

A Risk-Stratification Machine Learning Framework for the Prediction of Coronary Artery Disease Severity: Insights From the GESS Trial
- PMID: 35118145
- PMCID: PMC8804295
- DOI: 10.3389/fcvm.2021.812182
A Risk-Stratification Machine Learning Framework for the Prediction of Coronary Artery Disease Severity: Insights From the GESS Trial
Abstract
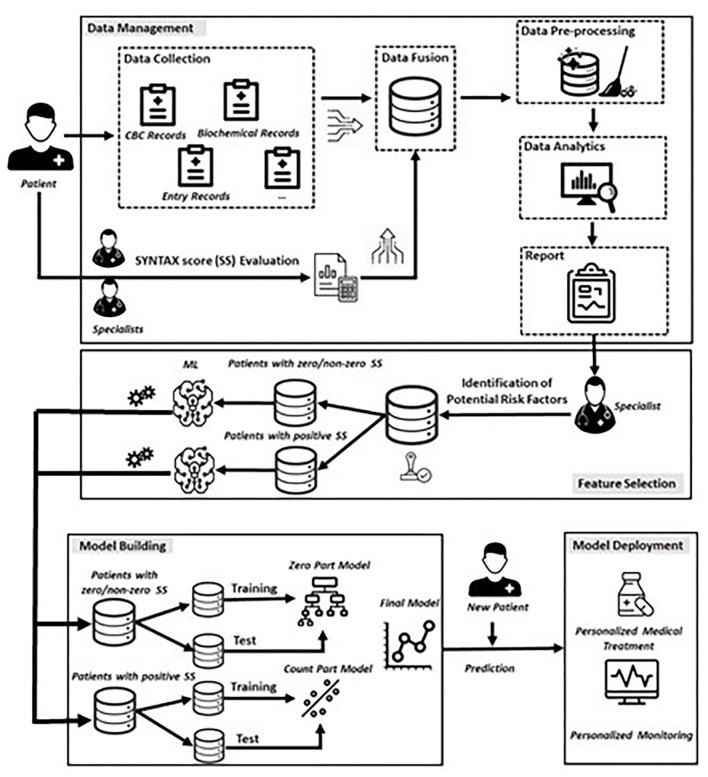
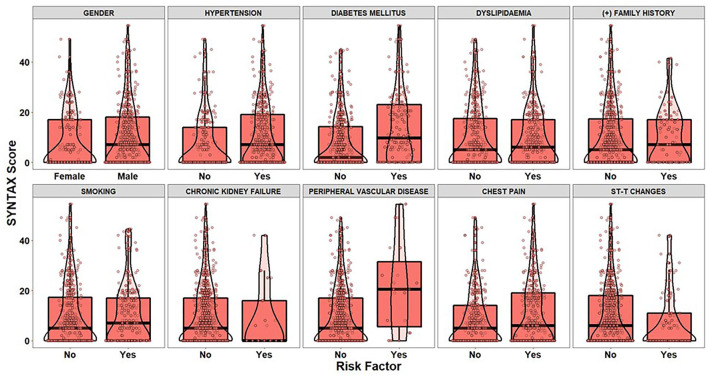
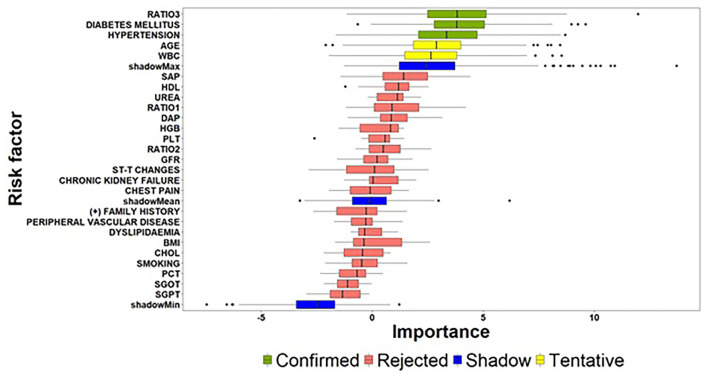
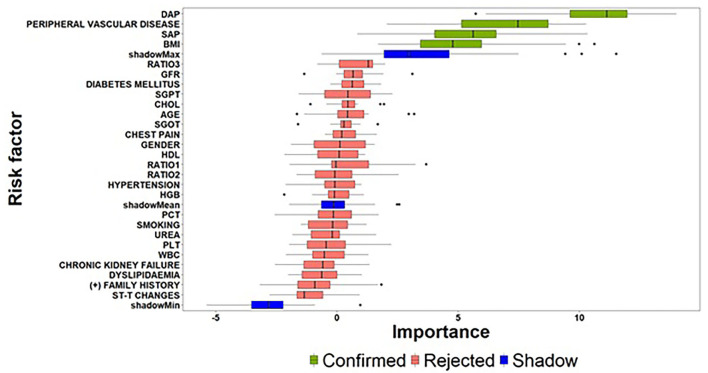
Our study aims to develop a data-driven framework utilizing heterogenous electronic medical and clinical records and advanced Machine Learning (ML) approaches for: (i) the identification of critical risk factors affecting the complexity of Coronary Artery Disease (CAD), as assessed via the SYNTAX score; and (ii) the development of ML prediction models for accurate estimation of the expected SYNTAX score. We propose a two-part modeling technique separating the process into two distinct phases: (a) a binary classification task for predicting, whether a patient is more likely to present with a non-zero SYNTAX score; and (b) a regression task to predict the expected SYNTAX score accountable to individual patients with a non-zero SYNTAX score. The framework is based on data collected from the GESS trial (NCT03150680) comprising electronic medical and clinical records for 303 adult patients with suspected CAD, having undergone invasive coronary angiography in AHEPA University Hospital of Thessaloniki, Greece. The deployment of the proposed approach demonstrated that atherogenic index of plasma levels, diabetes mellitus and hypertension can be considered as important risk factors for discriminating patients into zero- and non-zero SYNTAX score groups, whereas diastolic and systolic arterial blood pressure, peripheral vascular disease and body mass index can be considered as significant risk factors for providing an accurate estimation of the expected SYNTAX score, given that a patient belongs to the non-zero SYNTAX score group. The experimental findings utilizing the identified set of important risk factors indicate a sufficient prediction performance for the Support Vector Machine model (classification task) with an F-measure score of ~0.71 and the Support Vector Regression model (regression task) with a median absolute error value of ~6.5. The proposed data-driven framework described herein present evidence of the prediction capacity and the potential clinical usefulness of the developed risk-stratification models. However, further experimentation in a larger clinical setting is needed to ensure the practical utility of the presented models in a way to contribute to a more personalized management and counseling of CAD patients.
