

An exploration of error-driven learning in simple two-layer networks from a discriminative learning perspective
- PMID: 35032022
- PMCID: PMC9579095
- DOI: 10.3758/s13428-021-01711-5
An exploration of error-driven learning in simple two-layer networks from a discriminative learning perspective
Abstract
Error-driven learning algorithms, which iteratively adjust expectations based on prediction error, are the basis for a vast array of computational models in the brain and cognitive sciences that often differ widely in their precise form and application: they range from simple models in psychology and cybernetics to current complex deep learning models dominating discussions in machine learning and artificial intelligence. However, despite the ubiquity of this mechanism, detailed analyses of its basic workings uninfluenced by existing theories or specific research goals are rare in the literature. To address this, we present an exposition of error-driven learning - focusing on its simplest form for clarity - and relate this to the historical development of error-driven learning models in the cognitive sciences. Although historically error-driven models have been thought of as associative, such that learning is thought to combine preexisting elemental representations, our analysis will highlight the discriminative nature of learning in these models and the implications of this for the way how learning is conceptualized. We complement our theoretical introduction to error-driven learning with a practical guide to the application of simple error-driven learning models in which we discuss a number of example simulations, that are also presented in detail in an accompanying tutorial.
Keywords: Cognitive modeling; Computational simulations; Discriminative learning; Error-driven learning; Neural network models.
© 2021. The Author(s).
Figures
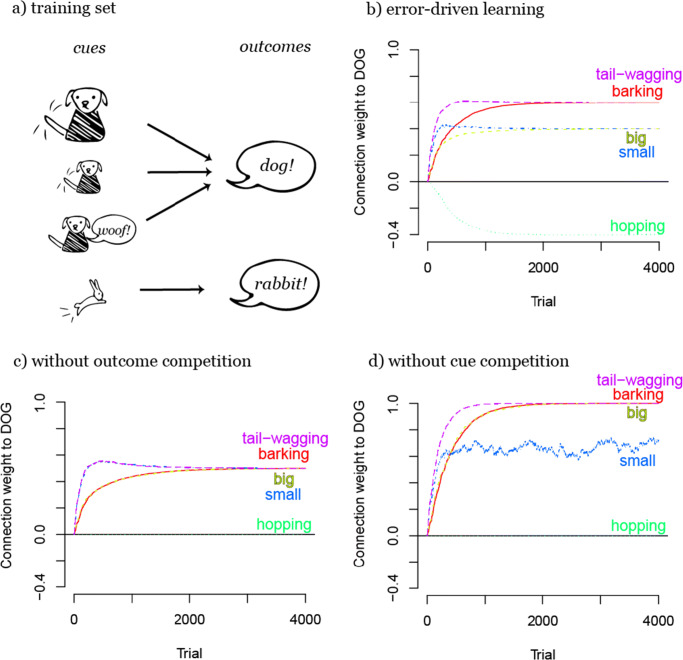
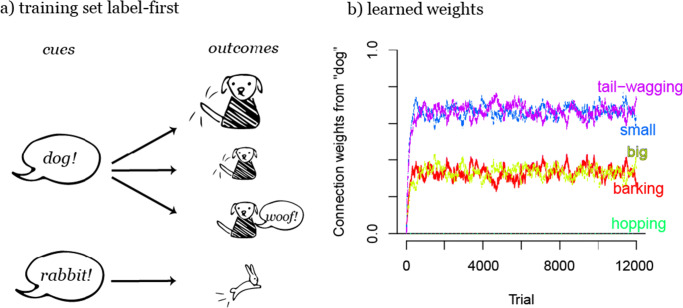
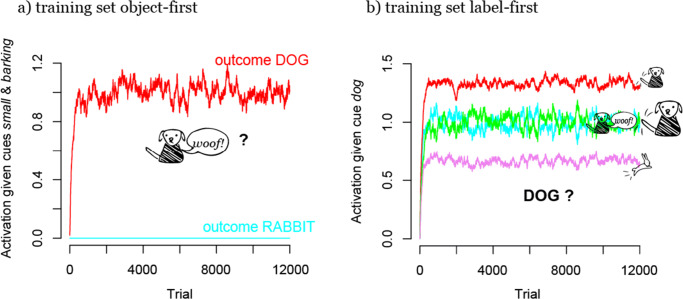
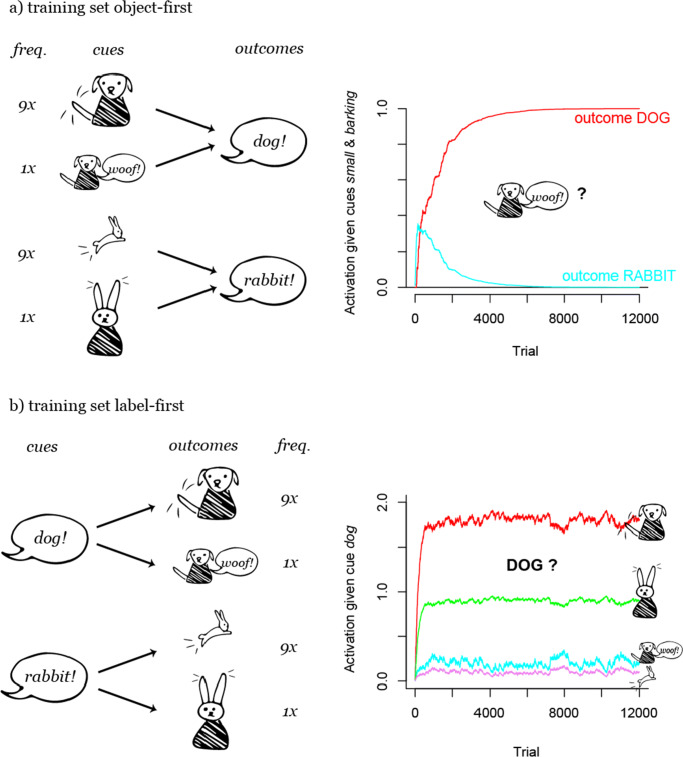
Similar articles
-
Data-driven modeling and prediction of blood glucose dynamics: Machine learning applications in type 1 diabetes.Artif Intell Med. 2019 Jul;98:109-134. doi: 10.1016/j.artmed.2019.07.007. Epub 2019 Jul 26. Artif Intell Med. 2019. PMID: 31383477 Review.
-
The deep arbitrary polynomial chaos neural network or how Deep Artificial Neural Networks could benefit from data-driven homogeneous chaos theory.Neural Netw. 2023 Sep;166:85-104. doi: 10.1016/j.neunet.2023.06.036. Epub 2023 Jul 10. Neural Netw. 2023. PMID: 37480771
