

Surrogate gradients for analog neuromorphic computing
- PMID: 35042792
- PMCID: PMC8794842
- DOI: 10.1073/pnas.2109194119
Surrogate gradients for analog neuromorphic computing
Abstract
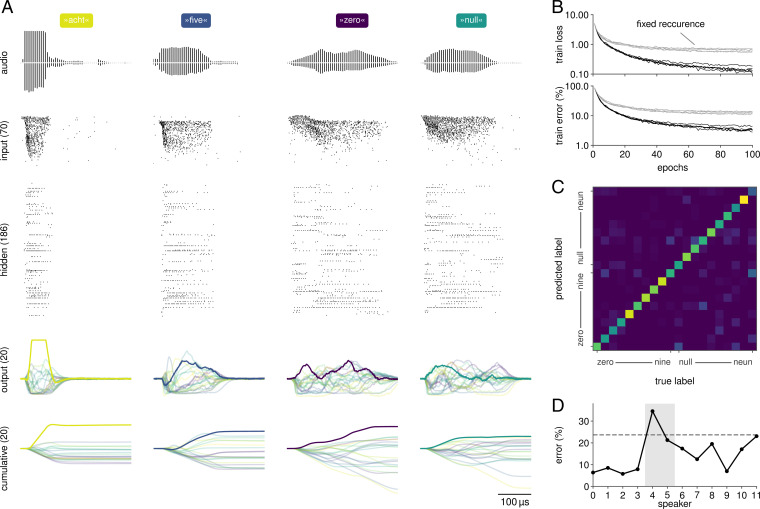
To rapidly process temporal information at a low metabolic cost, biological neurons integrate inputs as an analog sum, but communicate with spikes, binary events in time. Analog neuromorphic hardware uses the same principles to emulate spiking neural networks with exceptional energy efficiency. However, instantiating high-performing spiking networks on such hardware remains a significant challenge due to device mismatch and the lack of efficient training algorithms. Surrogate gradient learning has emerged as a promising training strategy for spiking networks, but its applicability for analog neuromorphic systems has not been demonstrated. Here, we demonstrate surrogate gradient learning on the BrainScaleS-2 analog neuromorphic system using an in-the-loop approach. We show that learning self-corrects for device mismatch, resulting in competitive spiking network performance on both vision and speech benchmarks. Our networks display sparse spiking activity with, on average, less than one spike per hidden neuron and input, perform inference at rates of up to 85,000 