

Semi-supervised incremental learning with few examples for discovering medical association rules
- PMID: 35073885
- PMCID: PMC8785547
- DOI: 10.1186/s12911-022-01755-3
Semi-supervised incremental learning with few examples for discovering medical association rules
Abstract
Background: Association Rules are one of the main ways to represent structural patterns underlying raw data. They represent dependencies between sets of observations contained in the data. The associations established by these rules are very useful in the medical domain, for example in the predictive health field. Classic algorithms for association rule mining give rise to huge amounts of possible rules that should be filtered in order to select those most likely to be true. Most of the proposed techniques for these tasks are unsupervised. However, the accuracy provided by unsupervised systems is limited. Conversely, resorting to annotated data for training supervised systems is expensive and time-consuming. The purpose of this research is to design a new semi-supervised algorithm that performs like supervised algorithms but uses an affordable amount of training data.
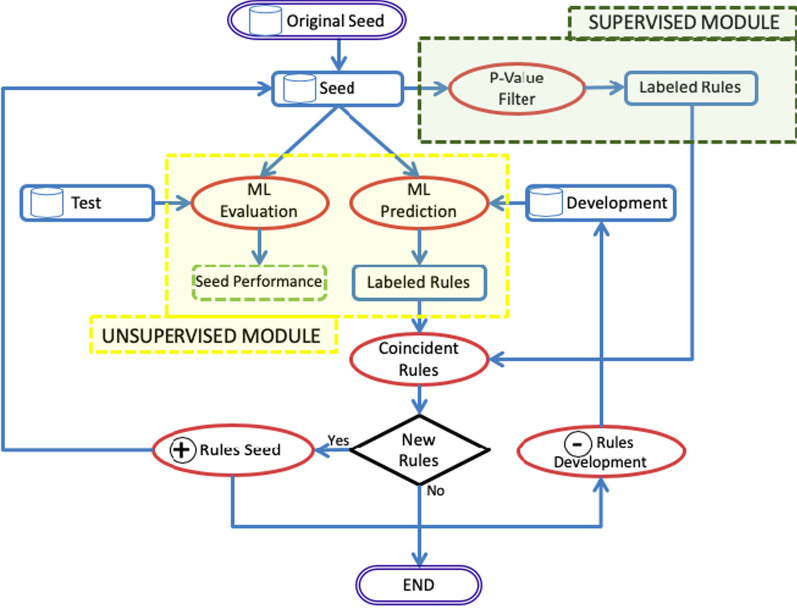
Methods: In this work we propose a new semi-supervised data mining model that combines unsupervised techniques (Fisher's exact test) with limited supervision. Starting with a small seed of annotated data, the model improves results (F-measure) obtained, using a fully supervised system (standard supervised ML algorithms). The idea is based on utilising the agreement between the predictions of the supervised system and those of the unsupervised techniques in a series of iterative steps.
Results: The new semi-supervised ML algorithm improves the results of supervised algorithms computed using the F-measure in the task of mining medical association rules, but training with an affordable amount of manually annotated data.
Conclusions: Using a small amount of annotated data (which is easily achievable) leads to results similar to those of a supervised system. The proposal may be an important step for the practical development of techniques for mining association rules and generating new valuable scientific medical knowledge.
Keywords: Association rules discovery; Machine learning; Medical records; Semi-supervised approach.
© 2022. The Author(s).
Conflict of interest statement
The authors declare that they have no competing interests.
Figures


Similar articles
-
Combining unsupervised, supervised and rule-based learning: the case of detecting patient allergies in electronic health records.BMC Med Inform Decis Mak. 2023 Sep 18;23(1):188. doi: 10.1186/s12911-023-02271-8. BMC Med Inform Decis Mak. 2023. PMID: 37723446 Free PMC article.
-
Unsupervised and self-supervised deep learning approaches for biomedical text mining.Brief Bioinform. 2021 Mar 22;22(2):1592-1603. doi: 10.1093/bib/bbab016. Brief Bioinform. 2021. PMID: 33569575 Review.
-
An unsupervised text mining method for relation extraction from biomedical literature.PLoS One. 2014 Jul 18;9(7):e102039. doi: 10.1371/journal.pone.0102039. eCollection 2014. PLoS One. 2014. PMID: 25036529 Free PMC article.
-
Incremental learning algorithm for large-scale semi-supervised ordinal regression.Neural Netw. 2022 May;149:124-136. doi: 10.1016/j.neunet.2022.02.004. Epub 2022 Feb 11. Neural Netw. 2022. PMID: 35228149
-
Iterative processes: a review of semi-supervised machine learning in rehabilitation science.Disabil Rehabil Assist Technol. 2020 Jul;15(5):515-520. doi: 10.1080/17483107.2019.1604831. Epub 2019 Jul 8. Disabil Rehabil Assist Technol. 2020. PMID: 31282778 Review.
Cited by
-
Discovering HIV related information by means of association rules and machine learning.Sci Rep. 2022 Oct 28;12(1):18208. doi: 10.1038/s41598-022-22695-y. Sci Rep. 2022. PMID: 36307506 Free PMC article.
-
Patient-Generated Collections for Organizing Electronic Health Record Data to Elevate Personal Meaning, Improve Actionability, and Support Patient-Health Care Provider Communication: Think-Aloud Evaluation Study.JMIR Hum Factors. 2025 Feb 3;12:e50331. doi: 10.2196/50331. JMIR Hum Factors. 2025. PMID: 39899851 Free PMC article.
References
-
- Masuda Y. The yusho rice oil poisoning incident. In: Schecter A, editor. Dioxins and health. Berlin: Springer; 1994. pp. 633–659.
-
- Hämäläinen W. Efficient search methods for statistical dependency rules. Fundam Inform. 2011;113(2):117–50. doi: 10.3233/FI-2011-603. - DOI
-
- Ghafari SM, Tjortjis C. A survey on association rules mining using heuristics. Wiley Interdiscip Rev Data Min Knowl Discov. 2019 doi: 10.1002/widm.1307. - DOI
-
- Yarowsky D. Unsupervised word sense disambiguation rivaling supervised methods. In: 33rd Annual meeting of the association for computational linguistics, 26–30 June 1995, MIT, Cambridge, Massachusetts, USA, Proceedings., 1995. p. 189–196. http://aclweb.org/anthology/P/P95/P95-1026.pdf
-
- Pearson KX. On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling. Lond Edinb Dublin Philos Mag J Sci. 1900;50(302):157–75. doi: 10.1080/14786440009463897. - DOI
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
