

Narratives imagined in response to instrumental music reveal culture-bounded intersubjectivity
- PMID: 35064081
- PMCID: PMC8795501
- DOI: 10.1073/pnas.2110406119
Narratives imagined in response to instrumental music reveal culture-bounded intersubjectivity
Abstract
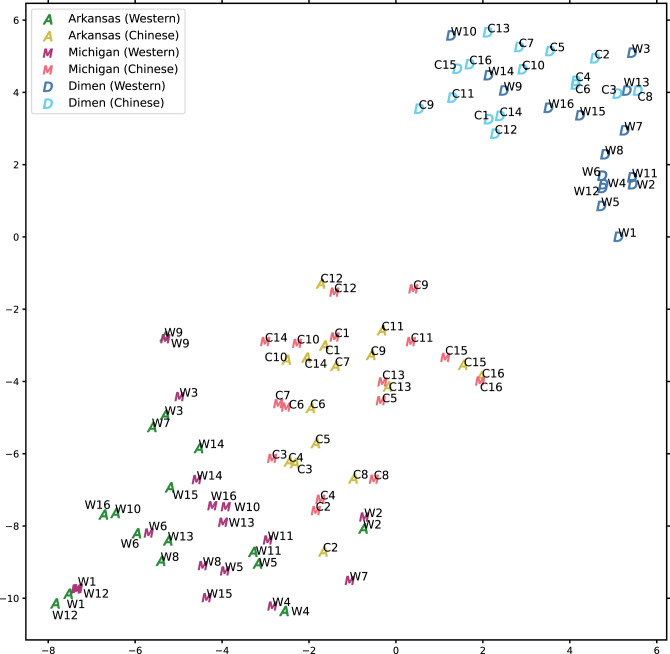
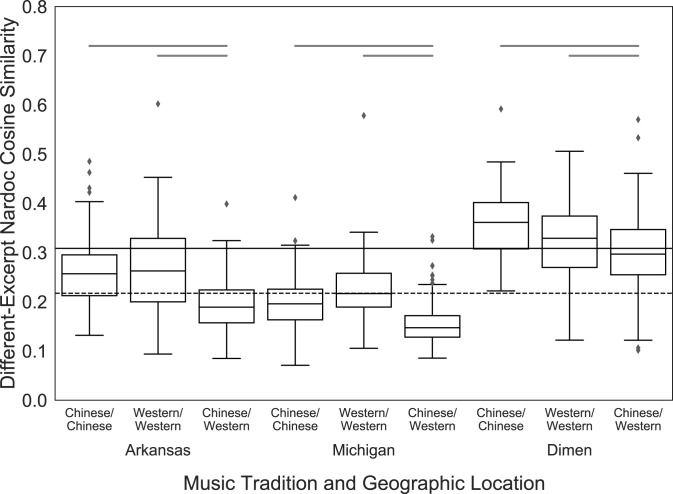
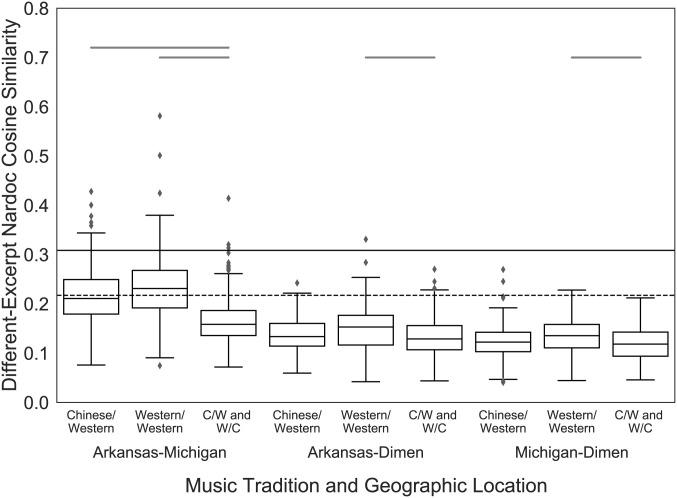
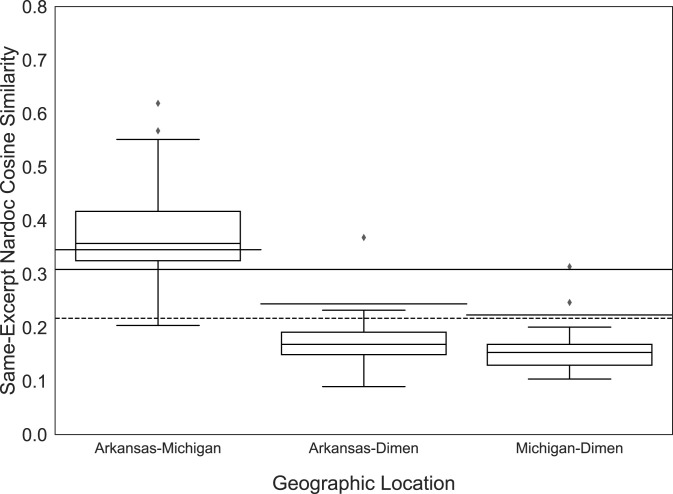
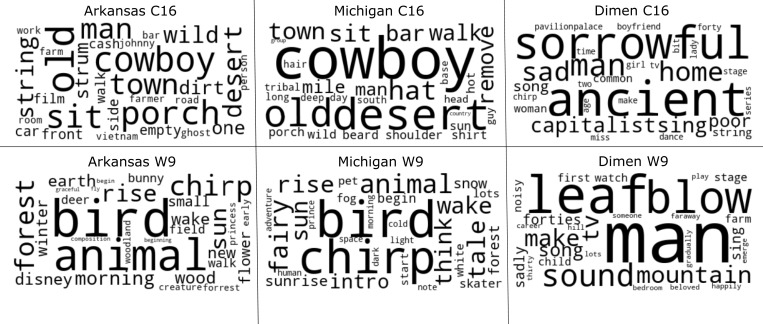
The scientific literature sometimes considers music an abstract stimulus, devoid of explicit meaning, and at other times considers it a universal language. Here, individuals in three geographically distinct locations spanning two cultures performed a highly unconstrained task: they provided free-response descriptions of stories they imagined while listening to instrumental music. Tools from natural language processing revealed that listeners provide highly similar stories to the same musical excerpts when they share an underlying culture, but when they do not, the generated stories show limited overlap. These results paint a more complex picture of music's power: music can generate remarkably similar stories in listeners' minds, but the degree to which these imagined narratives are shared depends on the degree to which culture is shared across listeners. Thus, music is neither an abstract stimulus nor a universal language but has semantic affordances shaped by culture, requiring more sustained attention from psychology.
Keywords: culture; imagination; music; narrative; semantics.
Copyright © 2022 the Author(s). Published by PNAS.
Conflict of interest statement
The authors declare no competing interest.
Figures
References
-
- Herbert R., Everyday Music Listening: Absorption, Dissociation and Trancing (Ashgate, 2011).
-
- Jakubowski K., “Musical imagery” in The Cambridge Handbook of the Imagination, Abraham A., Ed. (Cambridge, 2020), pp. 187–206.
-
- Margulis E. H., Wong P. C. M., Simchy-Gross R., McAuley J. D., What the music said: Narrative listening across cultures. Palgrave Commun. 5, 146 (2019).
-
- McAuley J. D., Wong P. C. M., Bellaiche L., Margulis E. H., What drives narrative engagement with music? Music Percept. 38, 509–521 (2021).
-
- McAuley J. D., Wong P. C. M., Mamidipaka A., Phillips N., Margulis E. H., Do you hear what I hear? Perceived narrative constitutes a semantic dimension for music. Cognition 212, 104712 (2021). - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
