

Concept recognition as a machine translation problem
- PMID: 34920707
- PMCID: PMC8678974
- DOI: 10.1186/s12859-021-04141-4
Concept recognition as a machine translation problem
Abstract
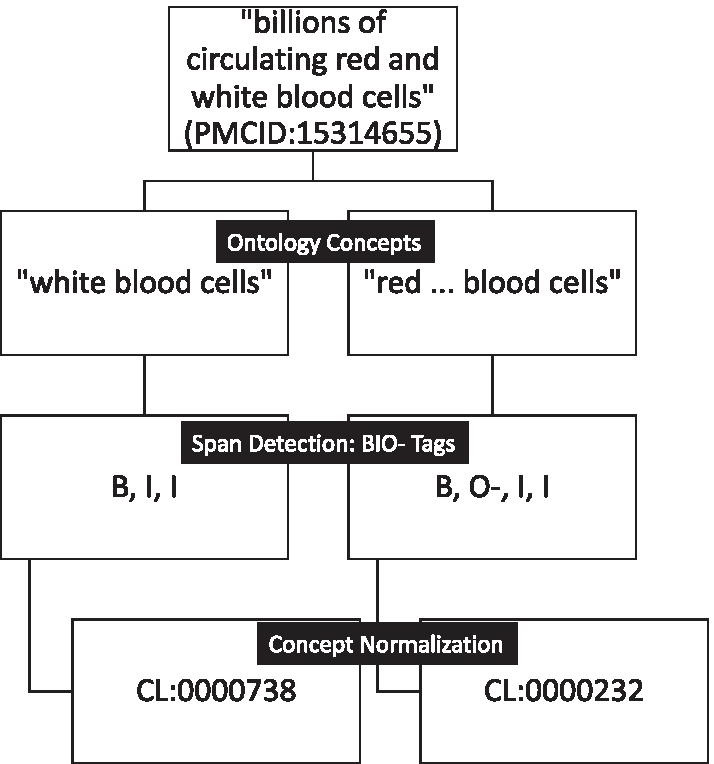
Background: Automated assignment of specific ontology concepts to mentions in text is a critical task in biomedical natural language processing, and the subject of many open shared tasks. Although the current state of the art involves the use of neural network language models as a post-processing step, the very large number of ontology classes to be recognized and the limited amount of gold-standard training data has impeded the creation of end-to-end systems based entirely on machine learning. Recently, Hailu et al. recast the concept recognition problem as a type of machine translation and demonstrated that sequence-to-sequence machine learning models have the potential to outperform multi-class classification approaches.
Methods: We systematically characterize the factors that contribute to the accuracy and efficiency of several approaches to sequence-to-sequence machine learning through extensive studies of alternative methods and hyperparameter selections. We not only identify the best-performing systems and parameters across a wide variety of ontologies but also provide insights into the widely varying resource requirements and hyperparameter robustness of alternative approaches. Analysis of the strengths and weaknesses of such systems suggest promising avenues for future improvements as well as design choices that can increase computational efficiency with small costs in performance.
Results: Bidirectional encoder representations from transformers for biomedical text mining (BioBERT) for span detection along with the open-source toolkit for neural machine translation (OpenNMT) for concept normalization achieve state-of-the-art performance for most ontologies annotated in the CRAFT Corpus. This approach uses substantially fewer computational resources, including hardware, memory, and time than several alternative approaches.
Conclusions: Machine translation is a promising avenue for fully machine-learning-based concept recognition that achieves state-of-the-art results on the CRAFT Corpus, evaluated via a direct comparison to previous results from the 2019 CRAFT shared task. Experiments illuminating the reasons for the surprisingly good performance of sequence-to-sequence methods targeting ontology identifiers suggest that further progress may be possible by mapping to alternative target concept representations. All code and models can be found at: https://github.com/UCDenver-ccp/Concept-Recognition-as-Translation .
Keywords: Computational resources; Concept recognition; Machine translation; Named entity normalization; Named entity recognition.
© 2021. The Author(s).
Conflict of interest statement
The authors declare that they have no competing interests.
Figures
References
-
- Jin-Dong K, Claire N, Robert B, Louise D. Proceedings of the 5th workshop on bionlp open shared tasks. In: Proceedings of the 5th workshop on BioNLP open shared tasks. 2019.
-
- Wang LL, Lo K, Chandrasekhar Y, Reas R, Yang J, Eide D, Funk K, Kinney R, Liu Z, Merrill W, et al. Cord-19: the Covid-19 open research dataset. 2020.
-
- Furrer L, Cornelius J, Rinaldi F. Uzh@ craft-st: a sequence-labeling approach to concept recognition. In: Proceedings of the 5th workshop on BioNLP open shared tasks. 2019. p. 185–95.
-
- Demoulin NT, Coussement K. Acceptance of text-mining systems: the signaling role of information quality. Inf Manag. 2020;57(1):103120. doi: 10.1016/j.im.2018.10.006. - DOI
Grants and funding
LinkOut - more resources
Full Text Sources
