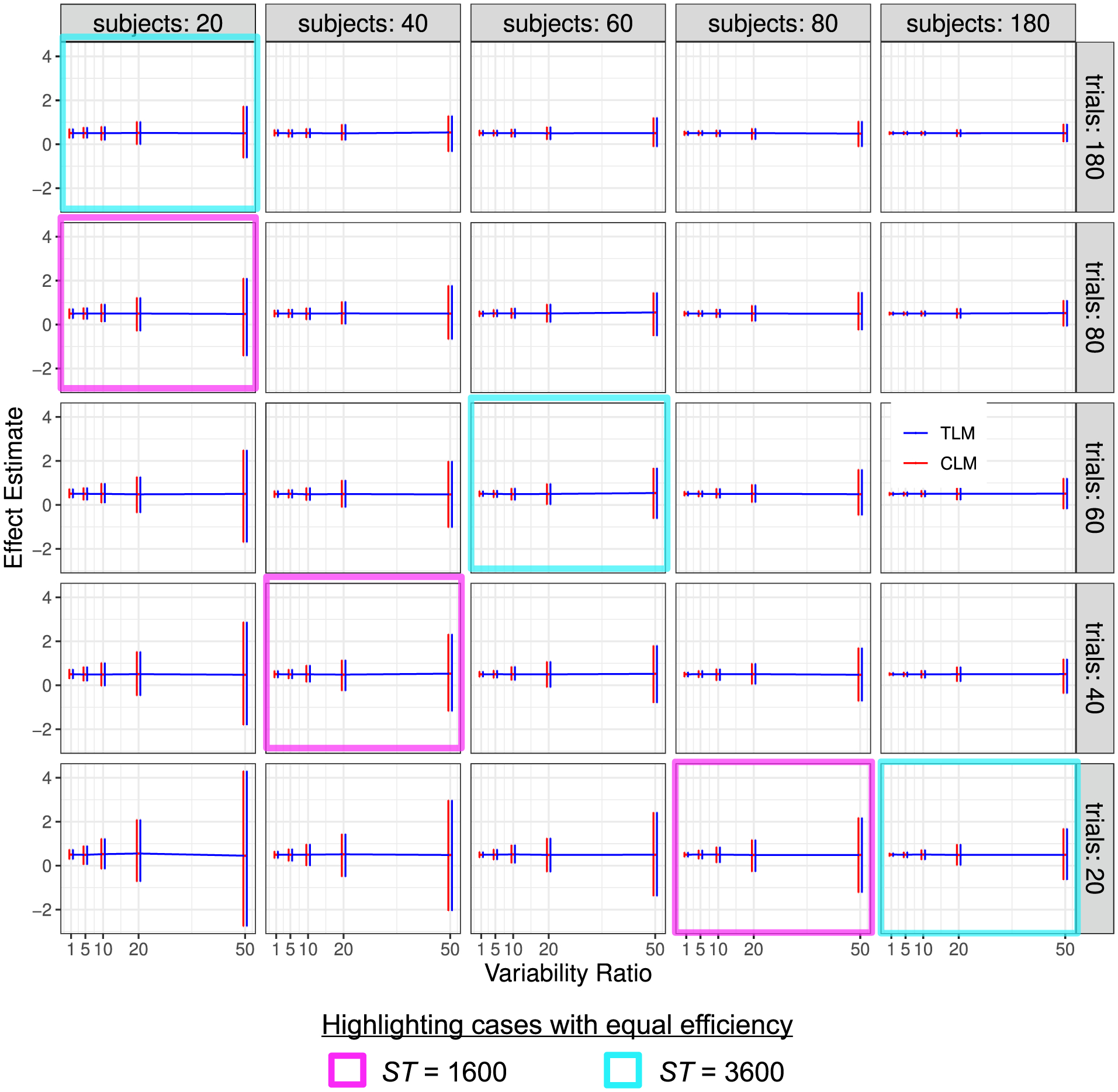
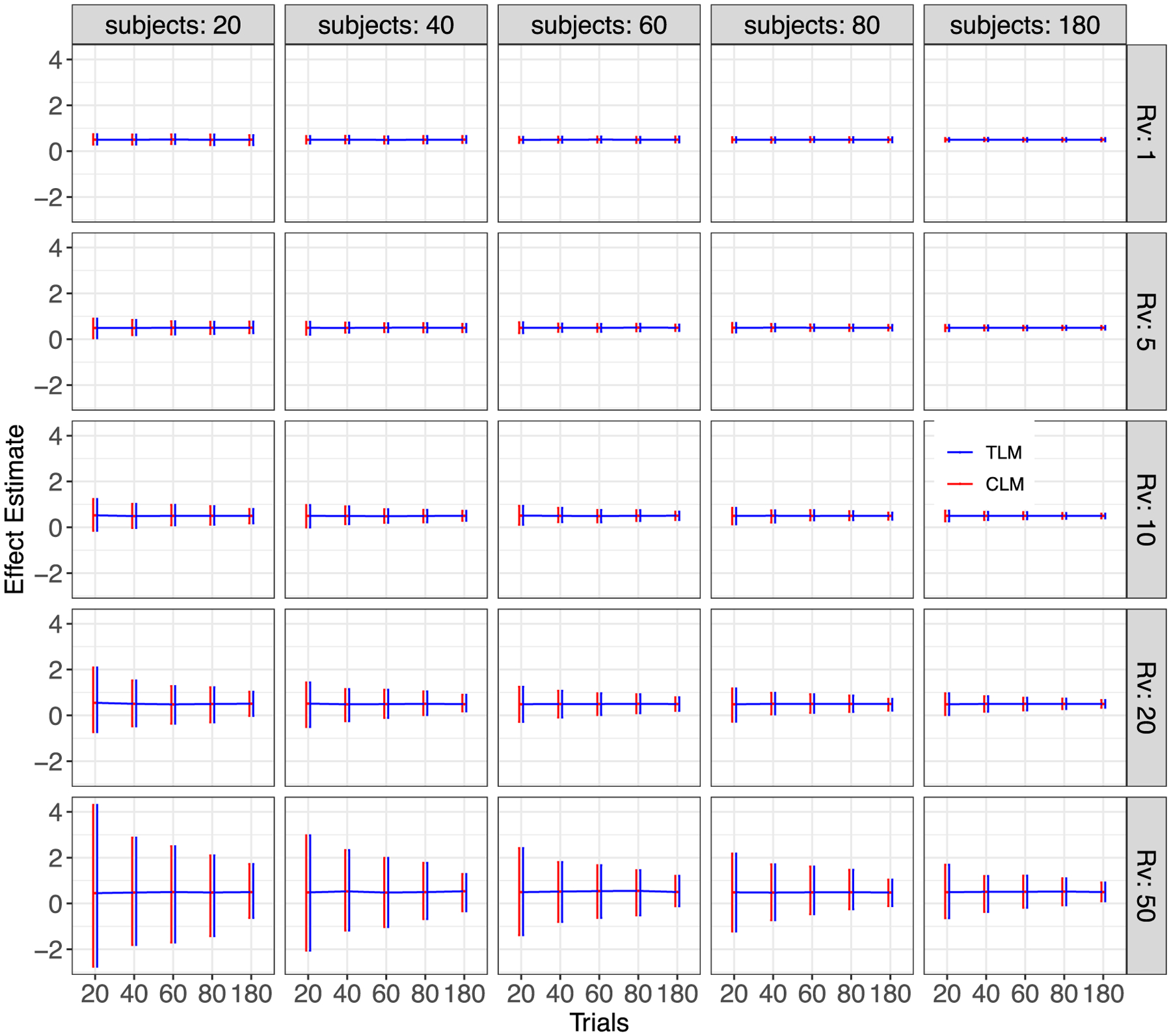
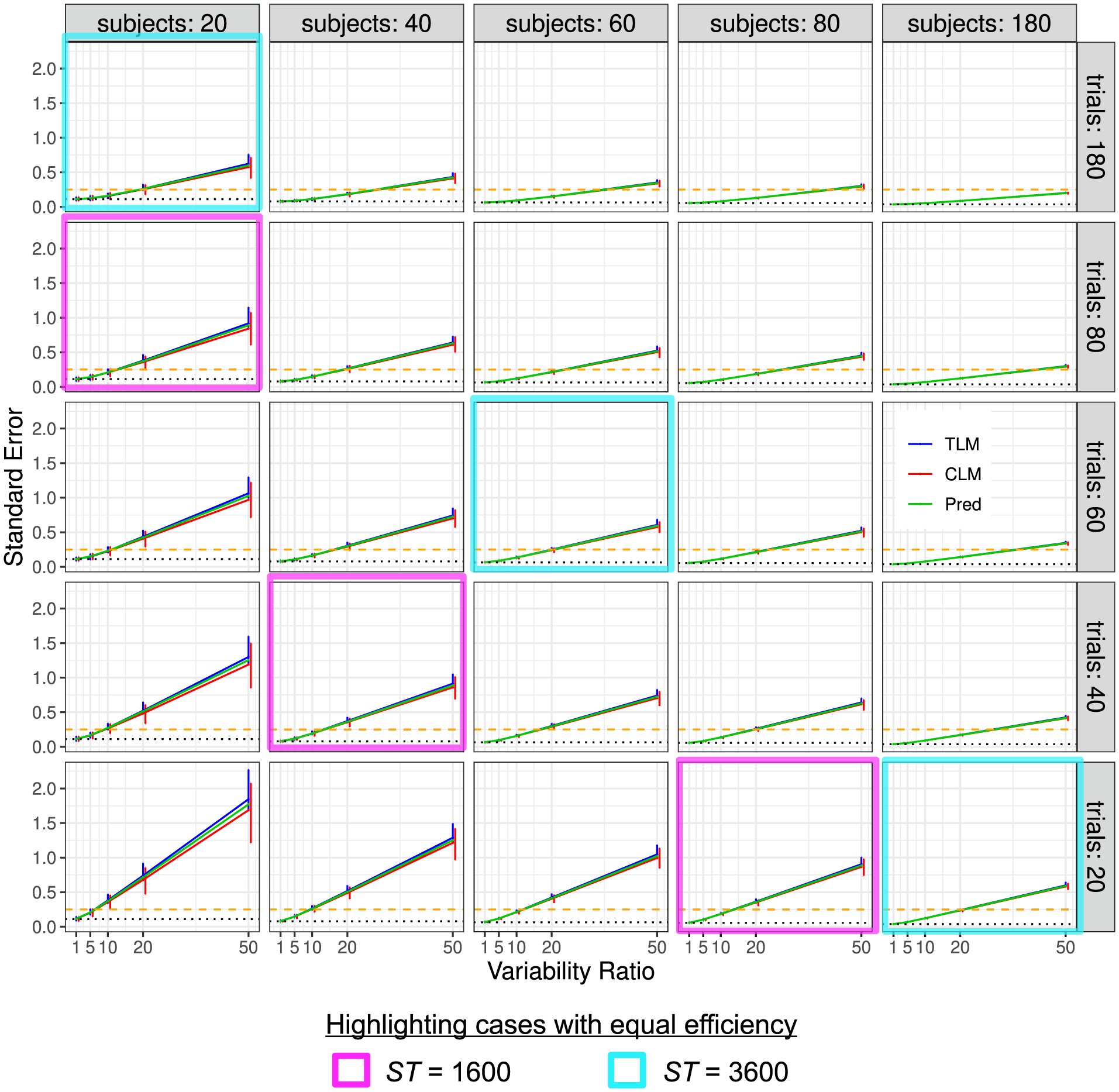
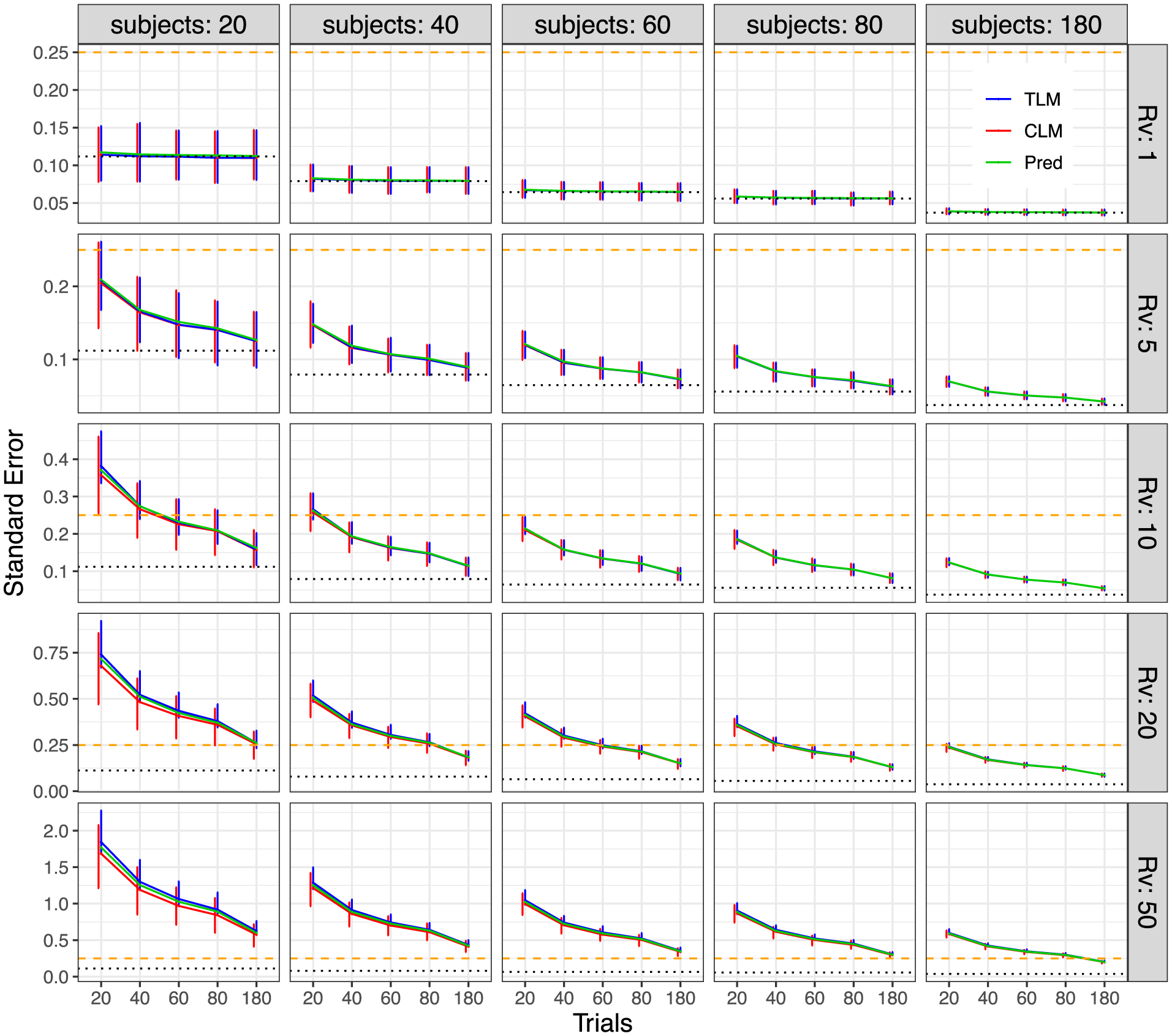
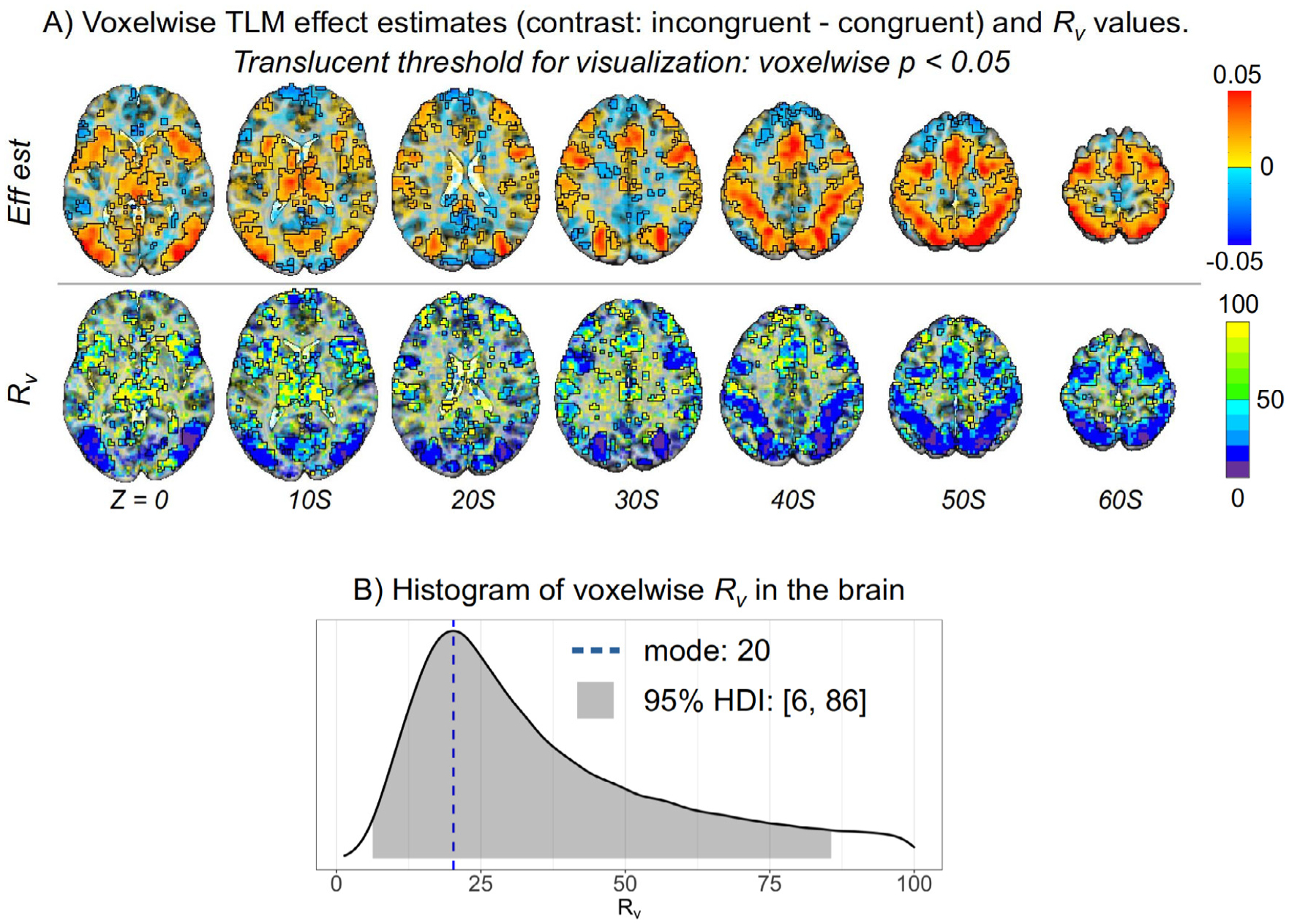
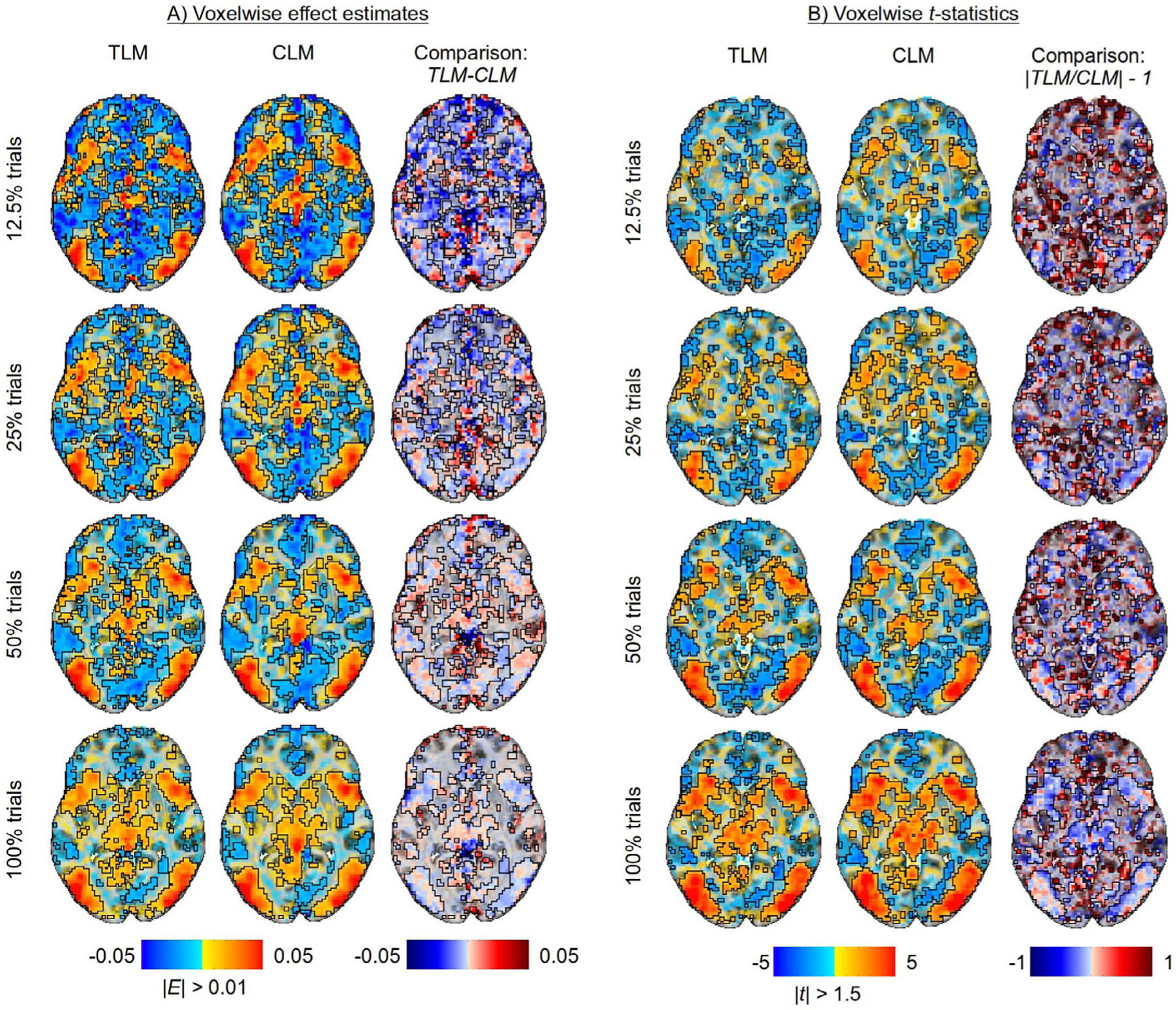
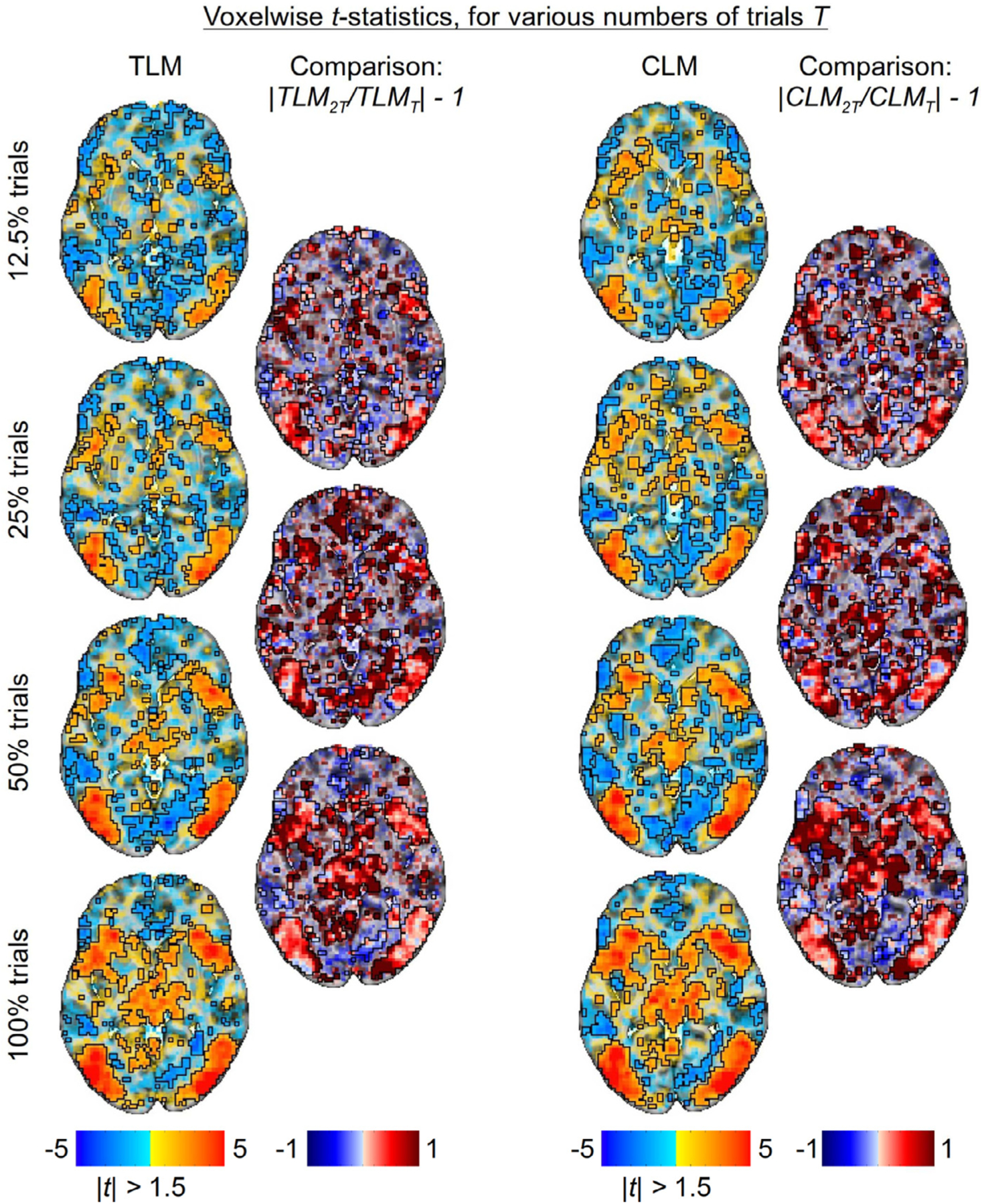
