

Sociotechnical safeguards for genomic data privacy
- PMID: 35246669
- PMCID: PMC8896074
- DOI: 10.1038/s41576-022-00455-y
Sociotechnical safeguards for genomic data privacy
Erratum in
-
Publisher Correction: Sociotechnical safeguards for genomic data privacy.Nat Rev Genet. 2022 Jul;23(7):453. doi: 10.1038/s41576-022-00479-4. Nat Rev Genet. 2022. PMID: 35332247 Free PMC article. No abstract available.
Abstract
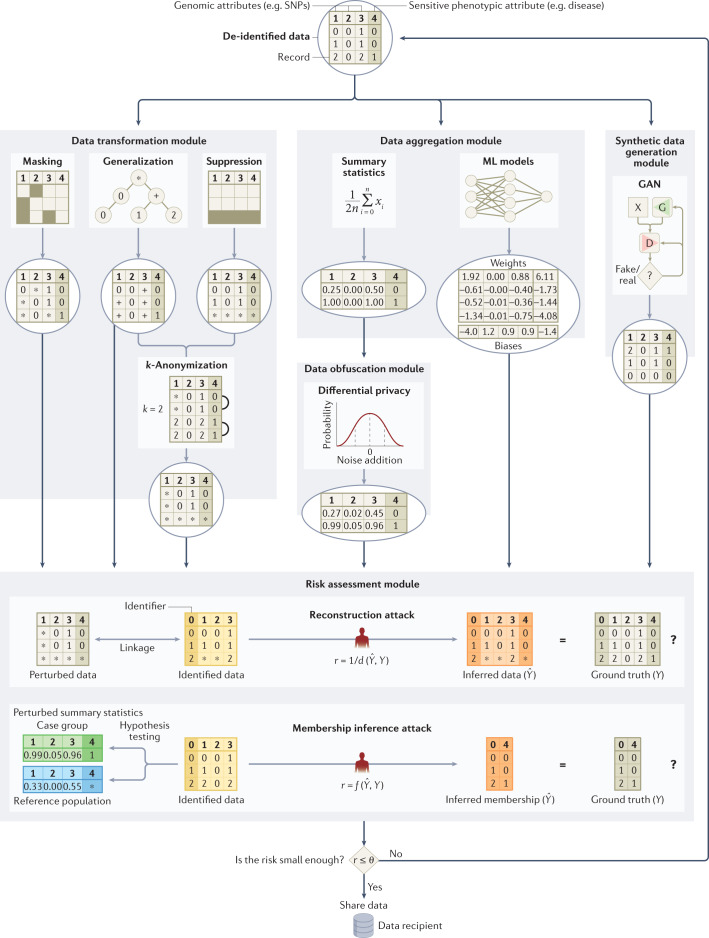
Recent developments in a variety of sectors, including health care, research and the direct-to-consumer industry, have led to a dramatic increase in the amount of genomic data that are collected, used and shared. This state of affairs raises new and challenging concerns for personal privacy, both legally and technically. This Review appraises existing and emerging threats to genomic data privacy and discusses how well current legal frameworks and technical safeguards mitigate these concerns. It concludes with a discussion of remaining and emerging challenges and illustrates possible solutions that can balance protecting privacy and realizing the benefits that result from the sharing of genetic information.
© 2022. Springer Nature Limited.
Conflict of interest statement
The authors declare no competing interests.
Figures


References
-
- Doe, G. With genetic testing, I gave my parents the gift of divorce. Voxhttps://www.vox.com/2014/9/9/5975653/with-genetic-testing-i-gave-my-pare... (2014).
-
- Copeland, L. The Lost Family: How DNA Testing is Upending Who We Are (Abrams, 2020).
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
