

Deep Ensemble Machine Learning Framework for the Estimation of Concentrations
- PMID: 35254864
- PMCID: PMC8901043
- DOI: 10.1289/EHP9752
Deep Ensemble Machine Learning Framework for the Estimation of Concentrations
Abstract
Background: Accurate estimation of historical (particle matter with an aerodynamic diameter of less than ) is critical and essential for environmental health risk assessment.
Objectives: The aim of this study was to develop a multiple-level stacked ensemble machine learning framework for improving the estimation of the daily ground-level concentrations.
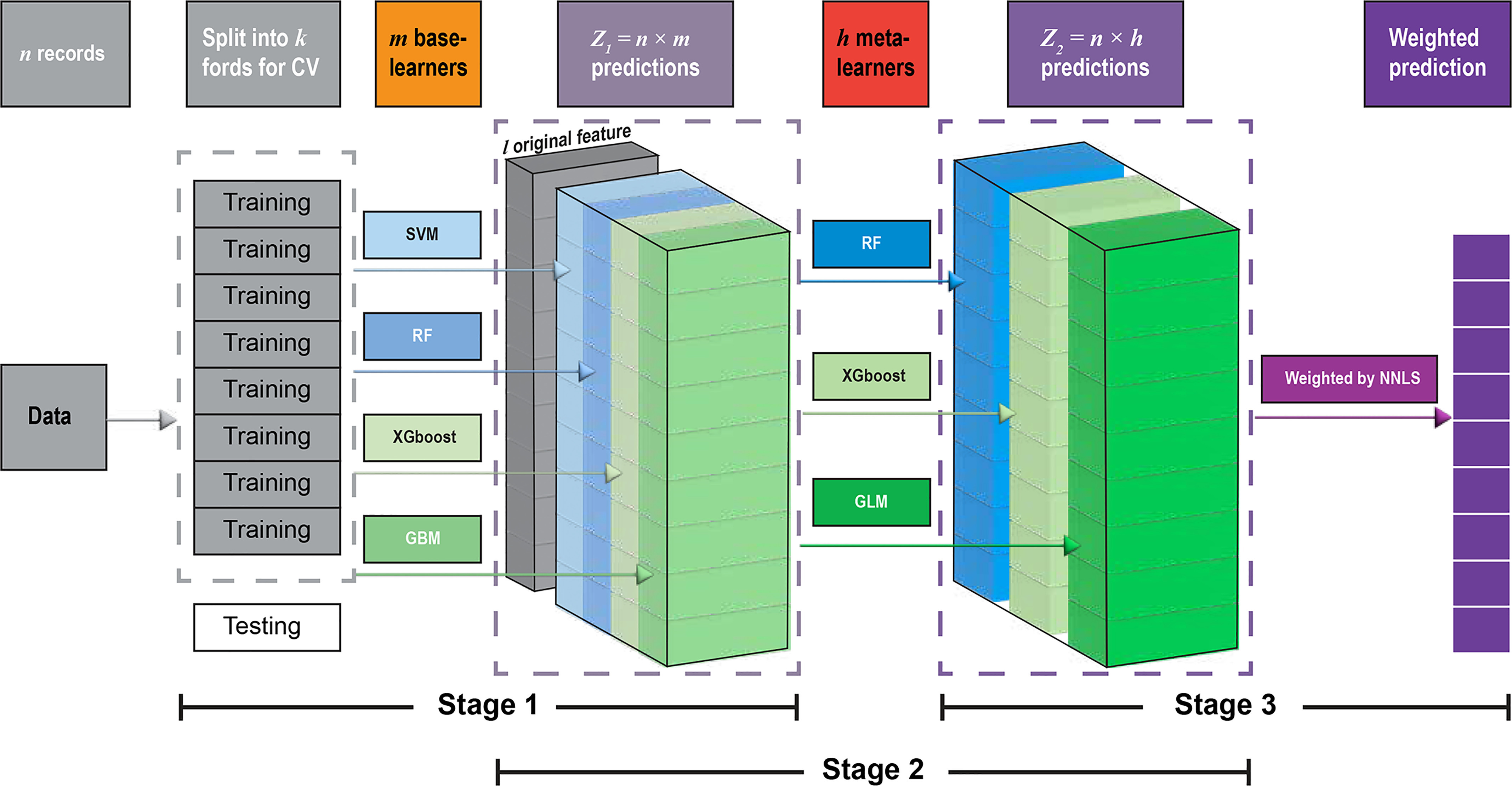
Methods: An innovative deep ensemble machine learning framework (DEML) was developed to estimate the daily concentrations. The framework has a three-stage structure: At the first stage, four base models [gradient boosting machine (GBM), support vector machine (SVM), random forest (RF), and eXtreme gradient boosting (XGBoost)] were used to generate a new data set of concentrations for training the next-stage learners. At the second stage, three meta-models [RF, XGBoost, and Generalized Linear Model (GLM)] were used to estimate concentrations using a combination of the original data set and the predictions from the first-stage models. At the third stage, a nonnegative least squares (NNLS) algorithm was employed to obtain the optimal weights for estimation. We took the data from 133 monitoring stations in Italy as an example to implement the DEML to predict daily at each grid cell from 2015 to 2019 across Italy. We evaluated the model performance by performing 10-fold cross-validation (CV) and compared it with five benchmark algorithms [GBM, SVM, RF, XGBoost, and Super Learner (SL)].