Here we investigate the crucial role of trials in task-based neuroimaging from the perspectives of statistical efficiency and condition-level generalizability. Big data initiatives have gained popularity for leveraging a large sample of subjects to study a wide range of effect magnitudes in the brain. On the other hand, most task-based FMRI designs feature a relatively small number of subjects, so that resulting parameter estimates may be associated with compromised precision. Nevertheless, little attention has been given to another important dimension of experimental design, which can equally boost a study's statistical efficiency: the trial sample size. The common practice of condition-level modeling implicitly assumes no cross-trial variability. Here, we systematically explore the different factors that impact effect uncertainty, drawing on evidence from hierarchical modeling, simulations and an FMRI dataset of 42 subjects who completed a large number of trials of cognitive control task. We find that, due to an approximately symmetric hyperbola-relationship between trial and subject sample sizes in the presence of relatively large cross-trial variability, 1) trial sample size has nearly the same impact as subject sample size on statistical efficiency; 2) increasing both the number of trials and subjects improves statistical efficiency more effectively than focusing on subjects alone; 3) trial sample size can be leveraged alongside subject sample size to improve the cost-effectiveness of an experimental design; 4) for small trial sample sizes, trial-level modeling, rather than condition-level modeling through summary statistics, may be necessary to accurately assess the standard error of an effect estimate. We close by making practical suggestions for improving experimental designs across neuroimaging and behavioral studies.
Copyright © 2021. Published by Elsevier Inc.
Figures
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
