

Effects of training and using an audio-tactile sensory substitution device on speech-in-noise understanding
- PMID: 35217676
- PMCID: PMC8881456
- DOI: 10.1038/s41598-022-06855-8
Effects of training and using an audio-tactile sensory substitution device on speech-in-noise understanding
Abstract
Understanding speech in background noise is challenging. Wearing face-masks, imposed by the COVID19-pandemics, makes it even harder. We developed a multi-sensory setup, including a sensory substitution device (SSD) that can deliver speech simultaneously through audition and as vibrations on the fingertips. The vibrations correspond to low frequencies extracted from the speech input. We trained two groups of non-native English speakers in understanding distorted speech in noise. After a short session (30-45 min) of repeating sentences, with or without concurrent matching vibrations, we showed comparable mean group improvement of 14-16 dB in Speech Reception Threshold (SRT) in two test conditions, i.e., when the participants were asked to repeat sentences only from hearing and also when matching vibrations on fingertips were present. This is a very strong effect, if one considers that a 10 dB difference corresponds to doubling of the perceived loudness. The number of sentence repetitions needed for both types of training to complete the task was comparable. Meanwhile, the mean group SNR for the audio-tactile training (14.7 ± 8.7) was significantly lower (harder) than for the auditory training (23.9 ± 11.8), which indicates a potential facilitating effect of the added vibrations. In addition, both before and after training most of the participants (70-80%) showed better performance (by mean 4-6 dB) in speech-in-noise understanding when the audio sentences were accompanied with matching vibrations. This is the same magnitude of multisensory benefit that we reported, with no training at all, in our previous study using the same experimental procedures. After training, performance in this test condition was also best in both groups (SRT ~ 2 dB). The least significant effect of both training types was found in the third test condition, i.e. when participants were repeating sentences accompanied with non-matching tactile vibrations and the performance in this condition was also poorest after training. The results indicate that both types of training may remove some level of difficulty in sound perception, which might enable a more proper use of speech inputs delivered via vibrotactile stimulation. We discuss the implications of these novel findings with respect to basic science. In particular, we show that even in adulthood, i.e. long after the classical "critical periods" of development have passed, a new pairing between a certain computation (here, speech processing) and an atypical sensory modality (here, touch) can be established and trained, and that this process can be rapid and intuitive. We further present possible applications of our training program and the SSD for auditory rehabilitation in patients with hearing (and sight) deficits, as well as healthy individuals in suboptimal acoustic situations.
© 2022. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
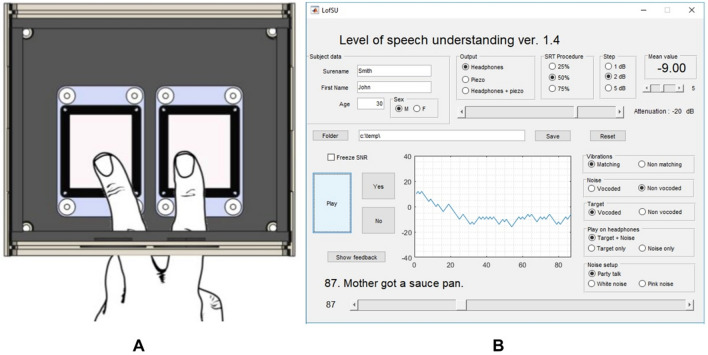
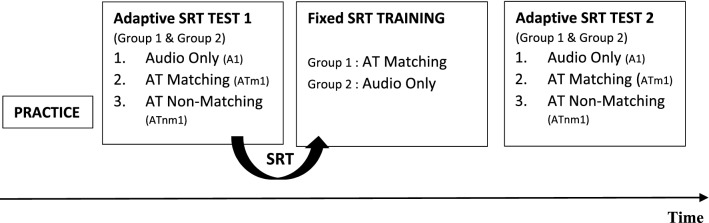



References
-
- Bayard C, et al. Cued speech enhances speech-in-noise perception. J Deaf. Stud. Deaf. 2019;24:223–233. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Miscellaneous
