

Mice alternate between discrete strategies during perceptual decision-making
- PMID: 35132235
- PMCID: PMC8890994
- DOI: 10.1038/s41593-021-01007-z
Mice alternate between discrete strategies during perceptual decision-making
Abstract
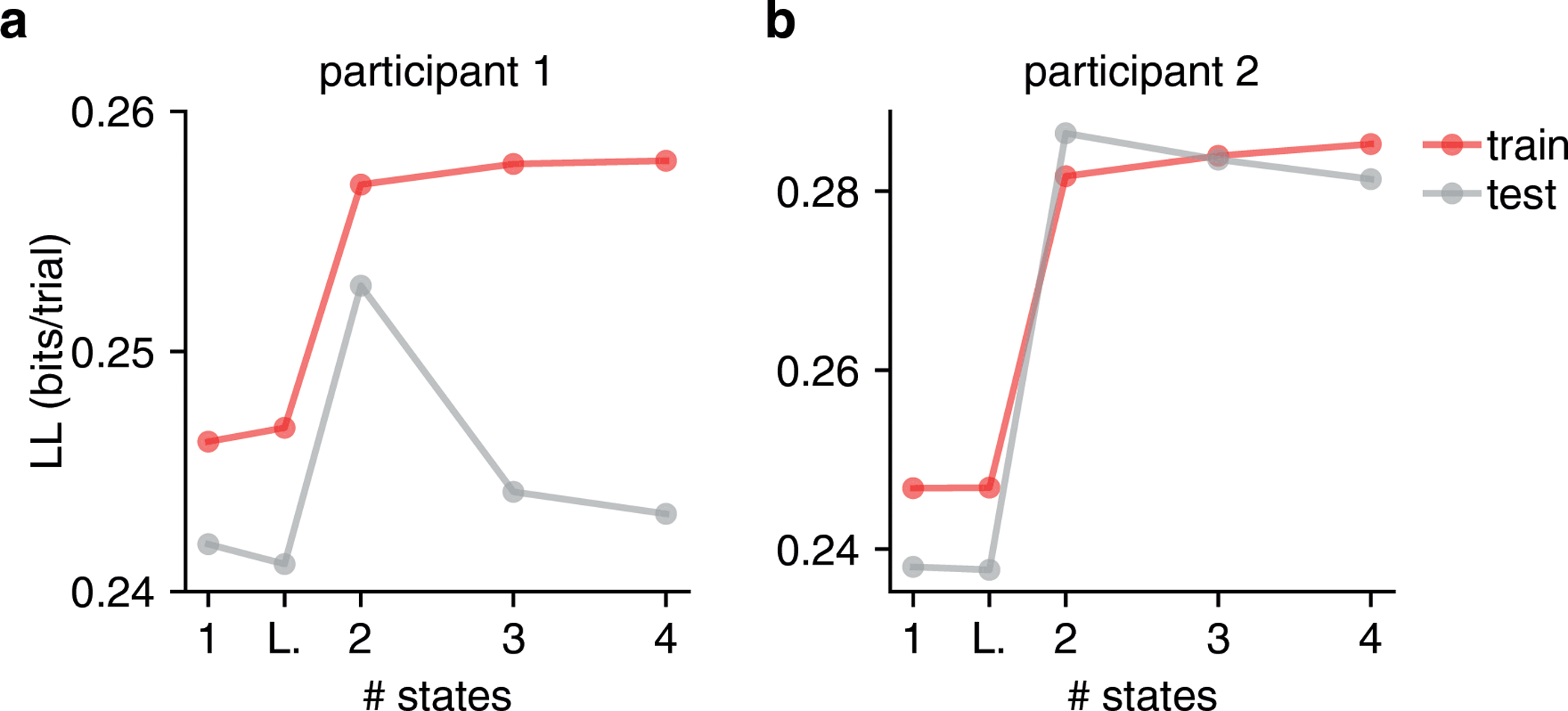
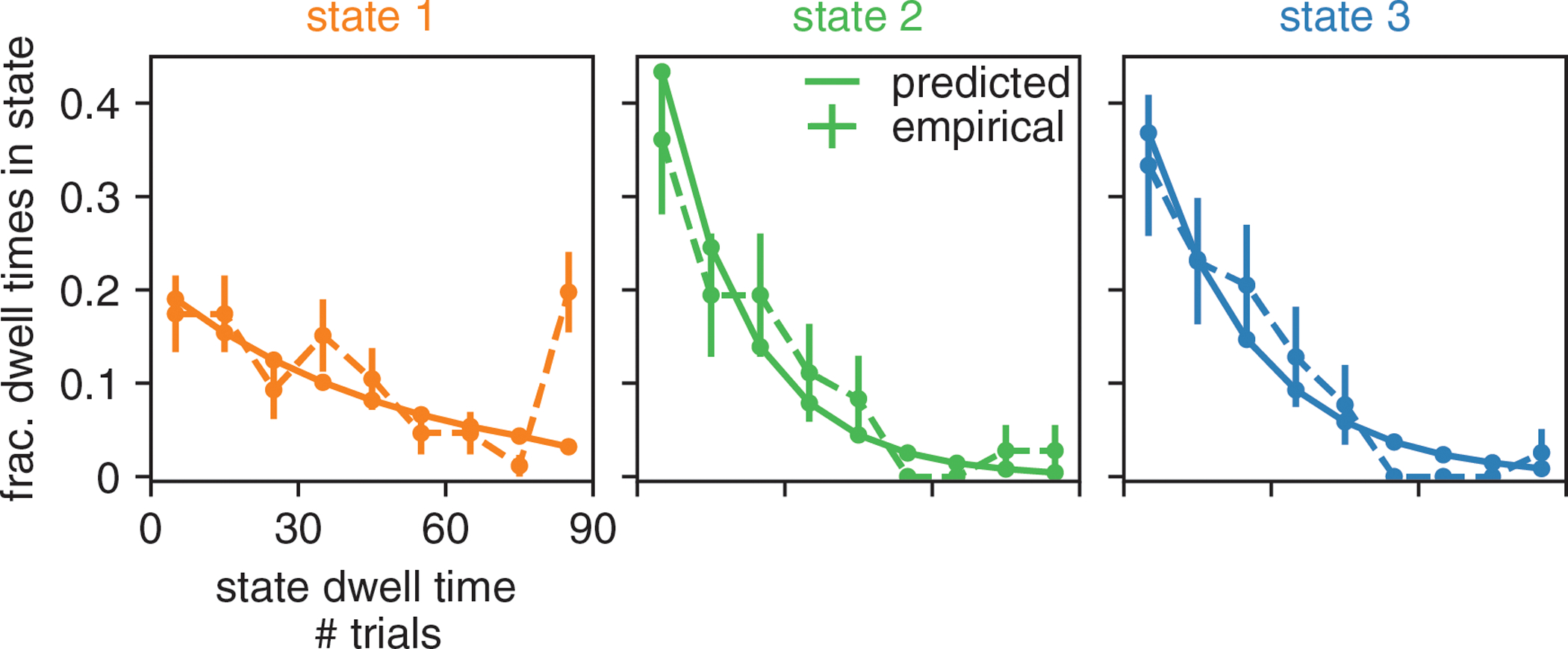
