

Brains and algorithms partially converge in natural language processing
- PMID: 35173264
- PMCID: PMC8850612
- DOI: 10.1038/s42003-022-03036-1
Brains and algorithms partially converge in natural language processing
Erratum in
-
Author Correction: Brains and algorithms partially converge in natural language processing.Commun Biol. 2023 Apr 11;6(1):396. doi: 10.1038/s42003-023-04776-4. Commun Biol. 2023. PMID: 37041229 Free PMC article. No abstract available.
Abstract
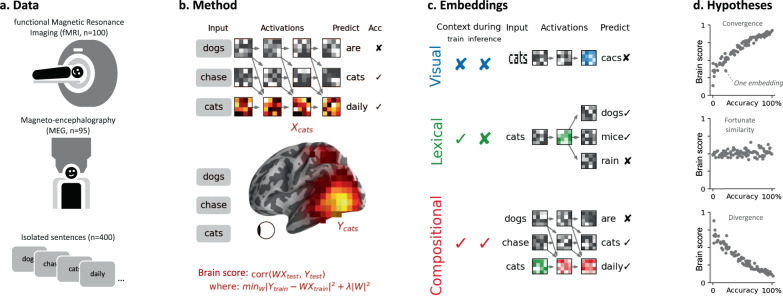
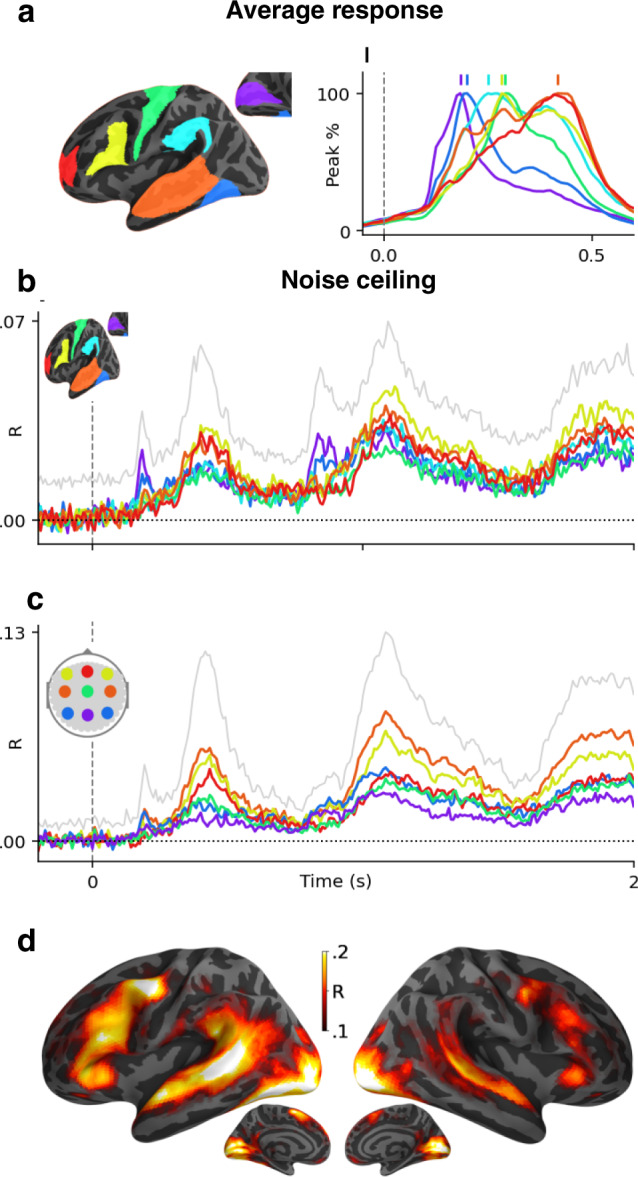
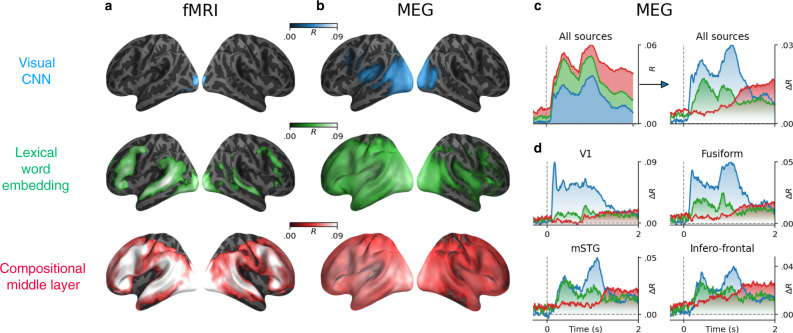
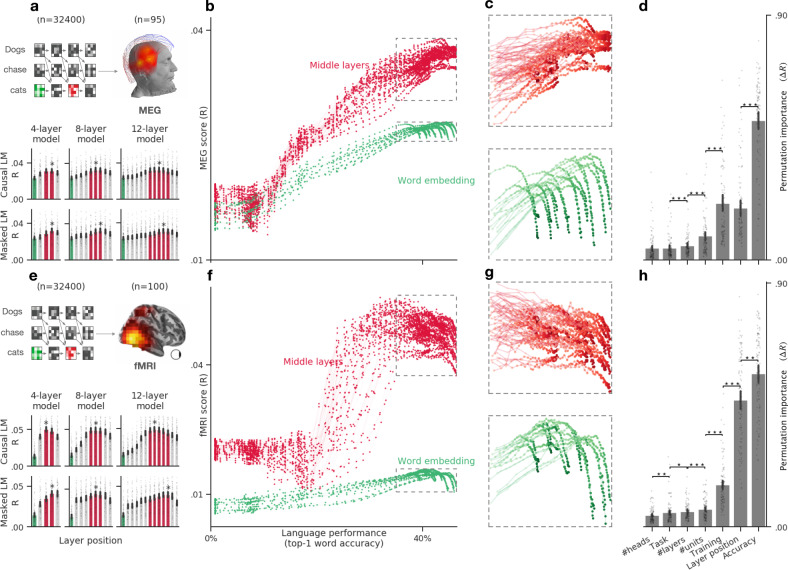
Deep learning algorithms trained to predict masked words from large amount of text have recently been shown to generate activations similar to those of the human brain. However, what drives this similarity remains currently unknown. Here, we systematically compare a variety of deep language models to identify the computational principles that lead them to generate brain-like representations of sentences. Specifically, we analyze the brain responses to 400 isolated sentences in a large cohort of 102 subjects, each recorded for two hours with functional magnetic resonance imaging (fMRI) and magnetoencephalography (MEG). We then test where and when each of these algorithms maps onto the brain responses. Finally, we estimate how the architecture, training, and performance of these models independently account for the generation of brain-like representations. Our analyses reveal two main findings. First, the similarity between the algorithms and the brain primarily depends on their ability to predict words from context. Second, this similarity reveals the rise and maintenance of perceptual, lexical, and compositional representations within each cortical region. Overall, this study shows that modern language algorithms partially converge towards brain-like solutions, and thus delineates a promising path to unravel the foundations of natural language processing.
© 2022. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
References
-
- Turing, A. M. Parsing the Turing Test 23–65 (Springer, 2009).
-
- Chomsky, N. Language and Mind (Cambridge University Press, 2006).
-
- Dehaene, S., Yann, L. & Girardon, J. La plus belle histoire de l’intelligence: des origines aux neurones artificiels: vers une nouvelle étape de l’évolution (Robert Laffont, 2018).
-
- Vaswani, A. et al. Attention is all you need. In Proceedings on NIPS (Cornell University, 2017).
-
- Devlin, J., Chang, M., Lee, K. & Toutanova, K. BERT: pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) (2019).
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