-
A Discussion of Machine Learning Approaches for Clinical Prediction Modeling.Acta Neurochir Suppl. 2022;134:65-73. doi: 10.1007/978-3-030-85292-4_9. Acta Neurochir Suppl. 2022. PMID: 34862529
-
Artificial intelligence in spine care: current applications and future utility.Eur Spine J. 2022 Aug;31(8):2057-2081. doi: 10.1007/s00586-022-07176-0. Epub 2022 Mar 27. Eur Spine J. 2022. PMID: 35347425 Review.
-
Understanding deep learning - challenges and prospects.J Pak Med Assoc. 2022 Feb;72(Suppl 1)(2):S59-S63. doi: 10.47391/JPMA.AKU-12. J Pak Med Assoc. 2022. PMID: 35202373 Review.
Cited by
-
How trial-to-trial learning shapes mappings in the mental lexicon: Modelling lexical decision with linear discriminative learning.Cogn Psychol. 2023 Nov;146:101598. doi: 10.1016/j.cogpsych.2023.101598. Epub 2023 Sep 14. Cogn Psychol. 2023. PMID: 37716109 Free PMC article.
-
Prediction and error in early infant speech learning: A speech acquisition model.Cognition. 2021 Jul;212:104697. doi: 10.1016/j.cognition.2021.104697. Epub 2021 Mar 31. Cognition. 2021. PMID: 33798952 Free PMC article.
-
Understanding the Phonetic Characteristics of Speech Under Uncertainty-Implications of the Representation of Linguistic Knowledge in Learning and Processing.Front Psychol. 2022 Apr 25;13:754395. doi: 10.3389/fpsyg.2022.754395. eCollection 2022. Front Psychol. 2022. PMID: 35548492 Free PMC article.
-
A cognitive modeling approach to learning and using reference biases in language.Front Artif Intell. 2022 Nov 16;5:933504. doi: 10.3389/frai.2022.933504. eCollection 2022. Front Artif Intell. 2022. PMID: 36467560 Free PMC article.
-
Order Matters! Influences of Linear Order on Linguistic Category Learning.Cogn Sci. 2020 Nov;44(11):e12910. doi: 10.1111/cogs.12910. Cogn Sci. 2020. PMID: 33124103 Free PMC article.
References
-
- Adi, Y., Kermany, E., Belinkov, Y., Lavi, O., & Goldberg, Y. (2016). Fine-grained analysis of sentence embeddings using auxiliary prediction tasks. arXiv:1608.04207.
-
- Anderson JR. ACT: A simple theory of complex cognition. American Psychologist. 1996;51(4):355–365. doi: 10.1037/0003-066X.51.4.355. - DOI
-
- Arnold D, Tomaschek F, Sering K, Lopez F, Baayen RH. Words from spontaneous conversational speech can be recognized with human-like accuracy by an error-driven learning algorithm that discriminates between meanings straight from smart acoustic features, bypassing the phoneme as recognition unit. PloS one. 2017;12(4):e0174623. doi: 10.1371/journal.pone.0174623. - DOI - PMC - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