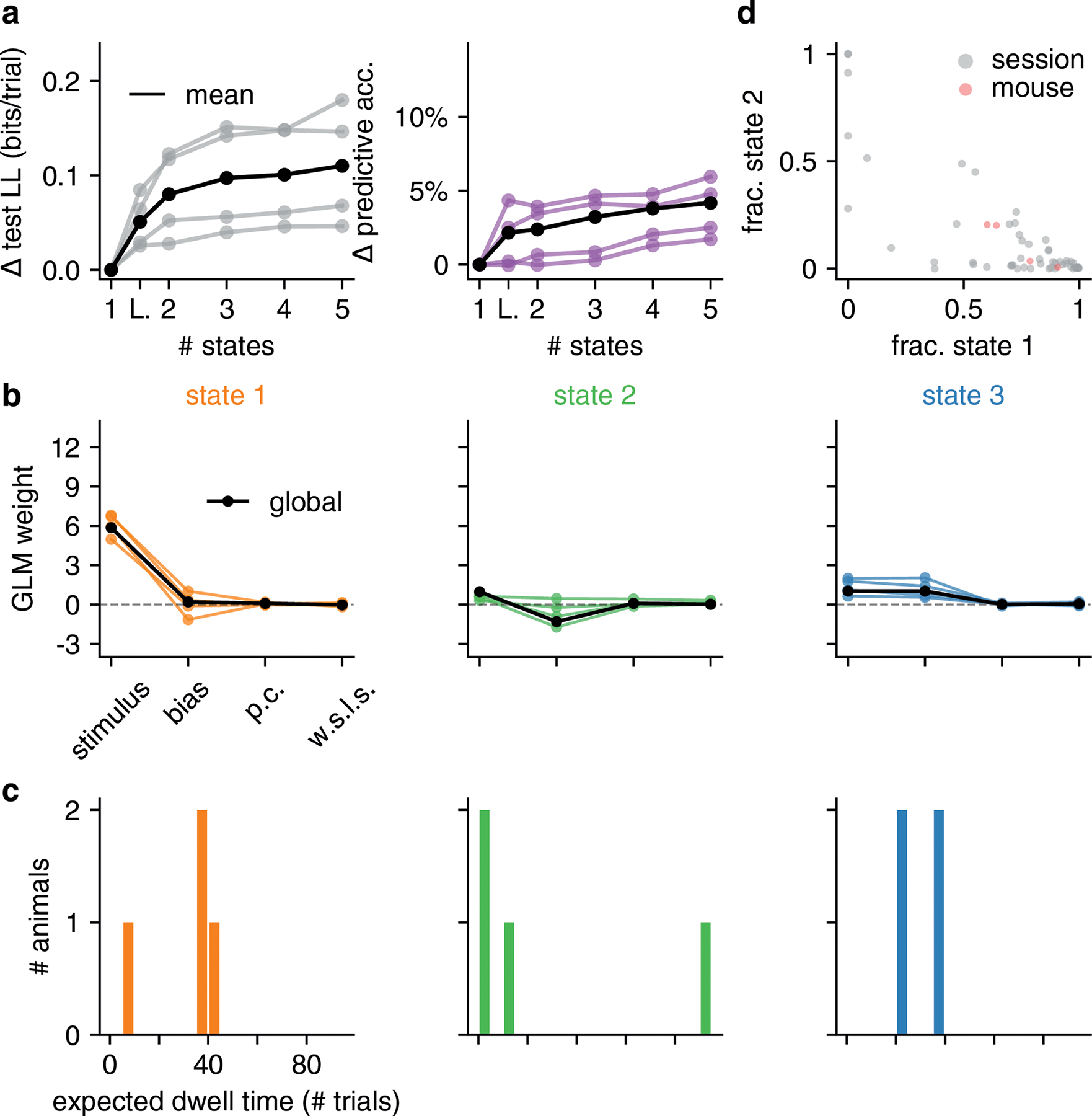
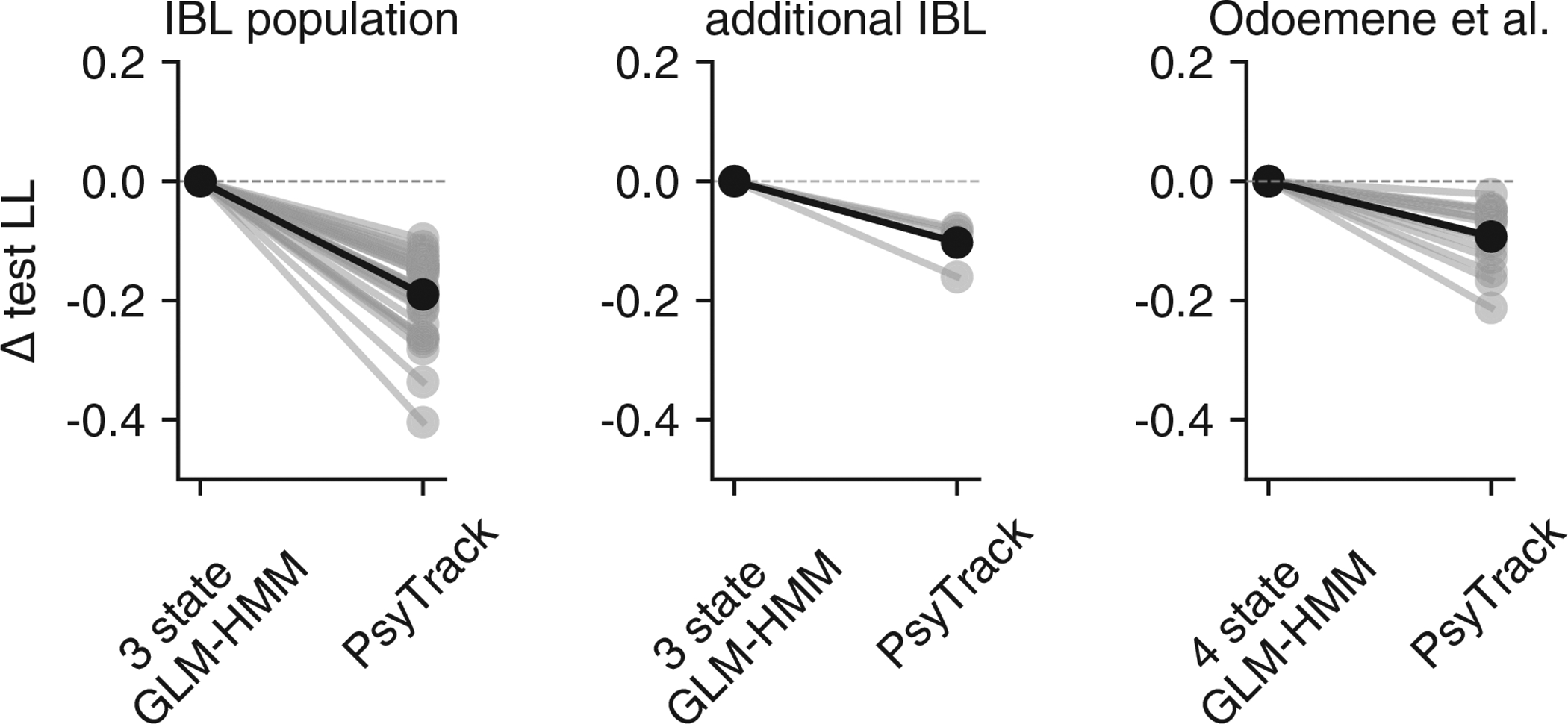
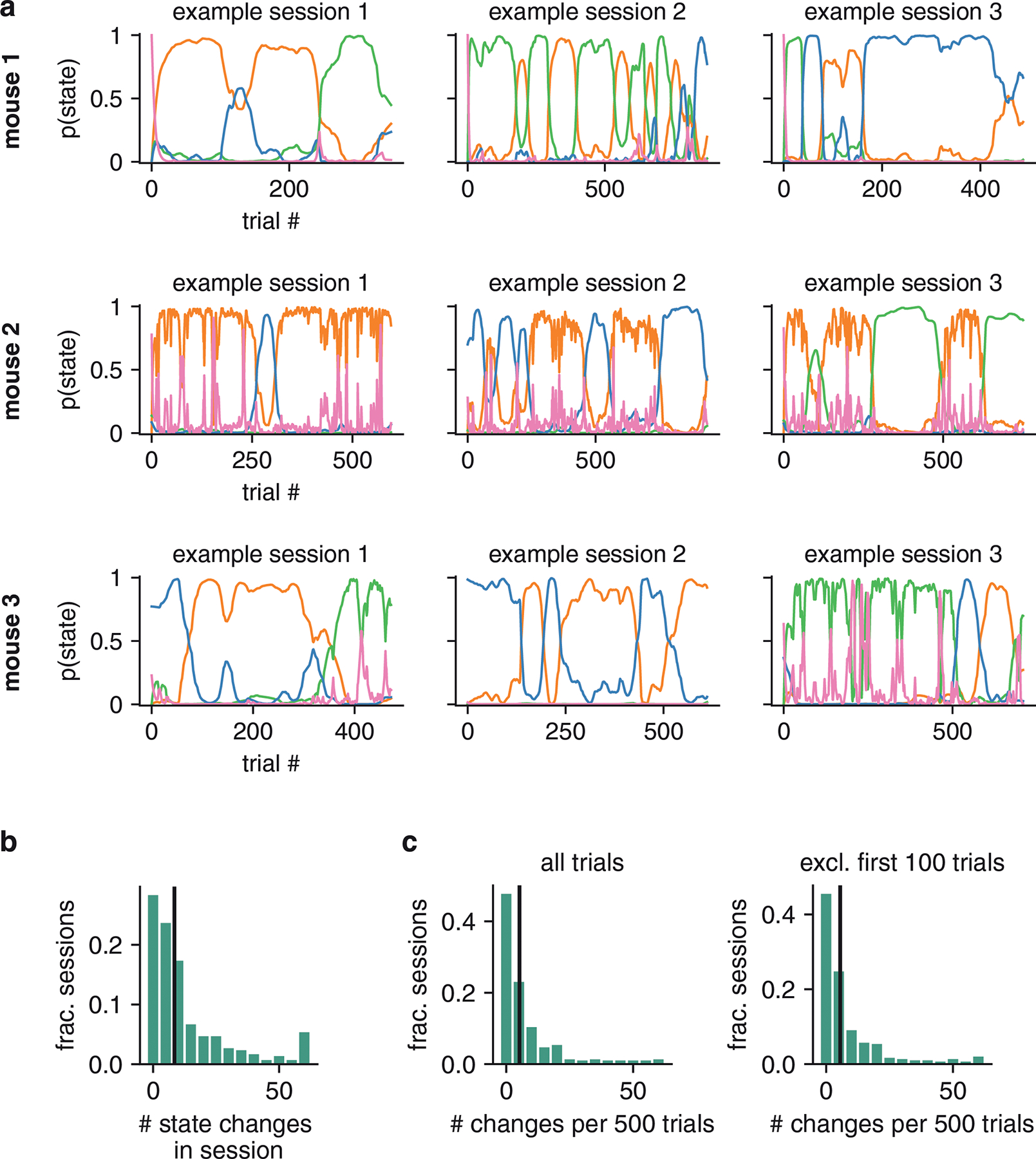
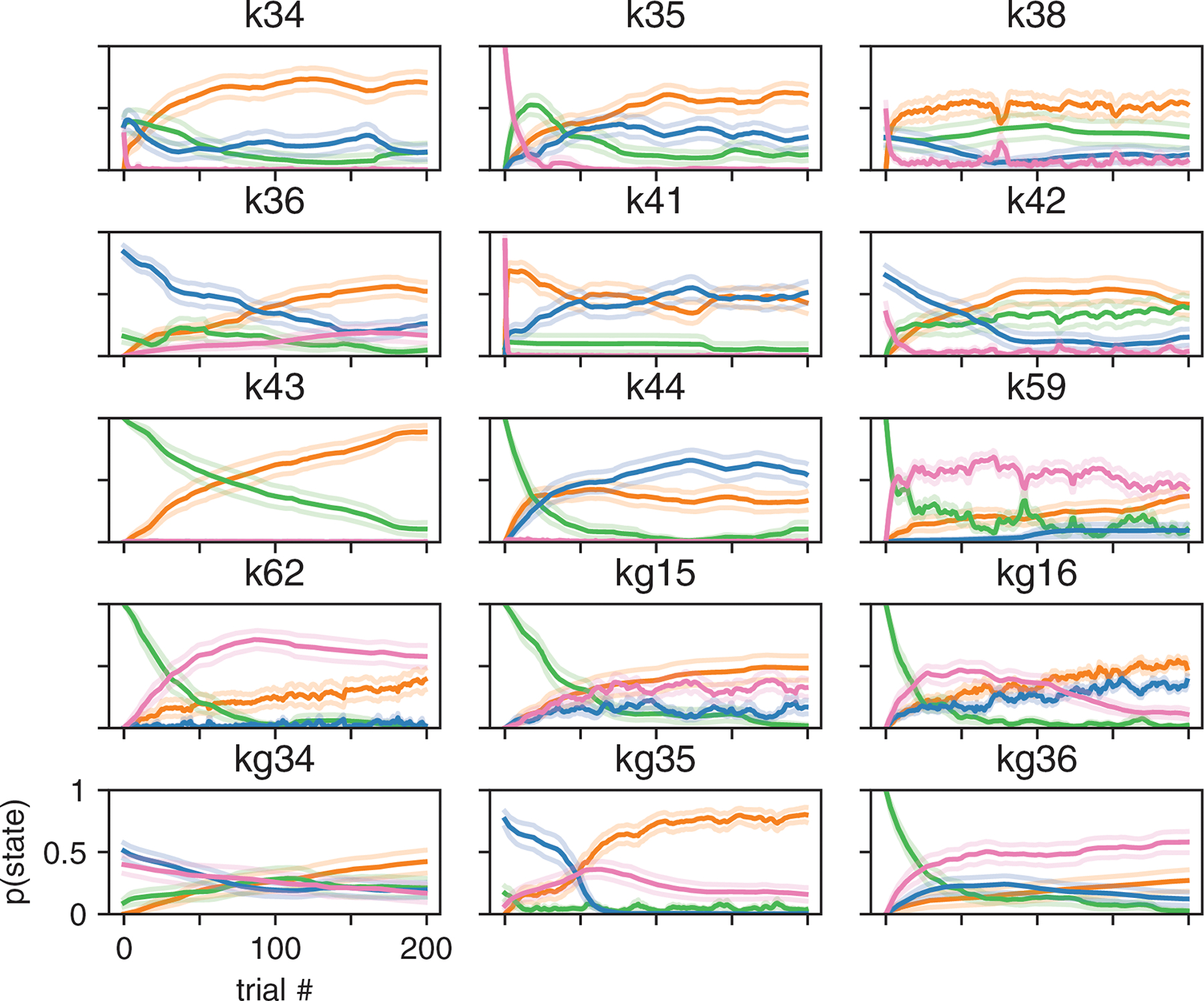
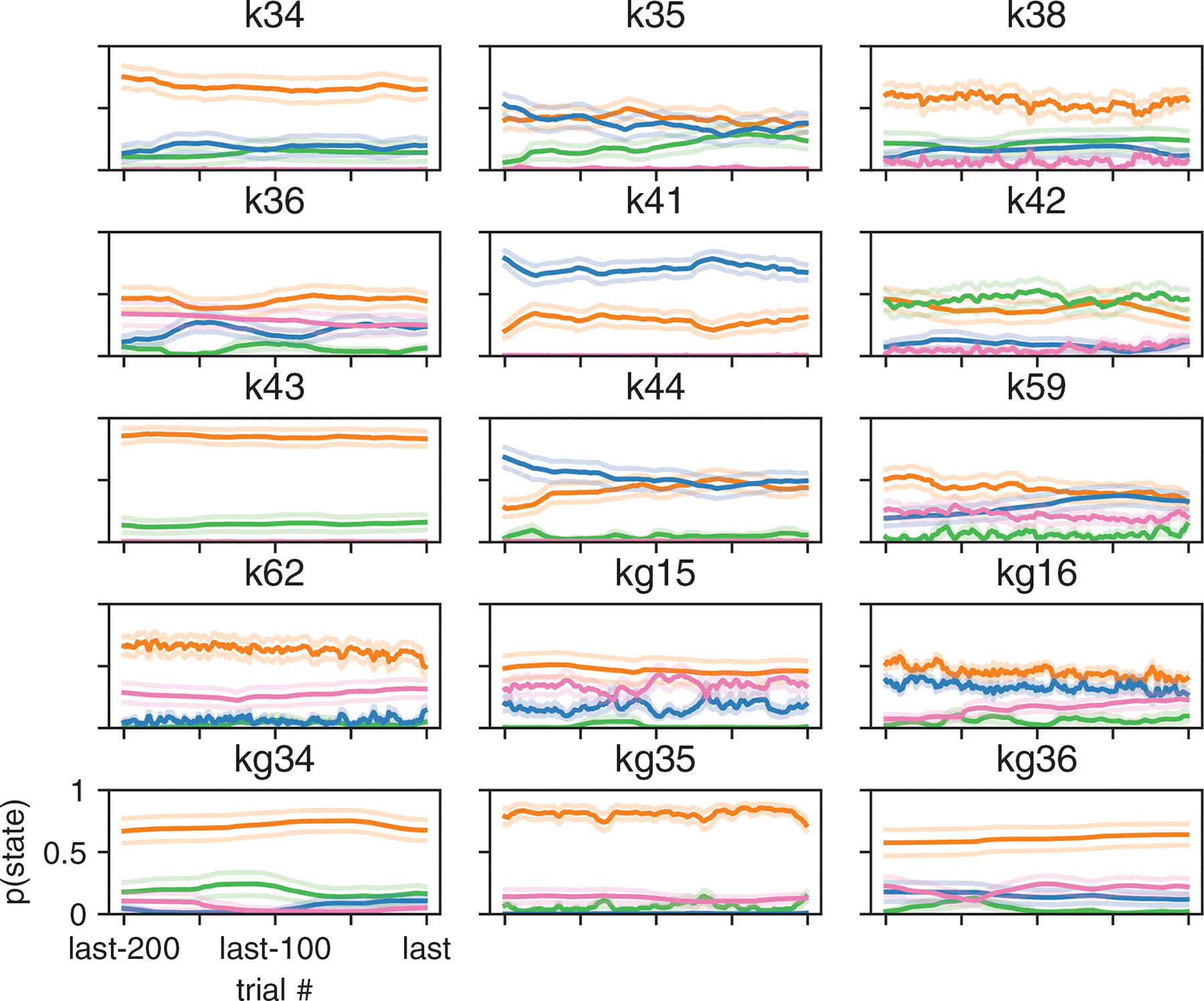
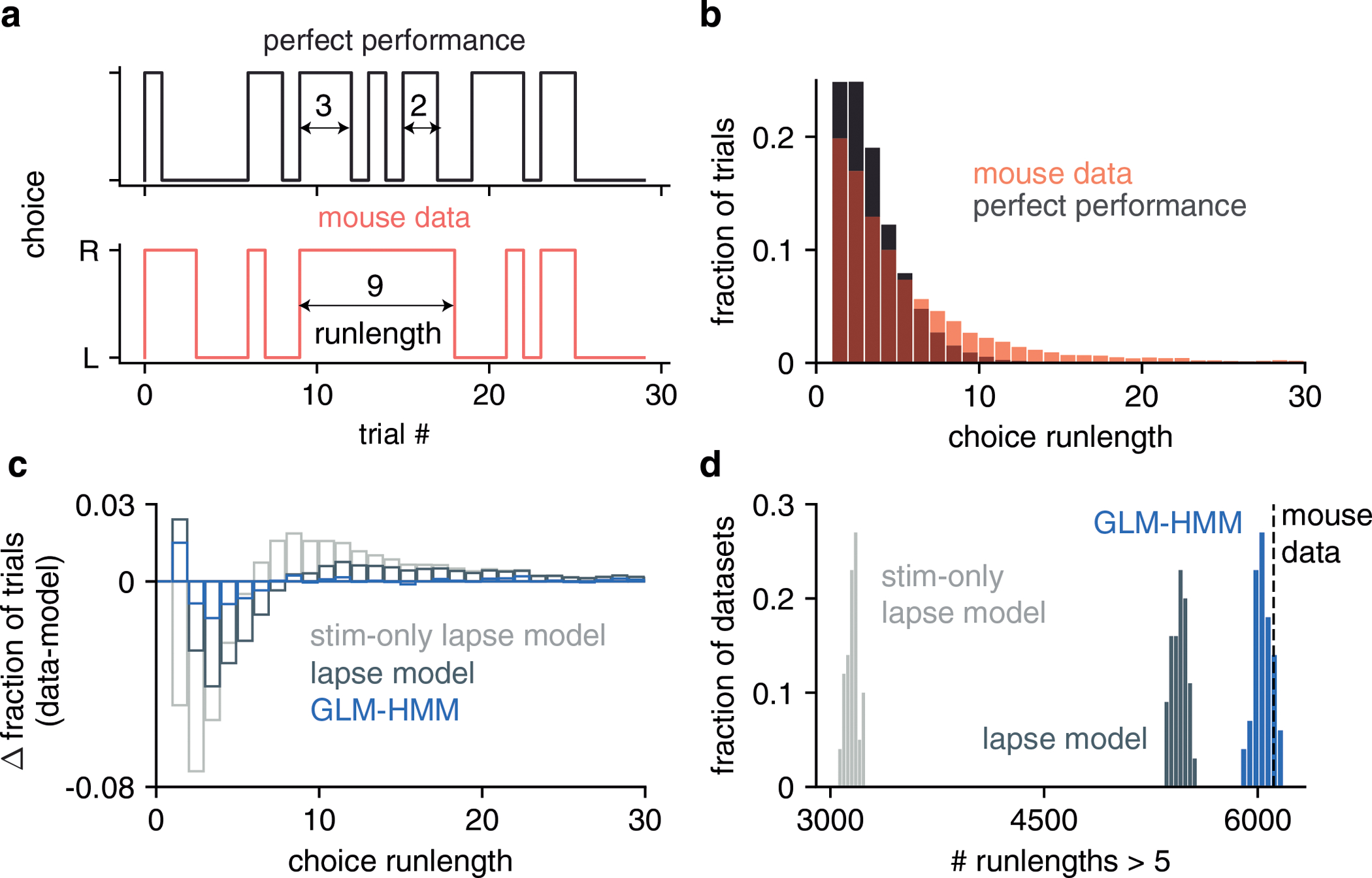
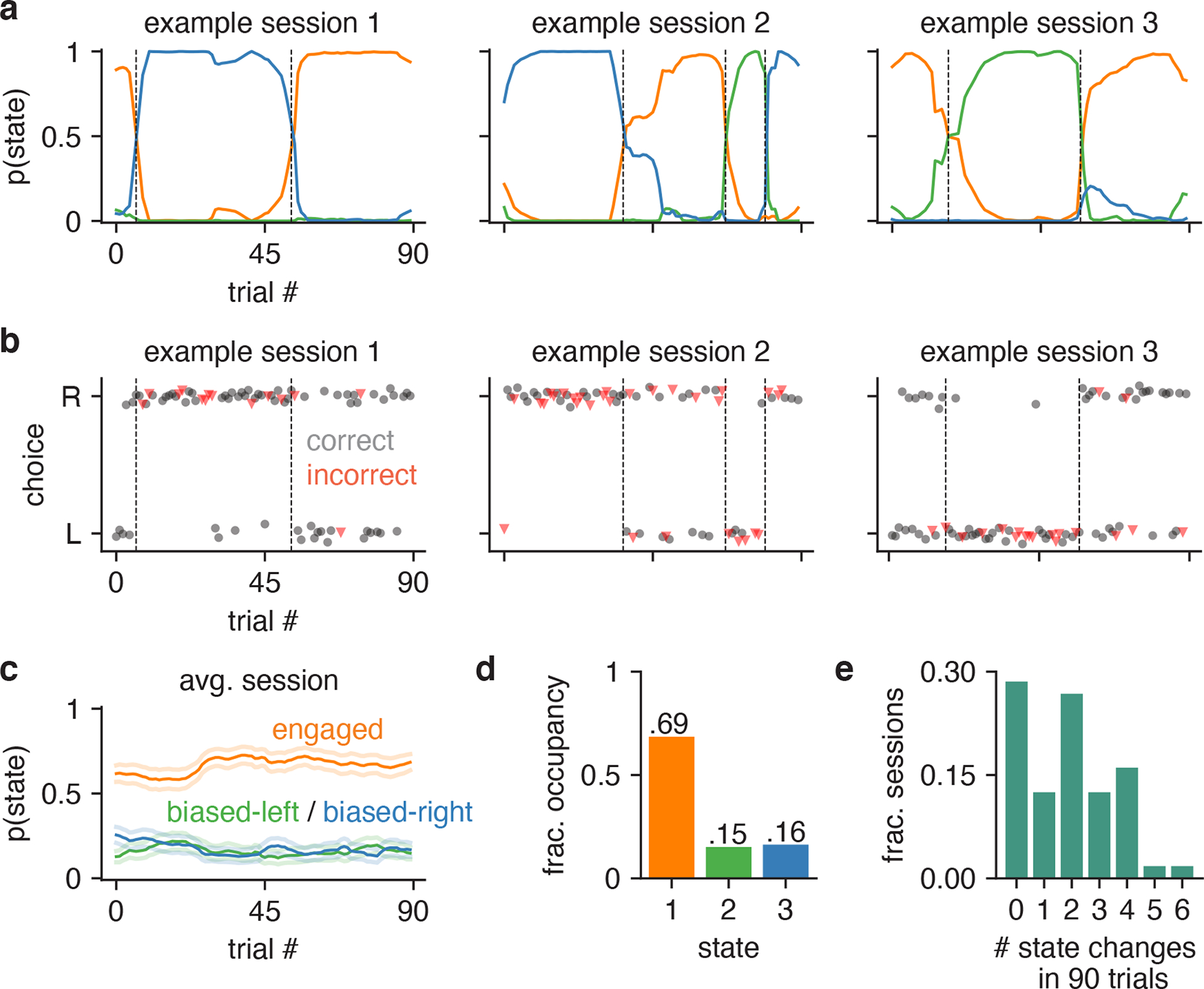
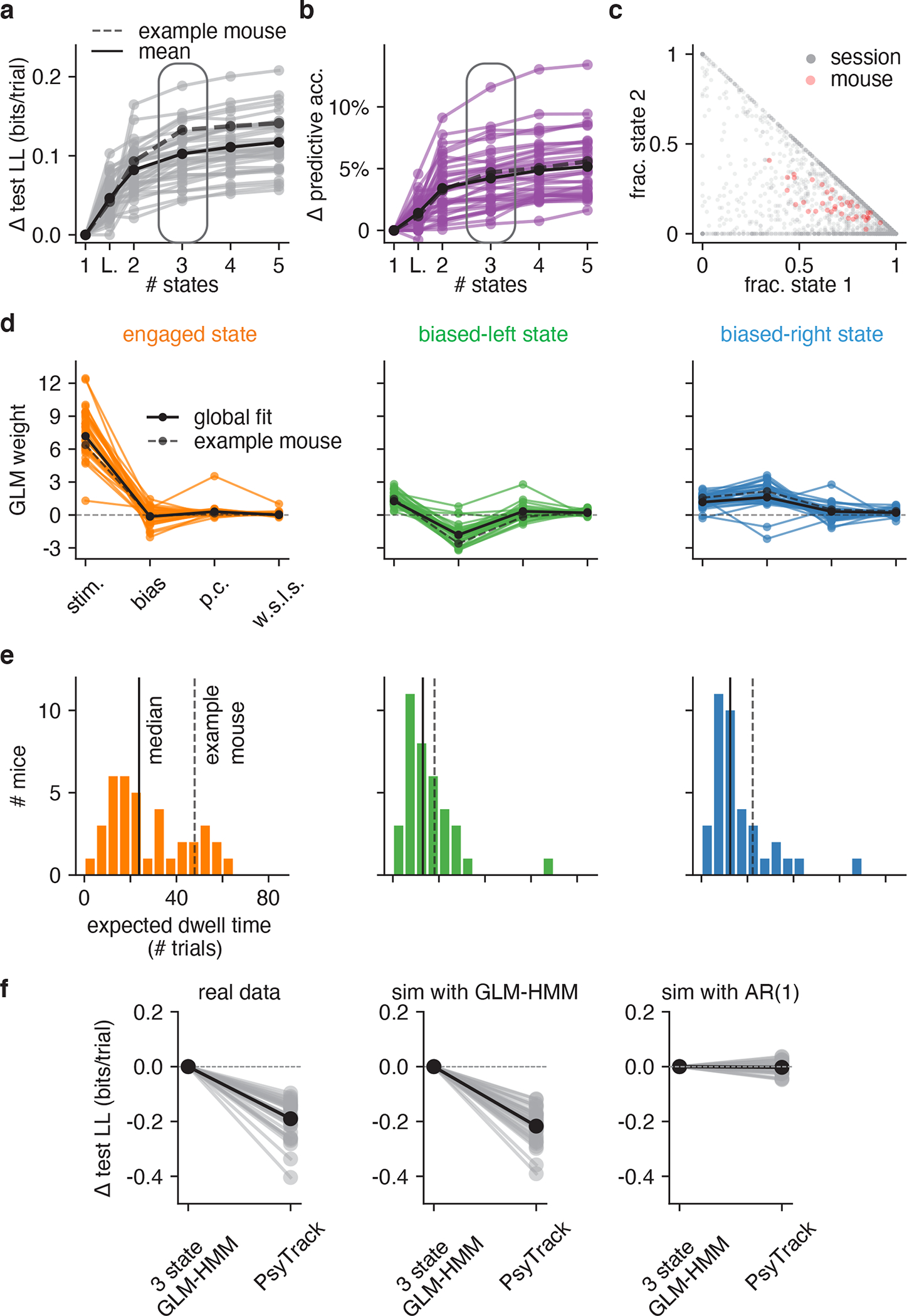
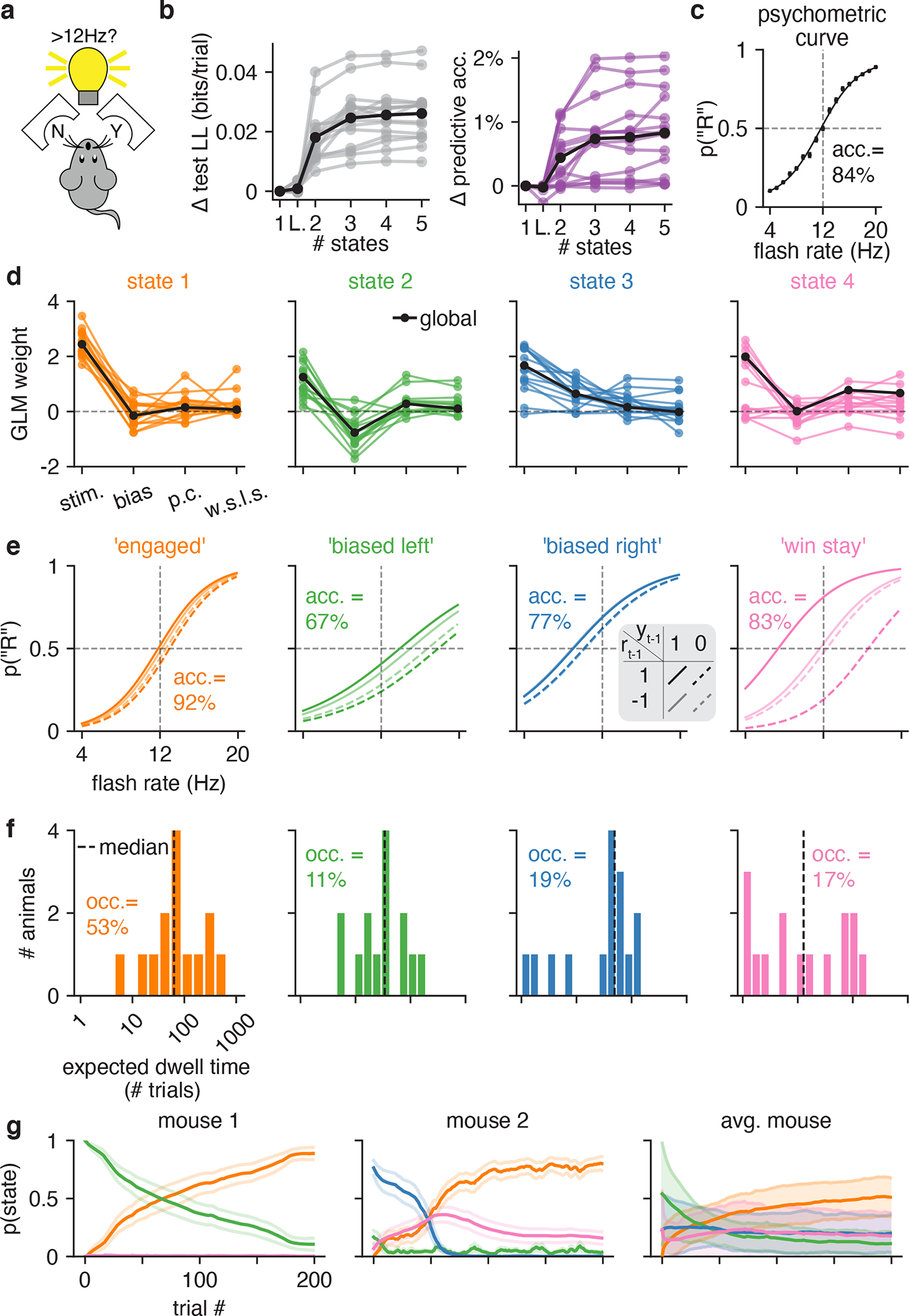
