

Magnetic control of tokamak plasmas through deep reinforcement learning
- PMID: 35173339
- PMCID: PMC8850200
- DOI: 10.1038/s41586-021-04301-9
Magnetic control of tokamak plasmas through deep reinforcement learning
Abstract
Nuclear fusion using magnetic confinement, in particular in the tokamak configuration, is a promising path towards sustainable energy. A core challenge is to shape and maintain a high-temperature plasma within the tokamak vessel. This requires high-dimensional, high-frequency, closed-loop control using magnetic actuator coils, further complicated by the diverse requirements across a wide range of plasma configurations. In this work, we introduce a previously undescribed architecture for tokamak magnetic controller design that autonomously learns to command the full set of control coils. This architecture meets control objectives specified at a high level, at the same time satisfying physical and operational constraints. This approach has unprecedented flexibility and generality in problem specification and yields a notable reduction in design effort to produce new plasma configurations. We successfully produce and control a diverse set of plasma configurations on the Tokamak à Configuration Variable1,2, including elongated, conventional shapes, as well as advanced configurations, such as negative triangularity and 'snowflake' configurations. Our approach achieves accurate tracking of the location, current and shape for these configurations. We also demonstrate sustained 'droplets' on TCV, in which two separate plasmas are maintained simultaneously within the vessel. This represents a notable advance for tokamak feedback control, showing the potential of reinforcement learning to accelerate research in the fusion domain, and is one of the most challenging real-world systems to which reinforcement learning has been applied.
© 2022. The Author(s).
Conflict of interest statement
B.T., F.C., F.F., J.B., J.D., M.N., R.H. and T.E. have filed a provisional patent application about the contents of this manuscript. The remaining authors declare no competing interests.
Figures
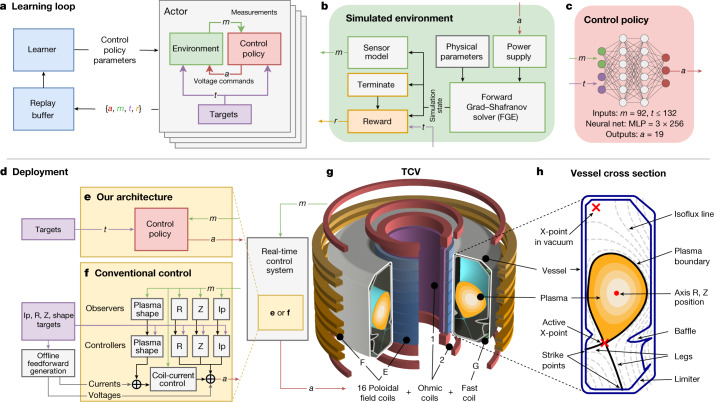
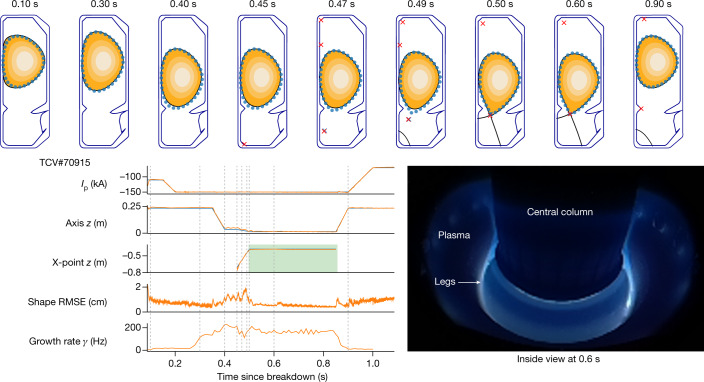
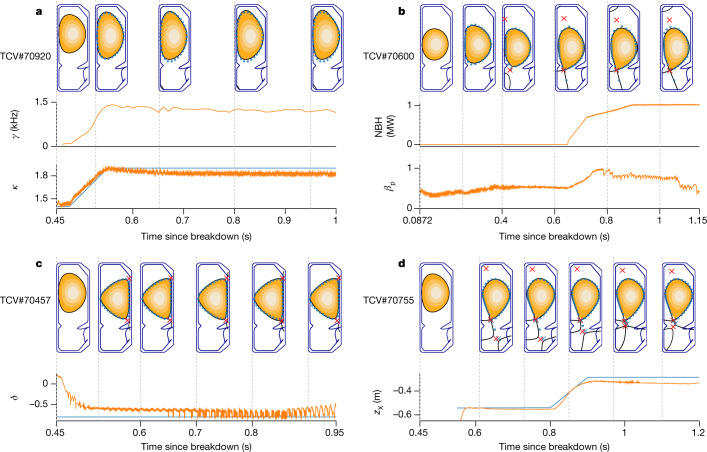
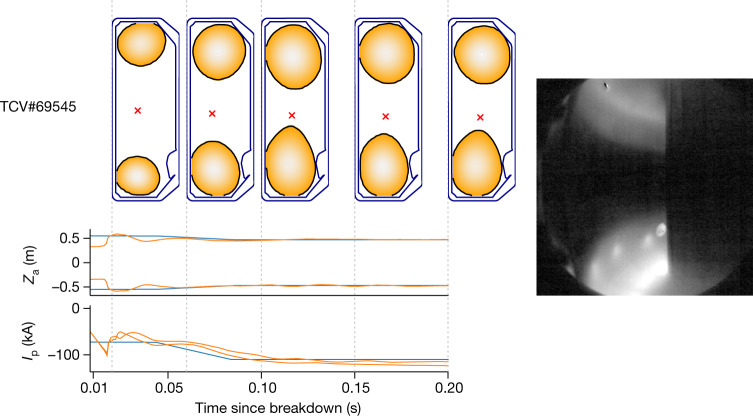

