

Predictive structured-unstructured interactions in EHR models: A case study of suicide prediction
- PMID: 35087182
- PMCID: PMC8795240
- DOI: 10.1038/s41746-022-00558-0
Predictive structured-unstructured interactions in EHR models: A case study of suicide prediction
Abstract
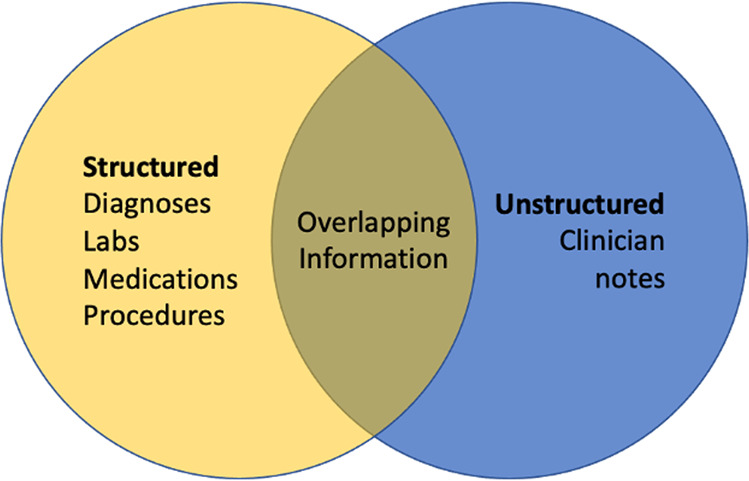
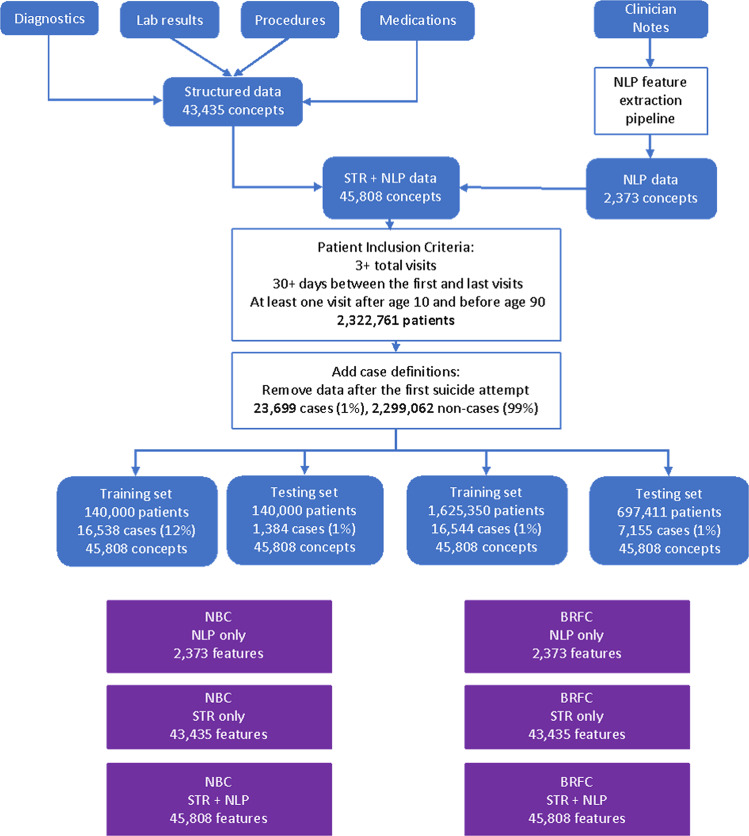
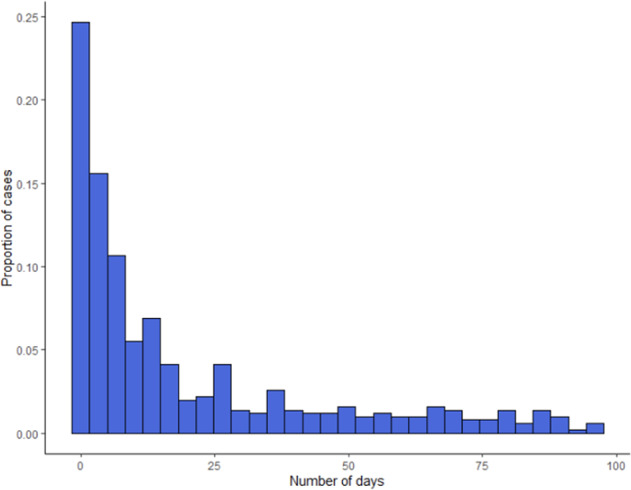
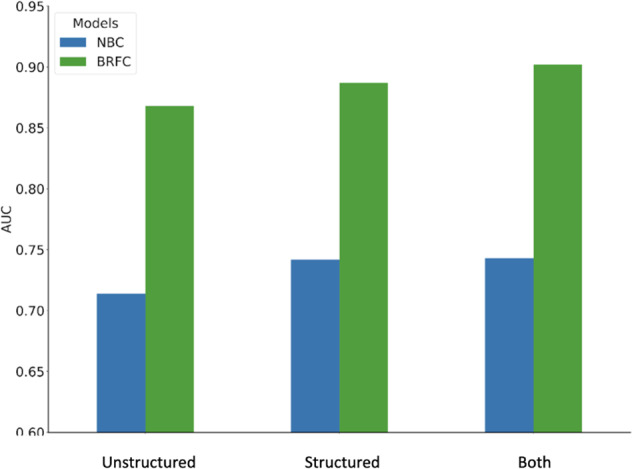
Clinical risk prediction models powered by electronic health records (EHRs) are becoming increasingly widespread in clinical practice. With suicide-related mortality rates rising in recent years, it is becoming increasingly urgent to understand, predict, and prevent suicidal behavior. Here, we compare the predictive value of structured and unstructured EHR data for predicting suicide risk. We find that Naive Bayes Classifier (NBC) and Random Forest (RF) models trained on structured EHR data perform better than those based on unstructured EHR data. An NBC model trained on both structured and unstructured data yields similar performance (AUC = 0.743) to an NBC model trained on structured data alone (0.742, p = 0.668), while an RF model trained on both data types yields significantly better results (AUC = 0.903) than an RF model trained on structured data alone (0.887, p < 0.001), likely due to the RF model's ability to capture interactions between the two data types. To investigate these interactions, we propose and implement a general framework for identifying specific structured-unstructured feature pairs whose interactions differ between case and non-case cohorts, and thus have the potential to improve predictive performance and increase understanding of clinical risk. We find that such feature pairs tend to capture heterogeneous pairs of general concepts, rather than homogeneous pairs of specific concepts. These findings and this framework can be used to improve current and future EHR-based clinical modeling efforts.
© 2022. The Author(s).
Conflict of interest statement
Dr. Smoller reported serving as an unpaid member of the Bipolar/Depression Research Community Advisory Panel of 23andMe and a member of the Leon Levy Foundation Neuroscience Advisory Board, and receiving an honorarium for an internal seminar at Biogen Inc. Dr. Nock receives textbook royalties from Macmillan and Pearson publishers and has been a paid consultant in the past year for Microsoft and for a legal case regarding a death by suicide. He is an unpaid scientific advisor for TalkLife and Empatica. The remaining authors declare no competing interests.
Figures
References
-
- Gulati, G., Cullen, W. & Kelly, B. Psychiatry Algorithms for Primary Care (John Wiley & Sons, 2021).
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