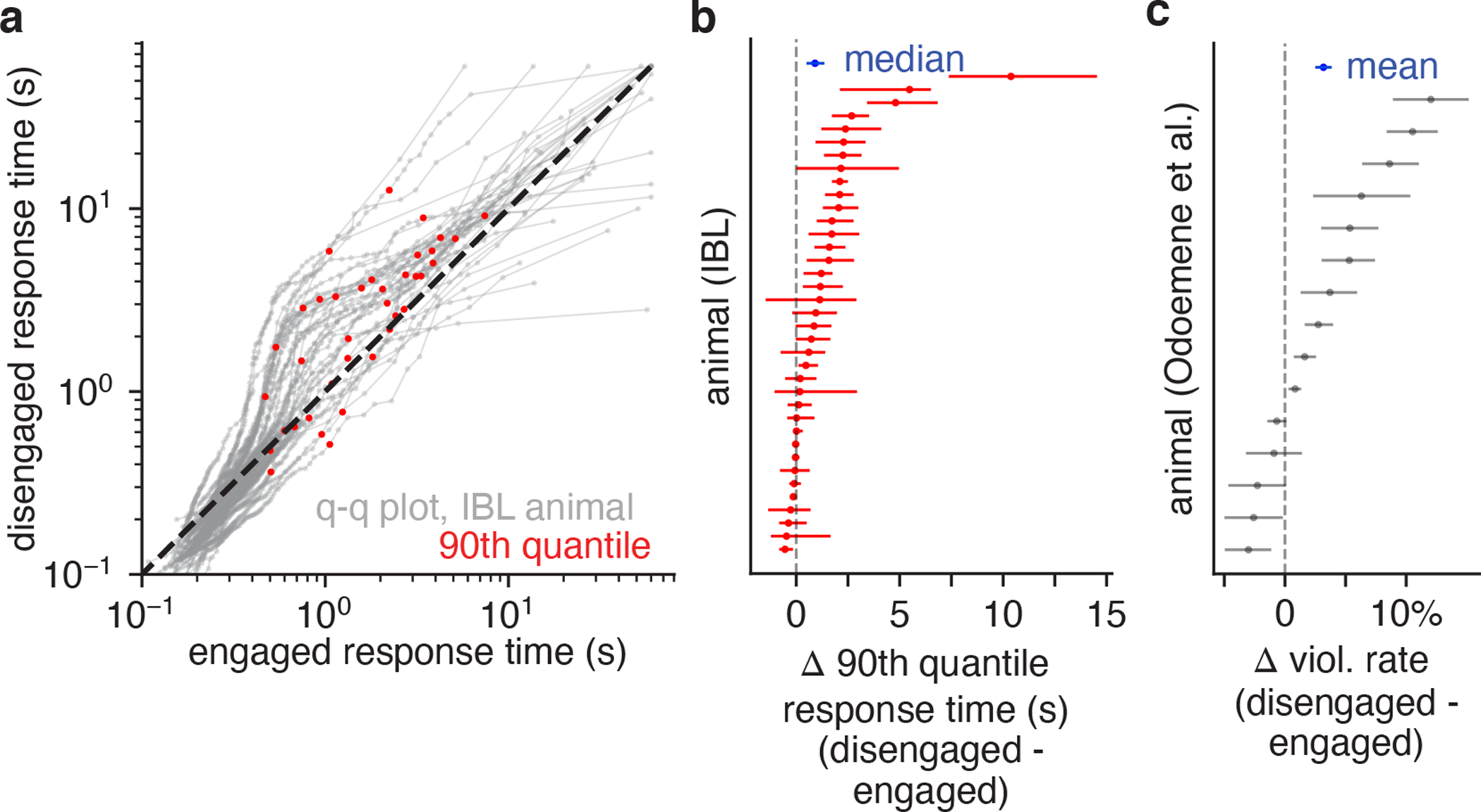
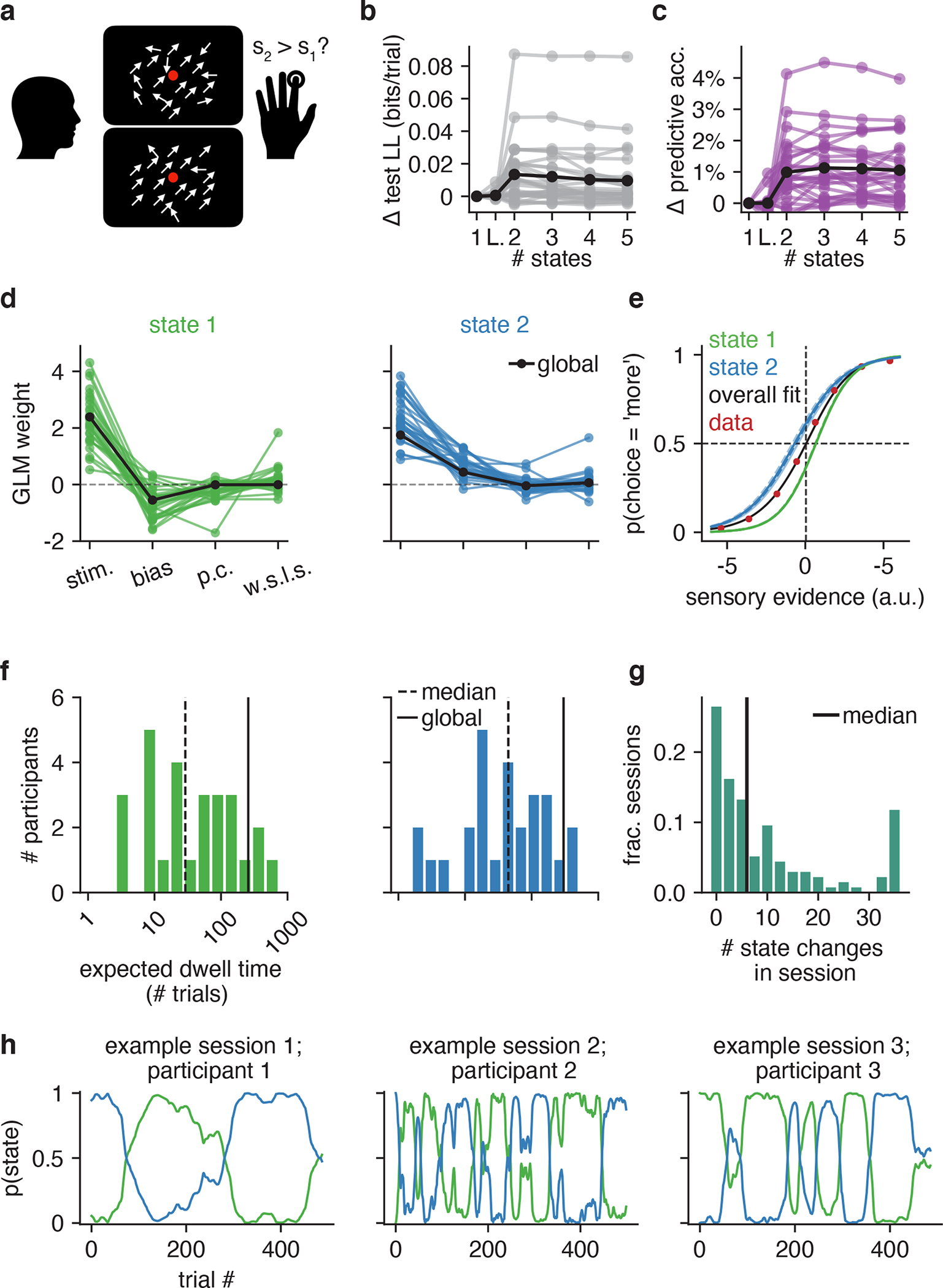
Classical models of perceptual decision-making assume that subjects use a single, consistent strategy to form decisions, or that decision-making strategies evolve slowly over time. Here we present new analyses suggesting that this common view is incorrect. We analyzed data from mouse and human decision-making experiments and found that choice behavior relies on an interplay among multiple interleaved strategies. These strategies, characterized by states in a hidden Markov model, persist for tens to hundreds of trials before switching, and often switch multiple times within a session. The identified decision-making strategies were highly consistent across mice and comprised a single 'engaged' state, in which decisions relied heavily on the sensory stimulus, and several biased states in which errors frequently occurred. These results provide a powerful alternate explanation for 'lapses' often observed in rodent behavioral experiments, and suggest that standard measures of performance mask the presence of major changes in strategy across trials.
© 2022. The Author(s), under exclusive licence to Springer Nature America, Inc.
Conflict of interest statement
Competing Interests Statement
The authors declare no competing interests.