Keywords: SYNTAX score; coronary artery disease; machine learning; personalized (precision) medicine; risk-stratification model.
Copyright © 2022 Mittas, Chatzopoulou, Kyritsis, Papagiannopoulos, Theodoroula, Papazoglou, Karagiannidis, Sofidis, Moysidis, Stalikas, Papa, Chatzidimitriou, Sianos, Angelis and Vizirianakis.
Conflict of interest statement
FC is employed by Labnet Laboratories. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures
Similar articles
-
Prediction of coronary artery disease severity in lower extremity artery disease patients: A correlation study of TASC II classification, Syntax and Syntax II scores.Cardiol J. 2017;24(5):495-501. doi: 10.5603/CJ.a2017.0033. Epub 2017 Mar 29. Cardiol J. 2017. PMID: 28353312
-
Correlation of the severity of coronary artery disease with patients' metabolic profile- rationale, design and baseline patient characteristics of the CorLipid trial.BMC Cardiovasc Disord. 2021 Feb 8;21(1):79. doi: 10.1186/s12872-021-01865-2. BMC Cardiovasc Disord. 2021. PMID: 33557756 Free PMC article.
-
Correlation between the Finnish Diabetes risk Score and the severity of coronary artery disease.Vojnosanit Pregl. 2014 May;71(5):474-80. Vojnosanit Pregl. 2014. PMID: 26137713
-
Integration of non-invasive functional assessments with anatomical risk stratification in complex coronary artery disease: the non-invasive functional SYNTAX score.Cardiovasc Diagn Ther. 2017 Apr;7(2):151-158. doi: 10.21037/cdt.2017.03.19. Cardiovasc Diagn Ther. 2017. PMID: 28540210 Free PMC article. Review.
-
Data-driven modeling and prediction of blood glucose dynamics: Machine learning applications in type 1 diabetes.Artif Intell Med. 2019 Jul;98:109-134. doi: 10.1016/j.artmed.2019.07.007. Epub 2019 Jul 26. Artif Intell Med. 2019. PMID: 31383477 Review.
Cited by
-
Computational Cardiology: The Door to the Future of Interventional Cardiology.JACC Adv. 2023 Sep 16;2(8):100625. doi: 10.1016/j.jacadv.2023.100625. eCollection 2023 Oct. JACC Adv. 2023. PMID: 38938342 Free PMC article.
-
A Systematic Review: Do the Use of Machine Learning, Deep Learning, and Artificial Intelligence Improve Patient Outcomes in Acute Myocardial Ischemia Compared to Clinician-Only Approaches?Cureus. 2023 Aug 5;15(8):e43003. doi: 10.7759/cureus.43003. eCollection 2023 Aug. Cureus. 2023. PMID: 37674942 Free PMC article. Review.
-
Machine learning approaches that use clinical, laboratory, and electrocardiogram data enhance the prediction of obstructive coronary artery disease.Sci Rep. 2023 Aug 3;13(1):12635. doi: 10.1038/s41598-023-39911-y. Sci Rep. 2023. PMID: 37537293 Free PMC article.
-
Prognostic Implications of Clinical, Laboratory and Echocardiographic Biomarkers in Patients with Acute Myocardial Infarction-Rationale and Design of the ''CLEAR-AMI Study''.J Clin Med. 2023 Sep 2;12(17):5726. doi: 10.3390/jcm12175726. J Clin Med. 2023. PMID: 37685793 Free PMC article.
-
Association of clinical, laboratory and imaging biomarkers with the occurrence of acute myocardial infarction in patients without standard modifiable risk factors - rationale and design of the "Beyond-SMuRFs Study".BMC Cardiovasc Disord. 2023 Mar 23;23(1):149. doi: 10.1186/s12872-023-03180-4. BMC Cardiovasc Disord. 2023. PMID: 36959584 Free PMC article.
References
-
- Vizirianakis IS, Miliotou AN, Mystridis GA, Andriotis EG, Andreadis II, Papadopoulou LC et al. Tackling pharmacological response heterogeneity by PBPK modeling to advance precision medicine productivity of nanotechnology and genomics therapeutics. Expert Rev Precis Med Drug Dev. (2019) 4:139–51. 10.1080/23808993.2019.1605828 - DOI
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous