

During Lipreading Training With Sentence Stimuli, Feedback Controls Learning and Generalization to Audiovisual Speech in Noise
- PMID: 34965362
- PMCID: PMC9128727
- DOI: 10.1044/2021_AJA-21-00034
During Lipreading Training With Sentence Stimuli, Feedback Controls Learning and Generalization to Audiovisual Speech in Noise
Abstract
Purpose: This study investigated the effects of external feedback on perceptual learning of visual speech during lipreading training with sentence stimuli. The goal was to improve visual-only (VO) speech recognition and increase accuracy of audiovisual (AV) speech recognition in noise. The rationale was that spoken word recognition depends on the accuracy of sublexical (phonemic/phonetic) speech perception; effective feedback during training must support sublexical perceptual learning.
Method: Normal-hearing (NH) adults were assigned to one of three types of feedback: Sentence feedback was the entire sentence printed after responding to the stimulus. Word feedback was the correct response words and perceptually near but incorrect response words. Consonant feedback was correct response words and consonants in incorrect but perceptually near response words. Six training sessions were given. Pre- and posttraining testing included an untrained control group. Test stimuli were disyllable nonsense words for forced-choice consonant identification, and isolated words and sentences for open-set identification. Words and sentences were VO, AV, and audio-only (AO) with the audio in speech-shaped noise.
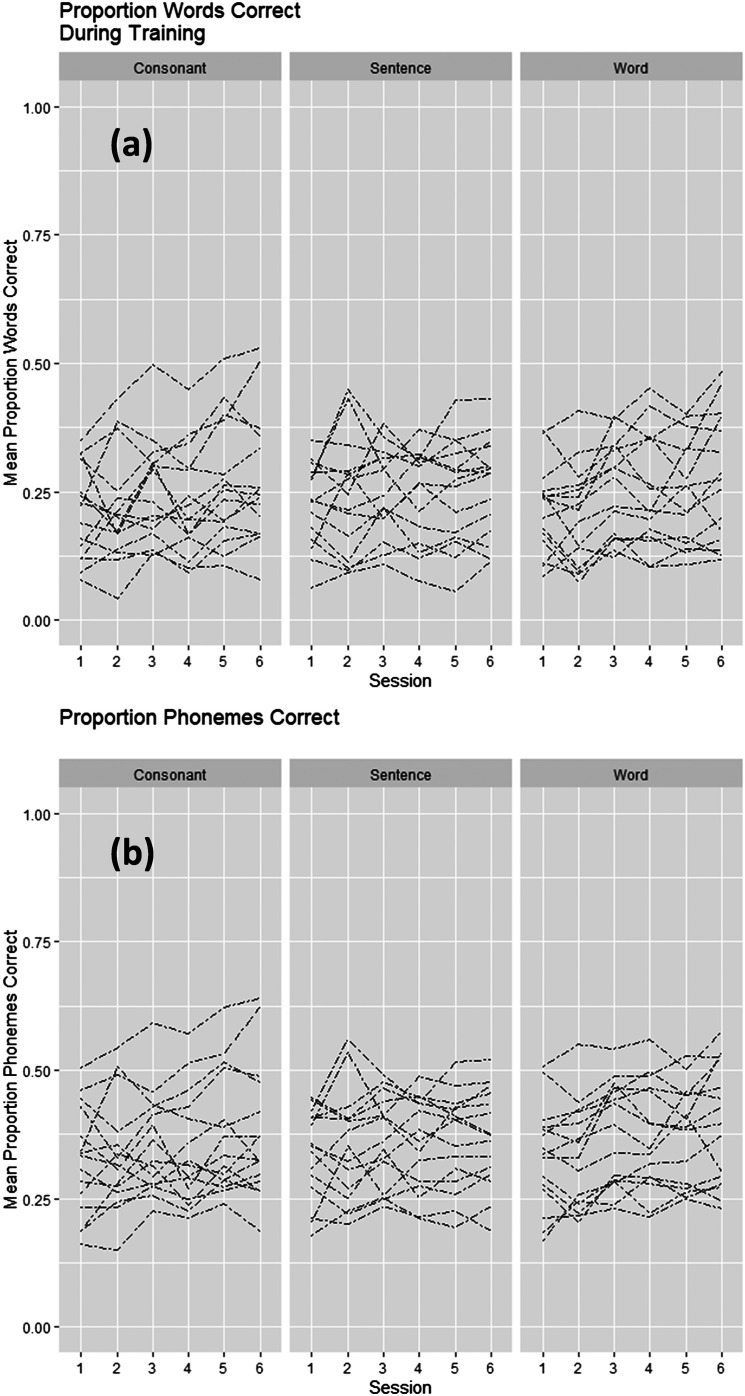
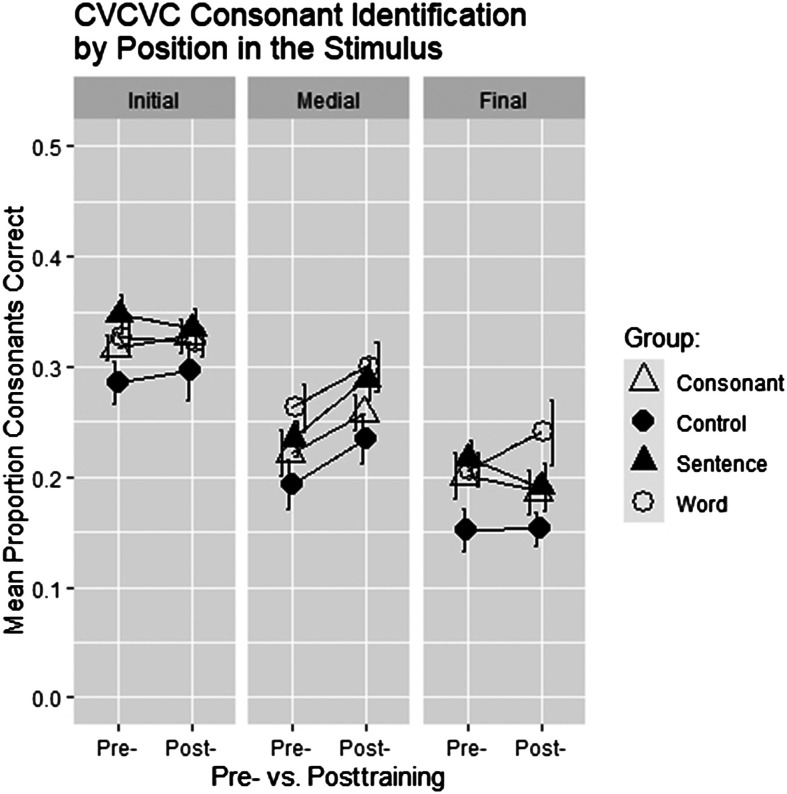
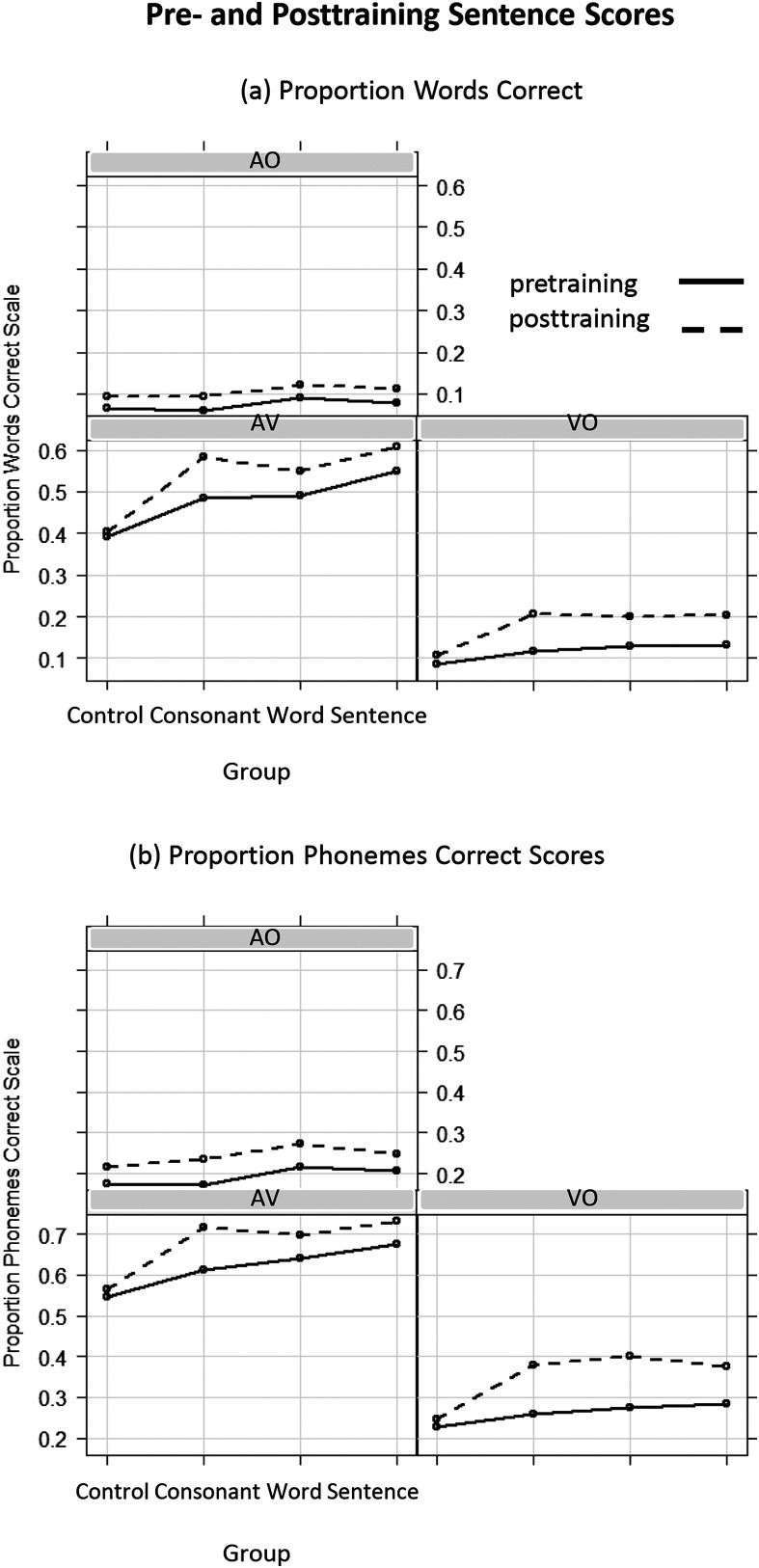
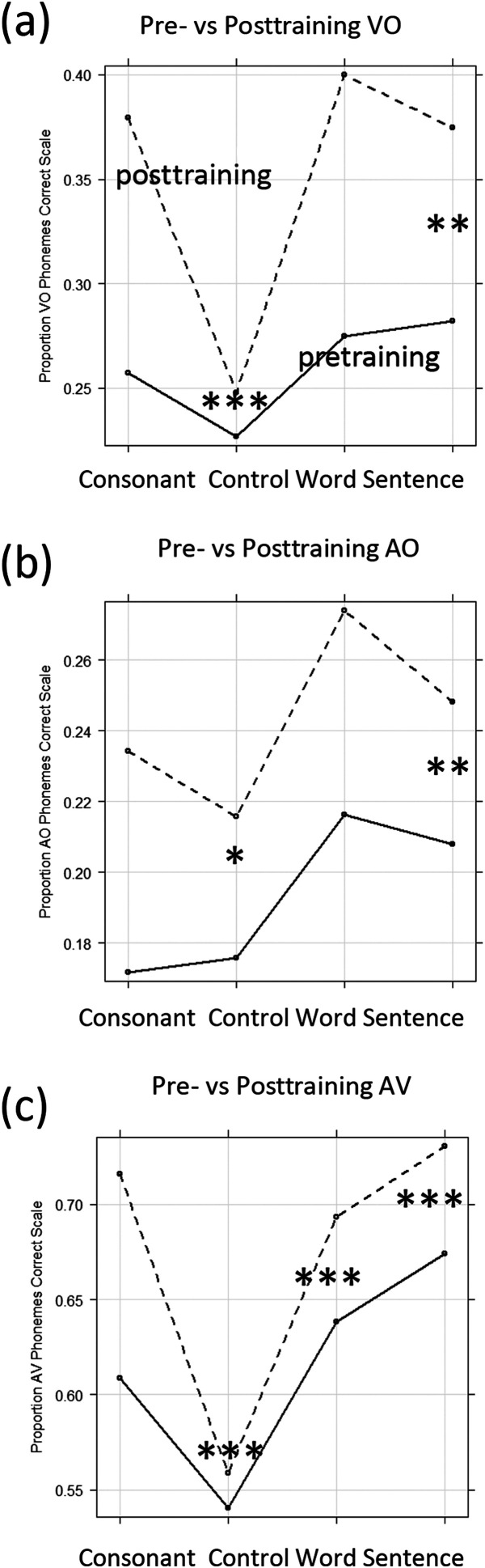
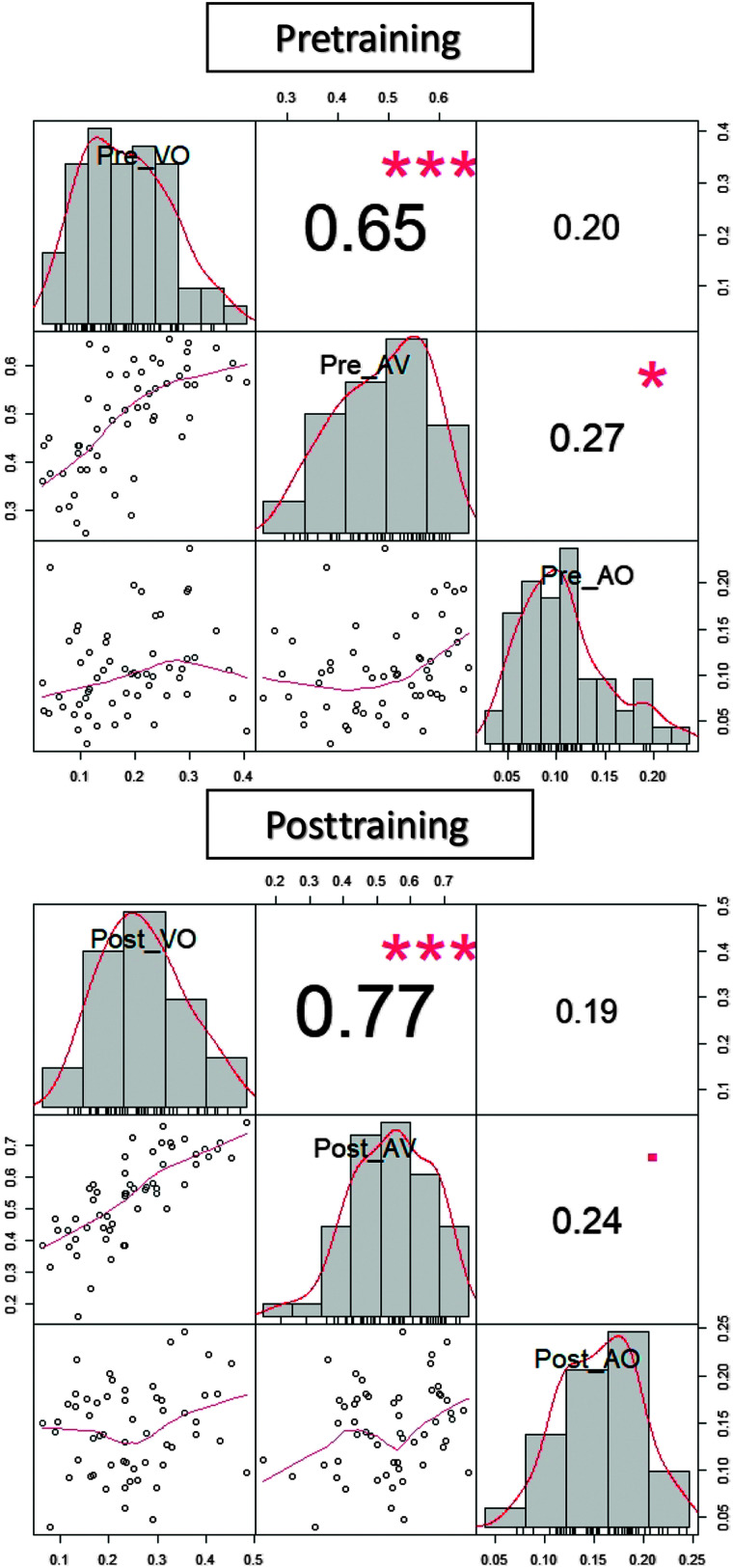
Results: Lipreading accuracy increased during training. Pre- and posttraining tests of consonant identification showed no improvement beyond test-retest increases obtained by untrained controls. Isolated word recognition with a talker not seen during training showed that the control group improved more than the sentence group. Tests of untrained sentences showed that the consonant group significantly improved in all of the stimulus conditions (VO, AO, and AV). Its mean words correct scores increased by 9.2 percentage points for VO, 3.4 percentage points for AO, and 9.8 percentage points for AV stimuli.
