

Systematic illumination of druggable genes in cancer genomes
- PMID: 35196490
- PMCID: PMC8919705
- DOI: 10.1016/j.celrep.2022.110400
Systematic illumination of druggable genes in cancer genomes
Abstract
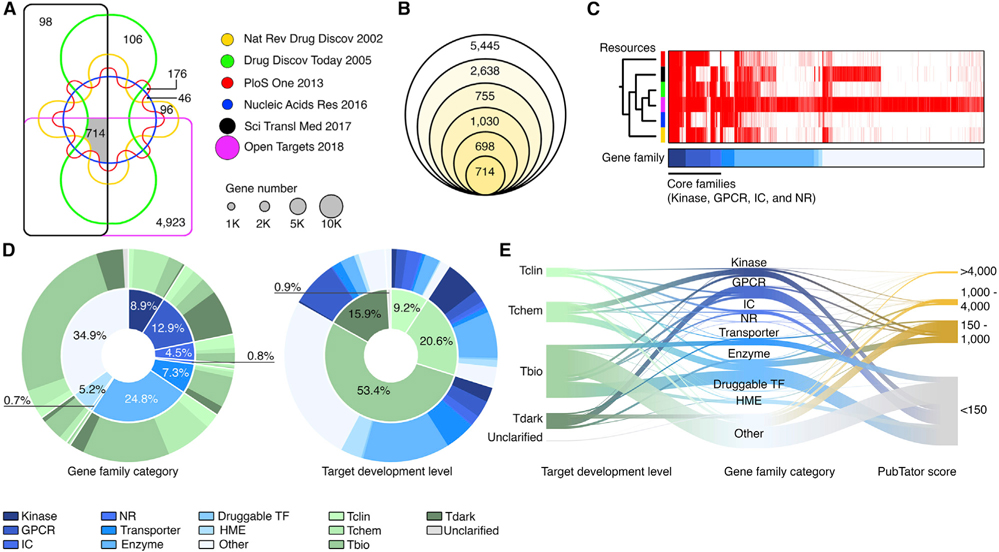
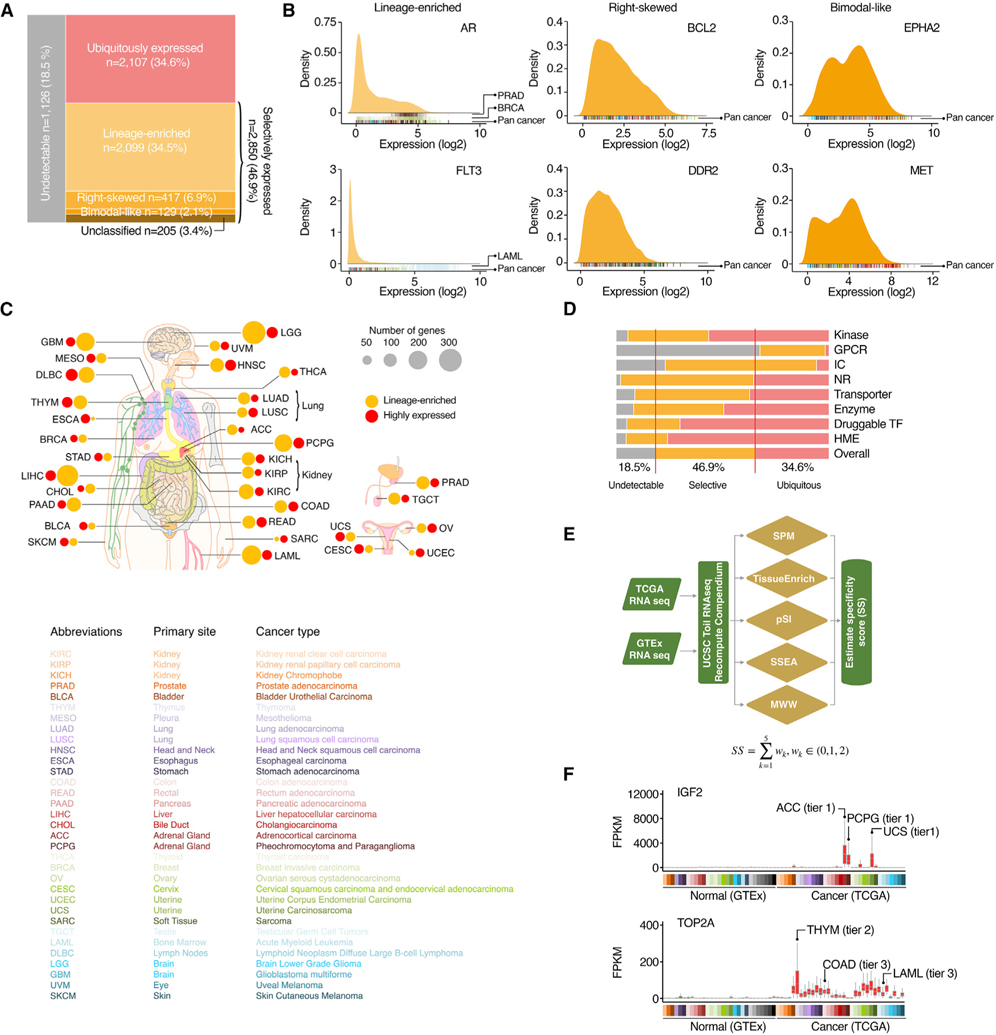
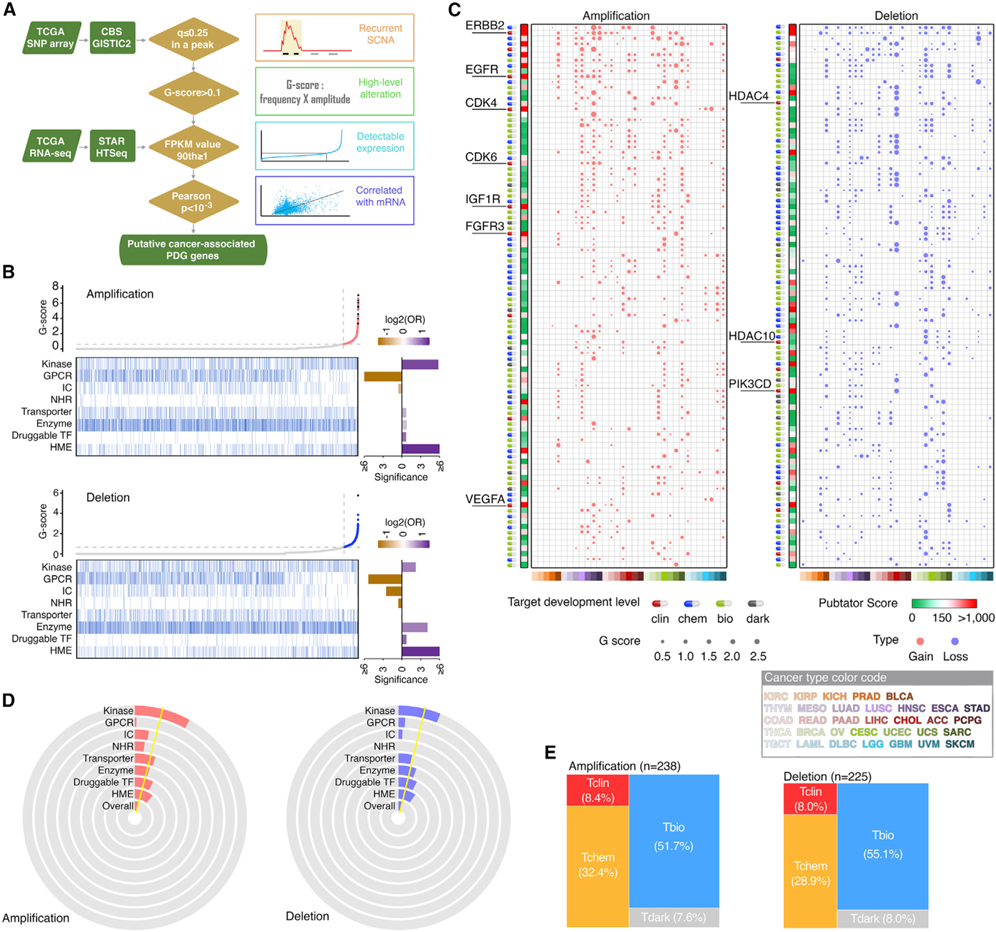
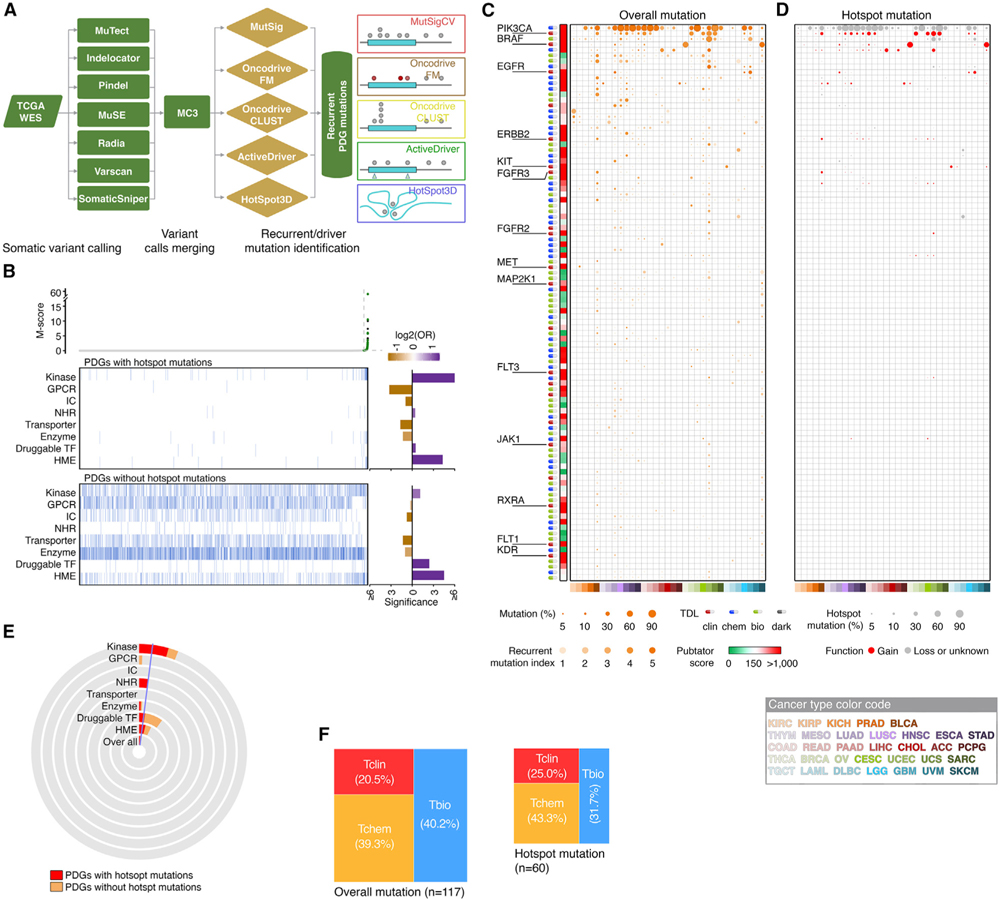
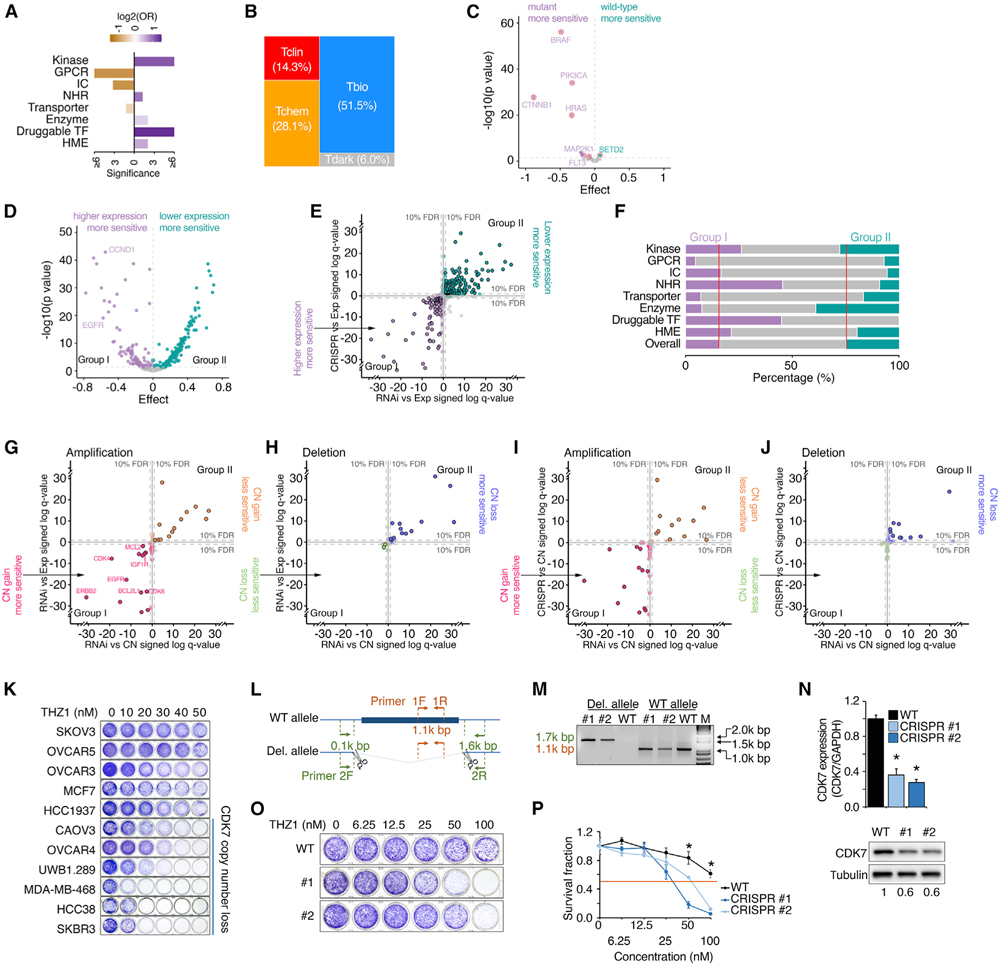
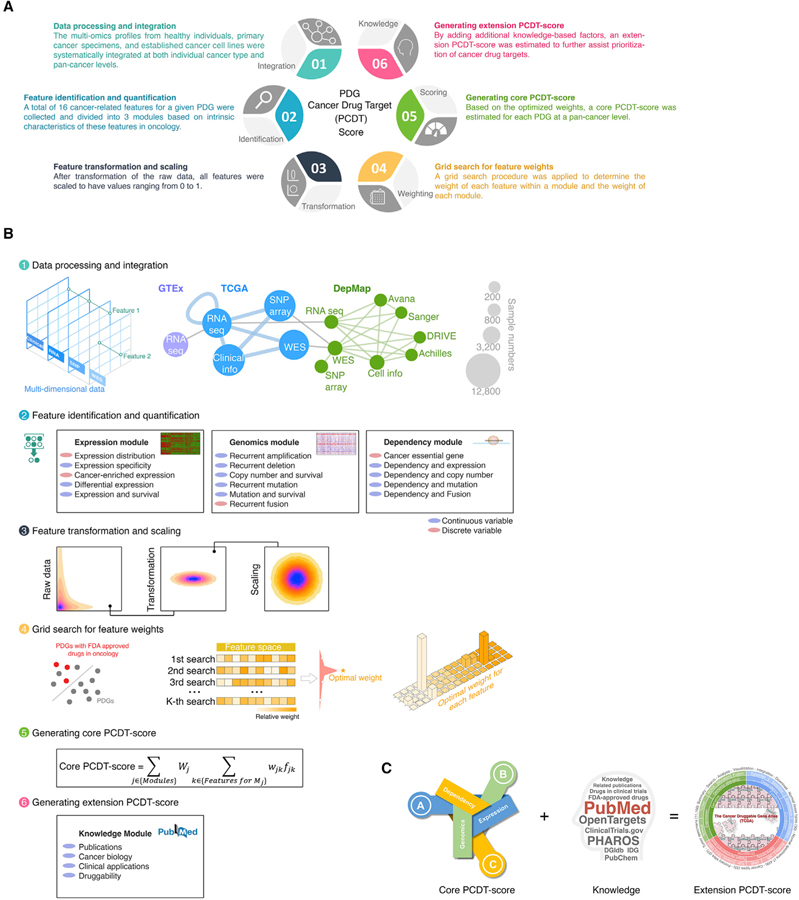
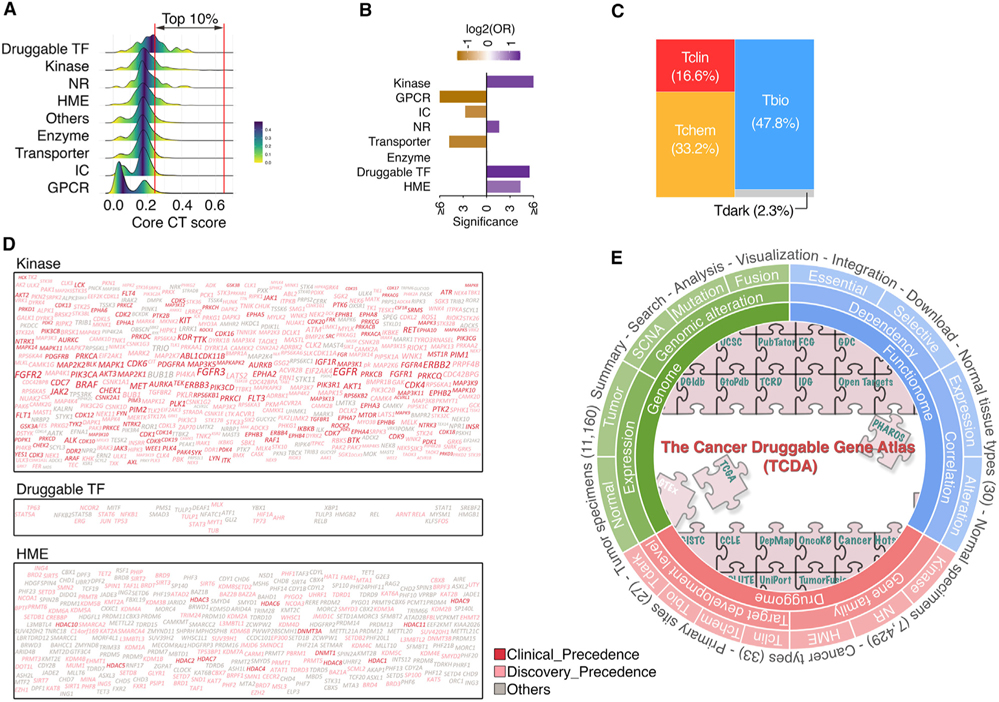