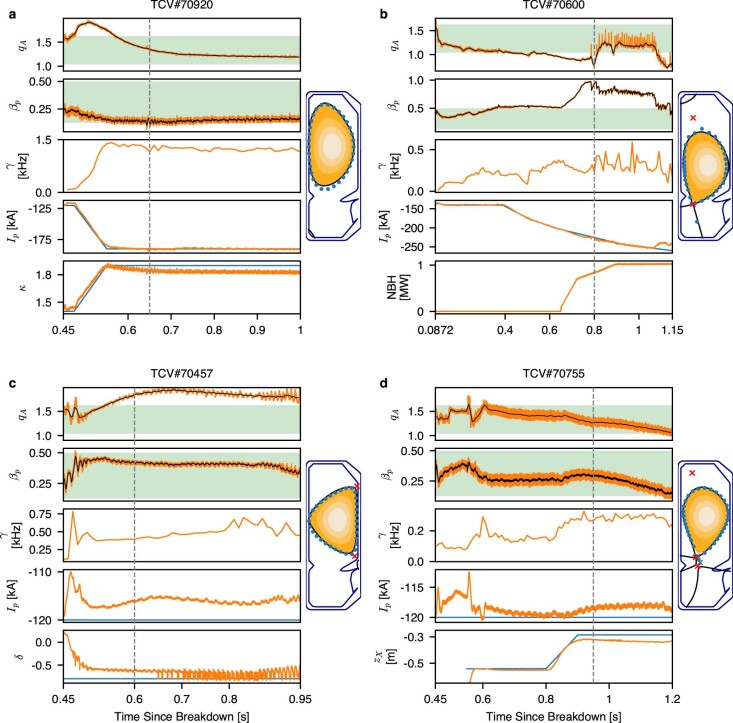
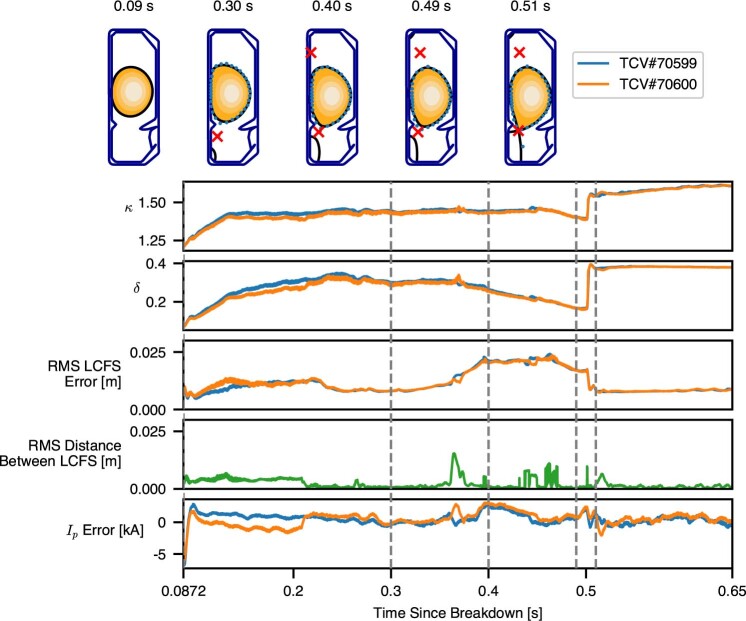
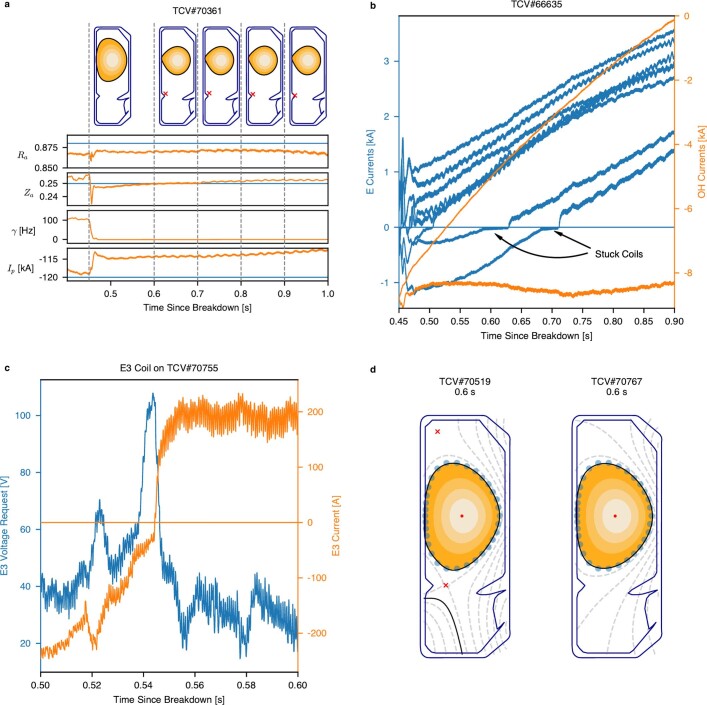
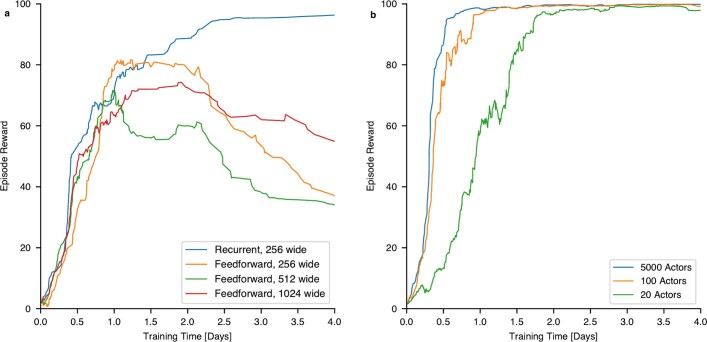
References
-
- Hofmann F, et al. Creation and control of variably shaped plasmas in TCV. Plasma Phys. Control. Fusion. 1994;36:B277. doi: 10.1088/0741-3335/36/12B/023. - DOI
-
- Coda S, et al. Physics research on the TCV tokamak facility: from conventional to alternative scenarios and beyond. Nucl. Fusion. 2019;59:112023. doi: 10.1088/1741-4326/ab25cb. - DOI
-
- Anand H, Coda S, Felici F, Galperti C, Moret J-M. A novel plasma position and shape controller for advanced configuration development on the TCV tokamak. Nucl. Fusion. 2017;57:126026. doi: 10.1088/1741-4326/aa7f4d. - DOI
-
- Mele A, et al. MIMO shape control at the EAST tokamak: simulations and experiments. Fusion Eng. Des. 2019;146:1282–1285. doi: 10.1016/j.fusengdes.2019.02.058. - DOI
-
- Anand H, et al. Plasma flux expansion control on the DIII-D tokamak. Plasma Phys. Control. Fusion. 2020;63:015006. doi: 10.1088/1361-6587/abc457. - DOI
Publication types
LinkOut - more resources
Full Text Sources
Other Literature Sources