Conclusions: Consonant feedback during training with sentences stimuli significantly increased perceptual learning. The training generalized to untrained VO, AO, and AV sentence stimuli. Lipreading training has potential to significantly improve adults' face-to-face communication in noisy settings in which the talker can be seen.
Figures

Similar articles
-
Lipreading: A Review of Its Continuing Importance for Speech Recognition With an Acquired Hearing Loss and Possibilities for Effective Training.Am J Audiol. 2022 Jun 2;31(2):453-469. doi: 10.1044/2021_AJA-21-00112. Epub 2022 Mar 22. Am J Audiol. 2022. PMID: 35316072 Free PMC article. Review.
-
Multisensory training can promote or impede visual perceptual learning of speech stimuli: visual-tactile vs. visual-auditory training.Front Hum Neurosci. 2014 Oct 31;8:829. doi: 10.3389/fnhum.2014.00829. eCollection 2014. Front Hum Neurosci. 2014. PMID: 25400566 Free PMC article.
-
Auditory Perceptual Learning for Speech Perception Can be Enhanced by Audiovisual Training.Front Neurosci. 2013 Mar 18;7:34. doi: 10.3389/fnins.2013.00034. eCollection 2013. Front Neurosci. 2013. PMID: 23515520 Free PMC article.
-
Effect of training on word-recognition performance in noise for young normal-hearing and older hearing-impaired listeners.Ear Hear. 2006 Jun;27(3):263-78. doi: 10.1097/01.aud.0000215980.21158.a2. Ear Hear. 2006. PMID: 16672795
-
Improving older adults' understanding of challenging speech: Auditory training, rapid adaptation and perceptual learning.Hear Res. 2021 Mar 15;402:108054. doi: 10.1016/j.heares.2020.108054. Epub 2020 Aug 7. Hear Res. 2021. PMID: 32826108 Free PMC article. Review.
Cited by
-
Lipreading: A Review of Its Continuing Importance for Speech Recognition With an Acquired Hearing Loss and Possibilities for Effective Training.Am J Audiol. 2022 Jun 2;31(2):453-469. doi: 10.1044/2021_AJA-21-00112. Epub 2022 Mar 22. Am J Audiol. 2022. PMID: 35316072 Free PMC article. Review.
-
Modality-Specific Perceptual Learning of Vocoded Auditory versus Lipread Speech: Different Effects of Prior Information.Brain Sci. 2023 Jun 29;13(7):1008. doi: 10.3390/brainsci13071008. Brain Sci. 2023. PMID: 37508940 Free PMC article.
References
-
- Ahissar, M. , Nahum, M. , Nelken, I. , & Hochstein, S. (2009). Reverse hierarchies and sensory learning. Philosophical Transactions of the Royal Society B, 364(1515), 285–299. https://doi.org/10.1098/rstb.2008.0253 - PMC - PubMed
-
- Ashby, F. G. , & Maddox, W. T. (2011). Human category learning 2.0. Annals of the New York Academy of Sciences, 1224(1), 147–161. https://doi.org/10.1111/j.1749-6632.2010.05874.x - PMC - PubMed
-
- Ashby, F. G. , & Valentin, V. V. (2017). Chapter 7 - Multiple systems of perceptual category learning: Theory and cognitive tests. In Cohen H. & Lefebvre C. (Eds.), Handbook of categorization in cognitive science (2nd ed., pp. 157–188). Elsevier. https://doi.org/10.1016/B978-0-08-101107-2.00007-5
-
- Ashby, F. G. , & Vucovich, L. E. (2016). The role of feedback contingency in perceptual category learning. Journal of Experimental Psychology: Learning, Memory, and Cognition, 42(11), 1731–1746. https://doi.org/10.1037/xlm0000277 - PMC - PubMed
-
- Auer, E. T., Jr. , & Bernstein, L. E. (1997). Speechreading and the structure of the lexicon: Computationally modeling the effects of reduced phonetic distinctiveness on lexical uniqueness. The Journal of the Acoustical Society of America, 102(6), 3704–3710. https://doi.org/10.1121/1.420402 - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
