

Prediction of Tuberculosis Using an Automated Machine Learning Platform for Models Trained on Synthetic Data
- PMID: 35136677
- PMCID: PMC8794034
- DOI: 10.4103/jpi.jpi_75_21
Prediction of Tuberculosis Using an Automated Machine Learning Platform for Models Trained on Synthetic Data
Abstract
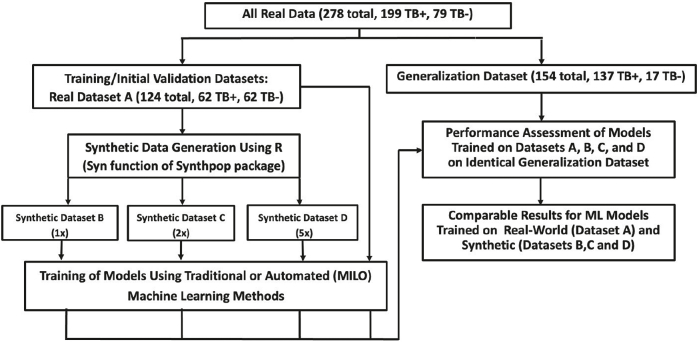
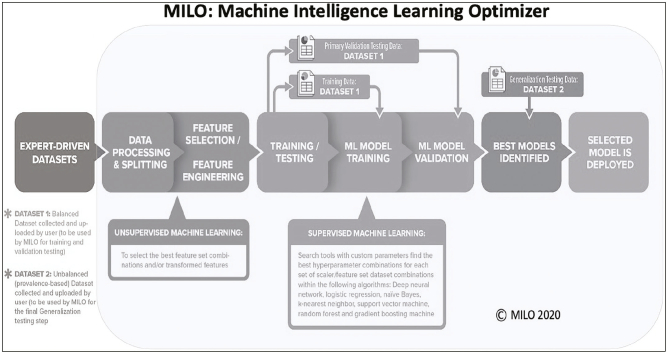
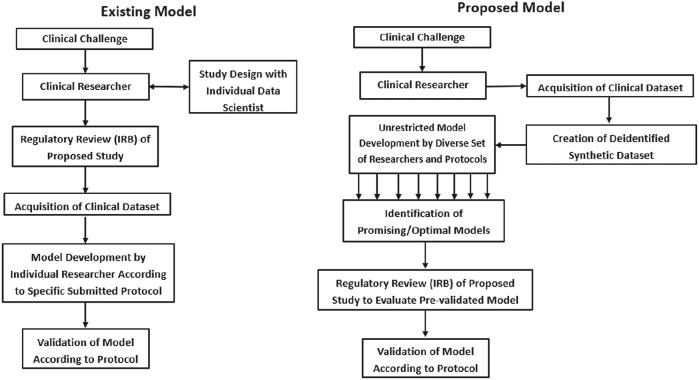
High-quality medical data is critical to the development and implementation of machine learning (ML) algorithms in healthcare; however, security, and privacy concerns continue to limit access. We sought to determine the utility of "synthetic data" in training ML algorithms for the detection of tuberculosis (TB) from inflammatory biomarker profiles. A retrospective dataset (A) comprised of 278 patients was used to generate synthetic datasets (B, C, and D) for training models prior to secondary validation on a generalization dataset. ML models trained and validated on the Dataset A (real) demonstrated an accuracy of 90%, a sensitivity of 89% (95% CI, 83-94%), and a specificity of 100% (95% CI, 81-100%). Models trained using the optimal synthetic dataset B showed an accuracy of 91%, a sensitivity of 93% (95% CI, 87-96%), and a specificity of 77% (95% CI, 50-93%). Synthetic datasets C and D displayed diminished performance measures (respective accuracies of 71% and 54%). This pilot study highlights the promise of synthetic data as an expedited means for ML algorithm development.
Keywords: Artificial intelligence; biomarkers; data accessibility; electronic medical record; privacy; simulation.
Copyright: © 2022 Journal of Pathology Informatics.
Conflict of interest statement
Dr. Rashidi is a co-inventor of MILO and owns shares in MILO-ML, LLC. Dr. Albahra is a co-inventor of the MILO software and owns shares in MILO-ML, LLC. Dr. Tran is a co-inventor of the MILO software and owns shares in MILO-ML, LLC. He is also a consultant for Roche Diagnostics and Roche Molecular Systems.
Figures
References
-
- Mayer-Schonberger V., Ingelsson E. Big data and medicine: A big deal? J Intern Med. 2017;289:418–429. - PubMed