Figures
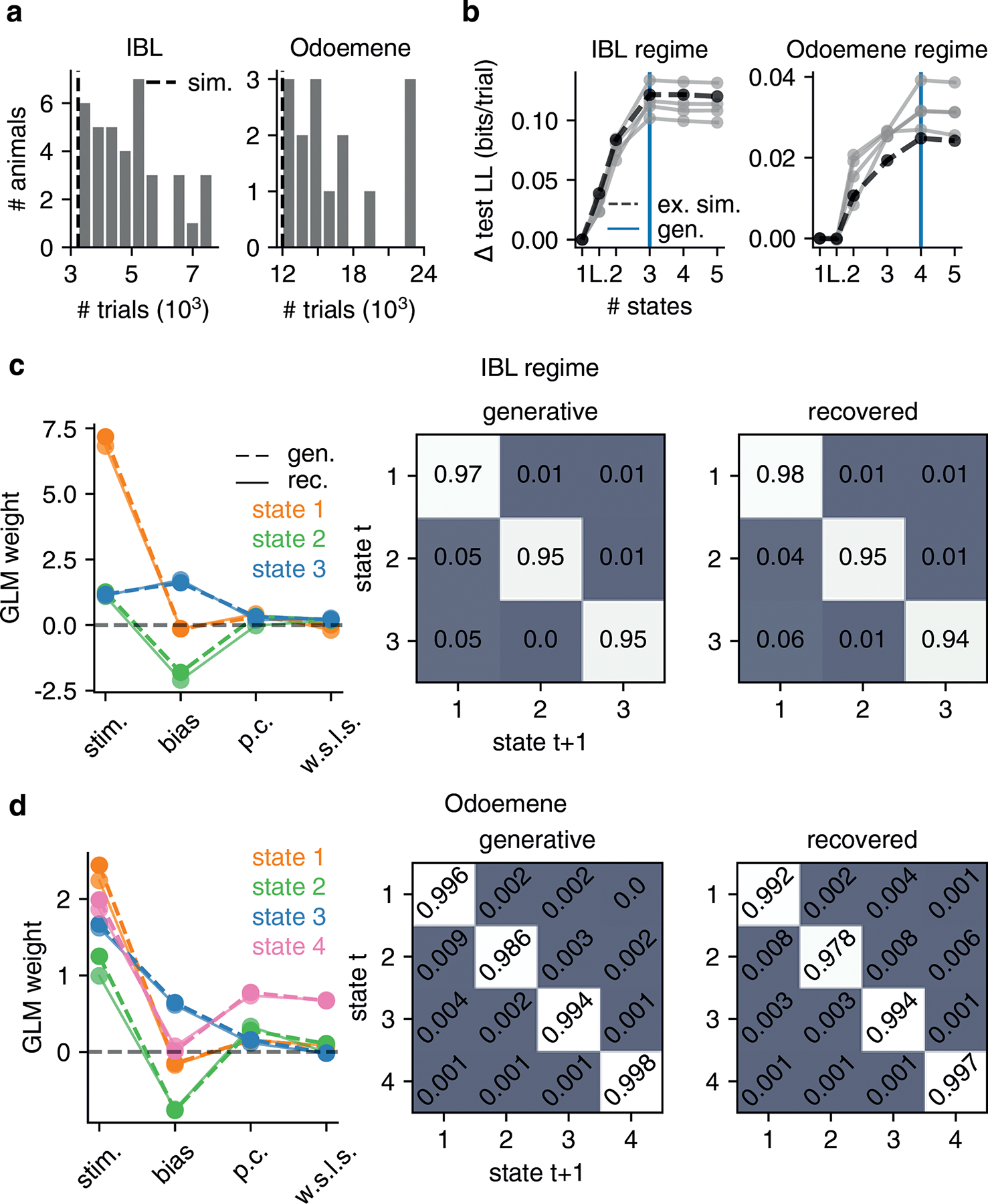
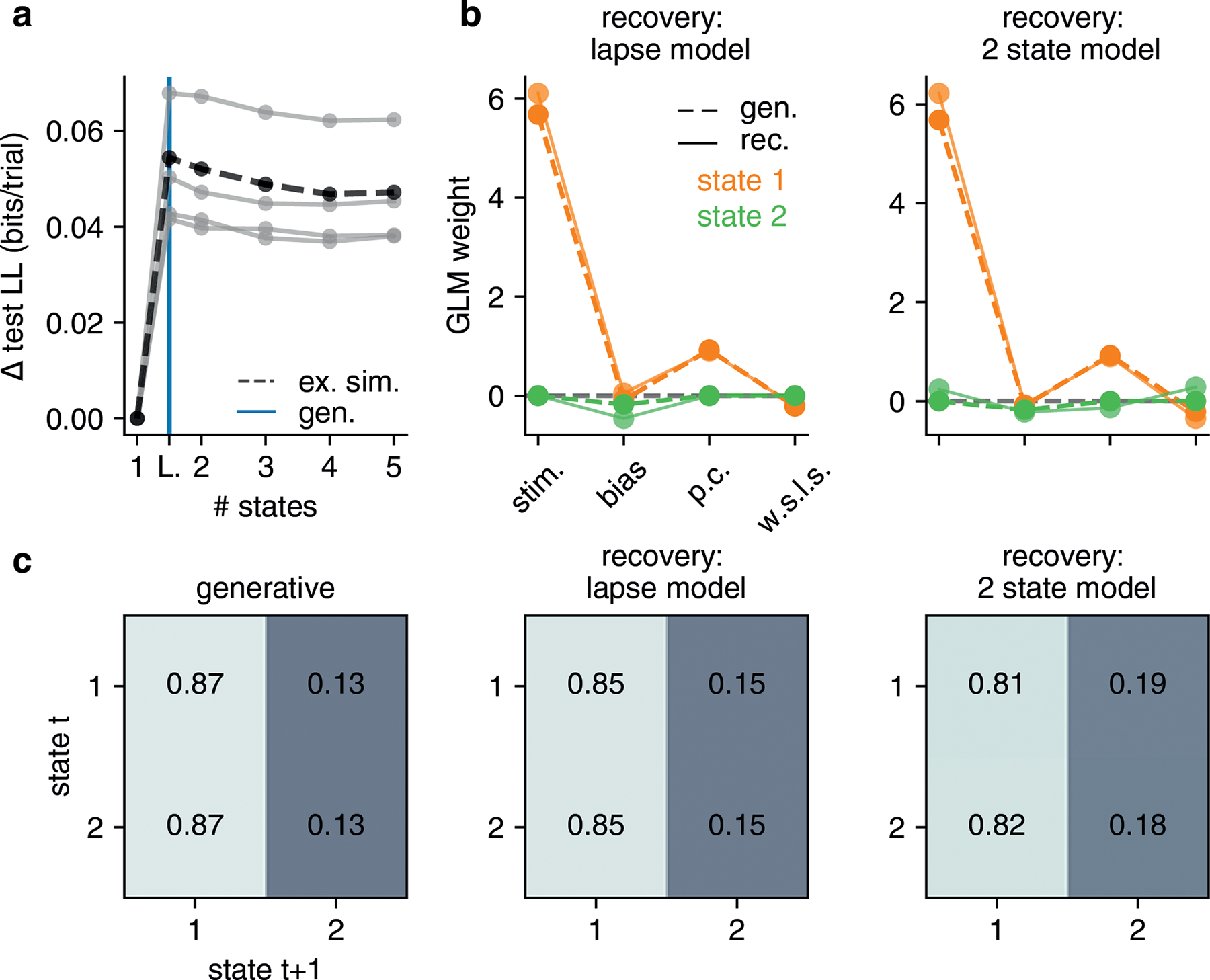
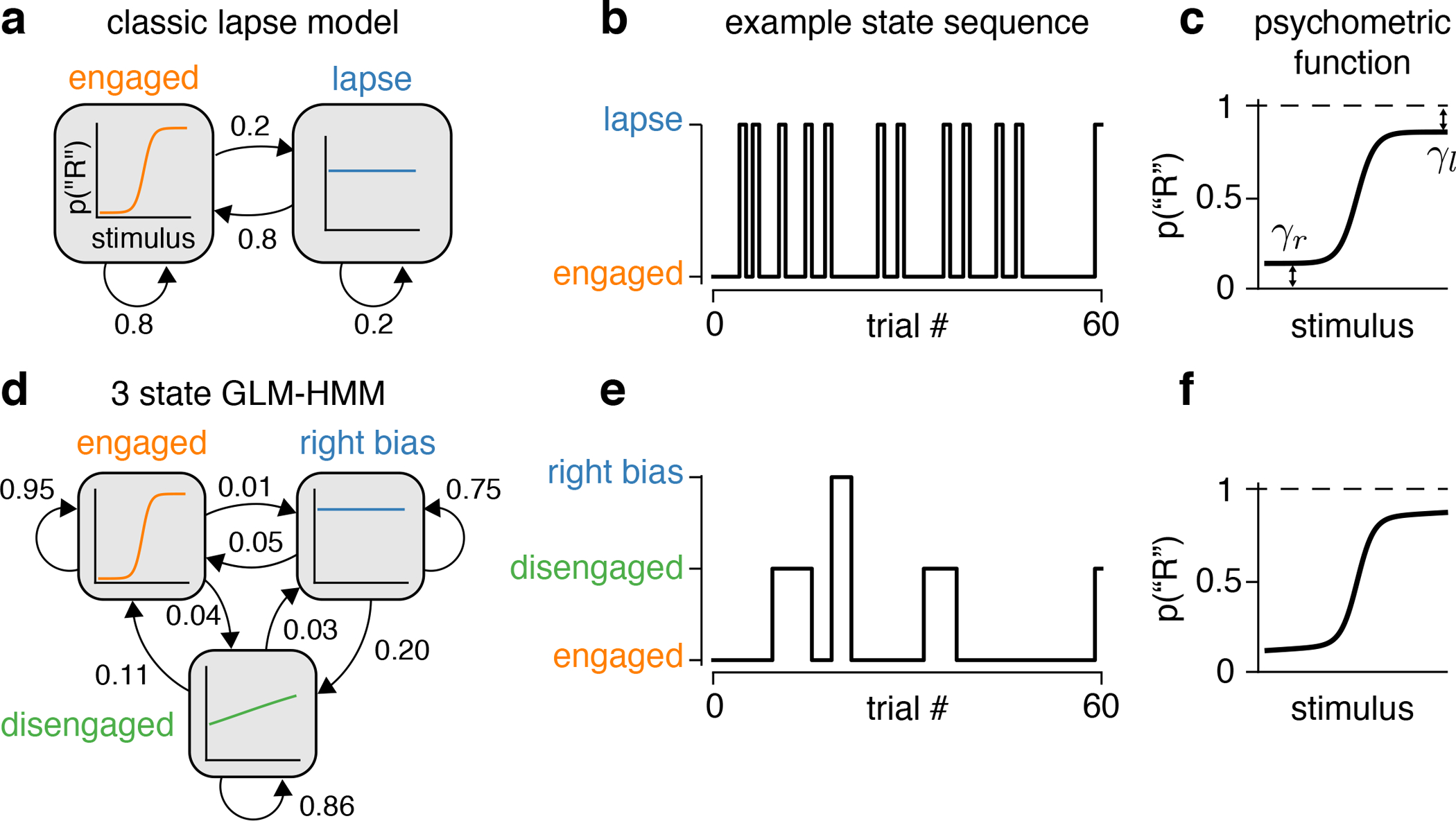
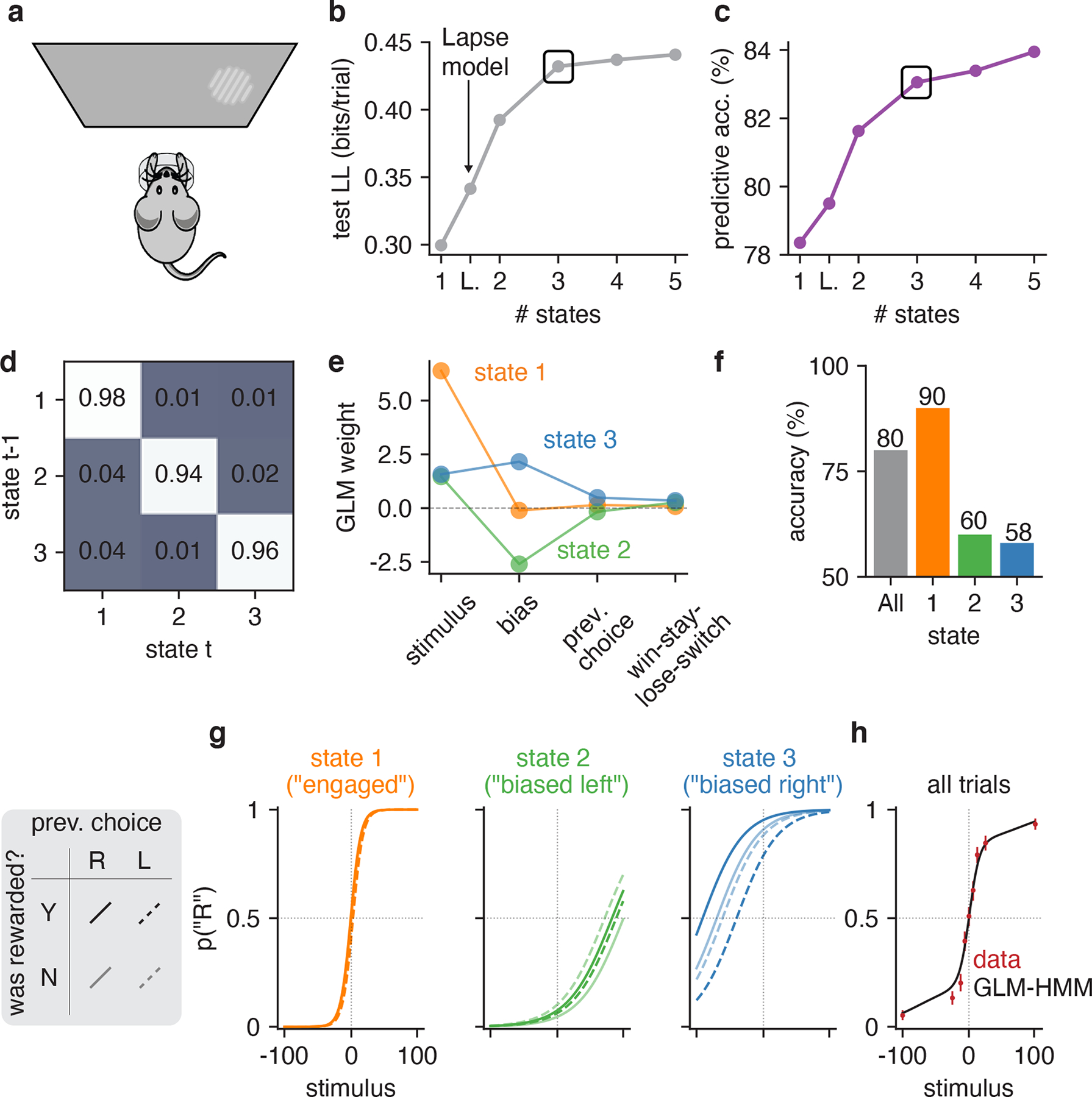
Comment in
-
From choices to internal states.Nat Neurosci. 2022 Feb;25(2):138-139. doi: 10.1038/s41593-021-01008-y. Nat Neurosci. 2022. PMID: 35132234 Free PMC article.
References
-
- Gomez-Marin A, Paton JJ, Kampff AR, Costa RM & Mainen ZF Big behavioral data: psychology, ethology and the foundations of neuroscience. en. Nature Neuroscience 17. Number:11 Publisher: Nature Publishing Group, 1455–1462. ISSN: 1546–1726. https://www.nature.com/articles/nn.3812 (2020) (Nov. 2014). - PubMed
-
- Krakauer JW, Ghazanfar AA, Gomez-Marin A, MacIver MA & Poeppel D Neuroscience Needs Behavior: Correcting a Reductionist Bias. Neuron 93, 480–490. ISSN: 0896–6273. http://www.sciencedirect.com/science/article/pii/S0896627316310406 (2019) (Feb. 2017). - PubMed
-
- Wiltschko AB et al. Mapping Sub-Second Structure in Mouse Behavior. English. Neuron 88. Publisher: Elsevier, 1121–1135. ISSN: 0896–6273. https://www.cell.com/neuron/abstract/S0896-6273(15)01037-5 (2020) (Dec. 2015). - PMC - PubMed
-
- Sharma A, Johnson R, Engert F & Linderman S in Advances in Neural Information Processing Systems 31 (eds Bengio S et al. ) 10919–10930 (Curran Associates, Inc., 2018). http://papers.nips.cc/paper/8289-point-process-latent-variable-models-of... (2020).