By combining 6 druggable genome resources, we identify 6,083 genes as potential druggable genes (PDGs). We characterize their expression, recurrent genomic alterations, cancer dependencies, and therapeutic potentials by integrating genome, functionome, and druggome profiles across cancers. 81.5% of PDGs are reliably expressed in major adult cancers, 46.9% show selective expression patterns, and 39.1% exhibit at least one recurrent genomic alteration. We annotate a total of 784 PDGs as dependent genes for cancer cell growth. We further quantify 16 cancer-related features and estimate a PDG cancer drug target score (PCDT score). PDGs with higher PCDT scores are significantly enriched for genes encoding kinases and histone modification enzymes. Importantly, we find that a considerable portion of high PCDT score PDGs are understudied genes, providing unexplored opportunities for drug development in oncology. By integrating the druggable genome and the cancer genome, our study thus generates a comprehensive blueprint of potential druggable genes across cancers.
Keywords: CDK7; cancer; cancer dependency; cancer genome; cancer treatment; copy number alterations; druggable; druggable gene; small molecule drug; therapeutics.
Copyright © 2022 The Author(s). Published by Elsevier Inc. All rights reserved.
Conflict of interest statement
Declaration of interests L.Z. and X.H. report having received research funding from AstraZeneca, Bristol-Myers Squibb/Celgene, and Prelude Therapeutics. O.T. and H.M.C. are employees of AstraZeneca. R.H.V. is an inventor on a licensed patent relating to cancer cellular immunotherapy and receives royalties from Children's Hospital Boston for a licensed research-only monoclonal antibody.
Figures
References
-
- Benjamini Y, and Hochberg Y (1995). Controlling the false discovery rate: a practical and powerful approach to multiple testing. J. R. Stat. Soc. Ser. B (Methodological) 57, 289–300.
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