frames per second, and consume less than 200 mW. In summary, our work sets several benchmarks for low-energy spiking network processing on analog neuromorphic hardware and paves the way for future on-chip learning algorithms.
Keywords: neuromorphic hardware; recurrent neural networks; self-calibration; spiking neural networks; surrogate gradients.
Copyright © 2022 the Author(s). Published by PNAS.
Conflict of interest statement
The authors declare no competing interest.
Figures
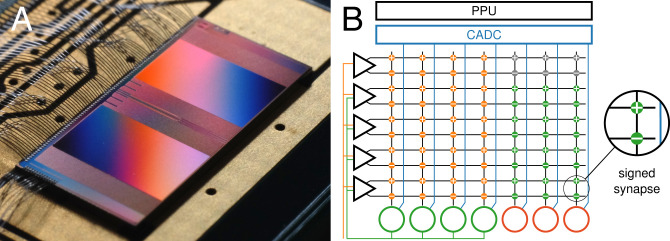
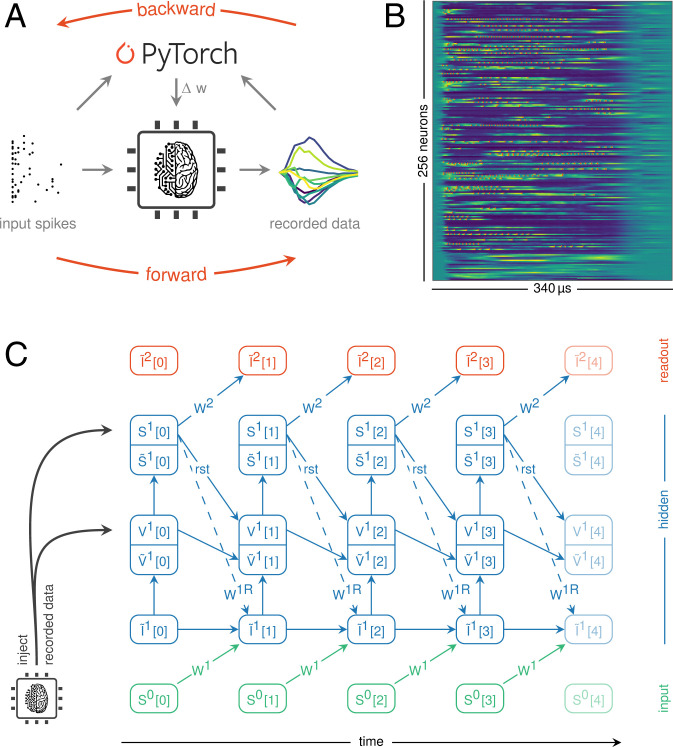
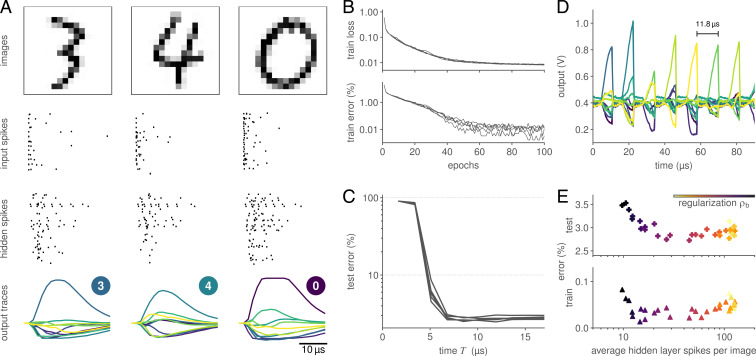
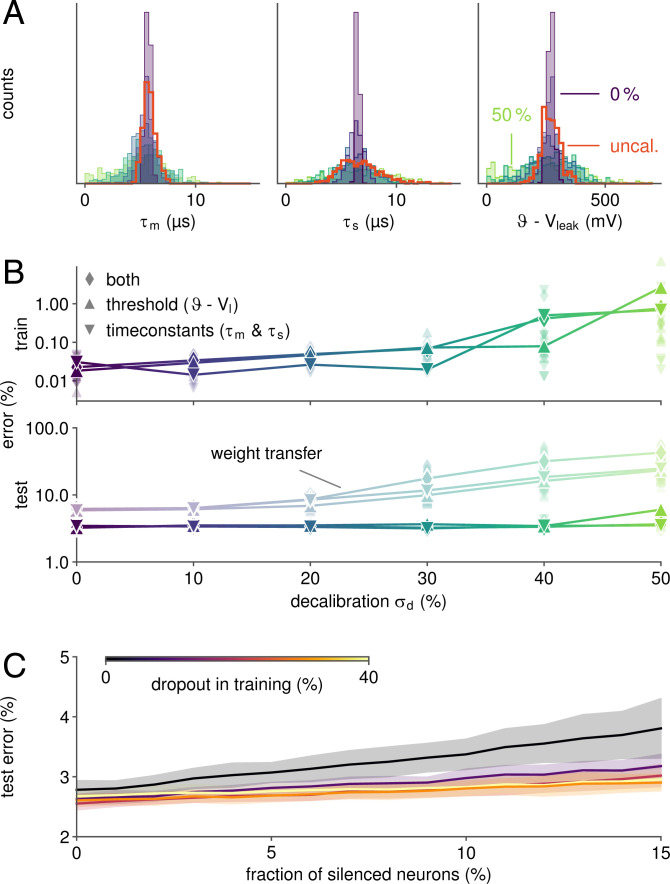
References
-
- Mnih V., et al. ., Playing Atari with deep reinforcement learning. arXiv [Preprint] (2013). https://arxiv.org/abs/1312.5602 23 (Accessed 23 December 2021).
-
- Silver D., et al. ., Mastering the game of go without human knowledge. Nature 550, 354–359 (2017). - PubMed
-
- Brown T. B., et al. ., Language models are few-shot learners. arXiv [Preprint] (2020). https://arxiv.org/abs/2005.14165 23 (Accessed 23 December 2021).
-
- Sterling P., Laughlin S., Principles of Neural Design (MIT Press, Cambridge, MA, 2015).
-
- Mead C., Neuromorphic electronic systems. Proc. IEEE 78, 1629–1636 (1990).
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