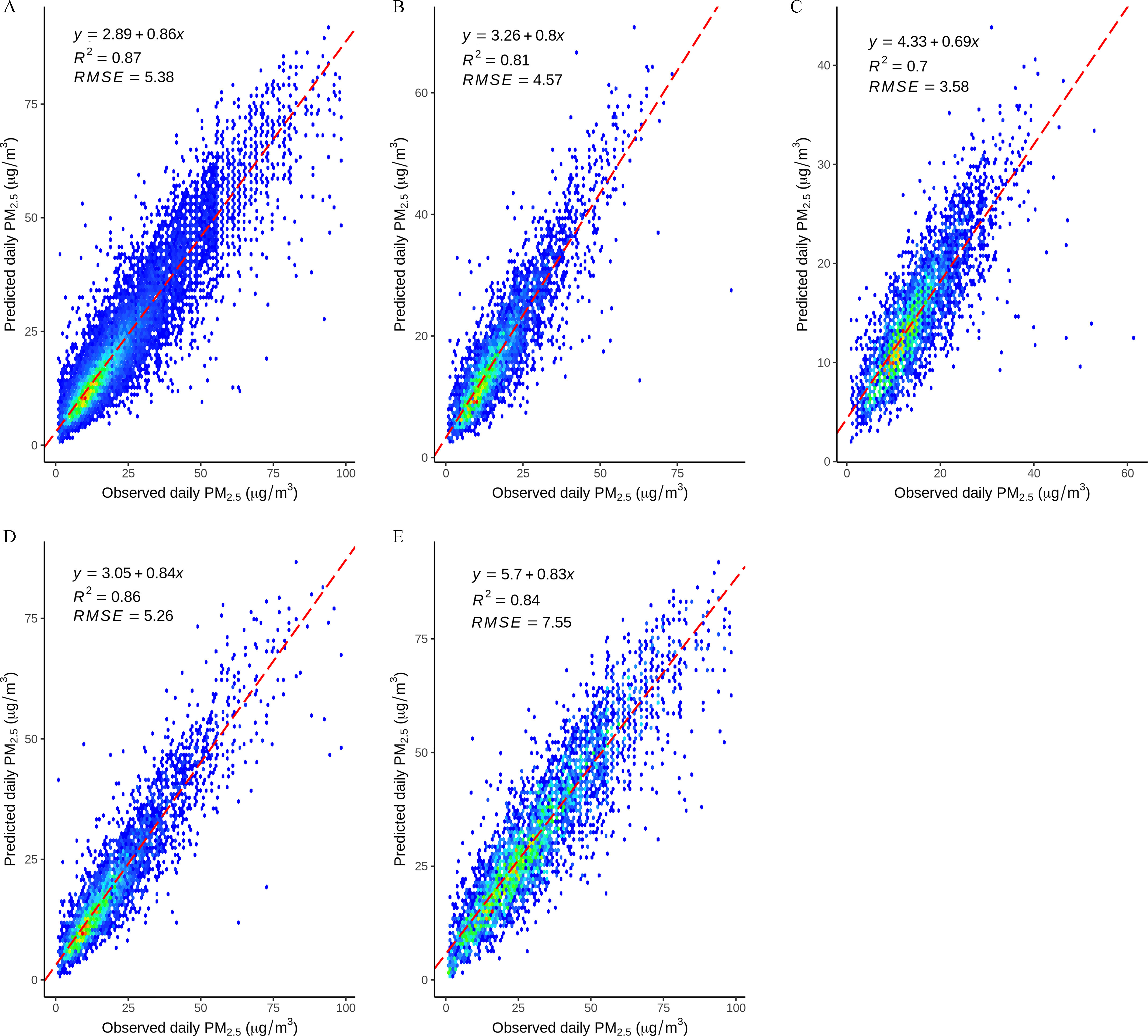
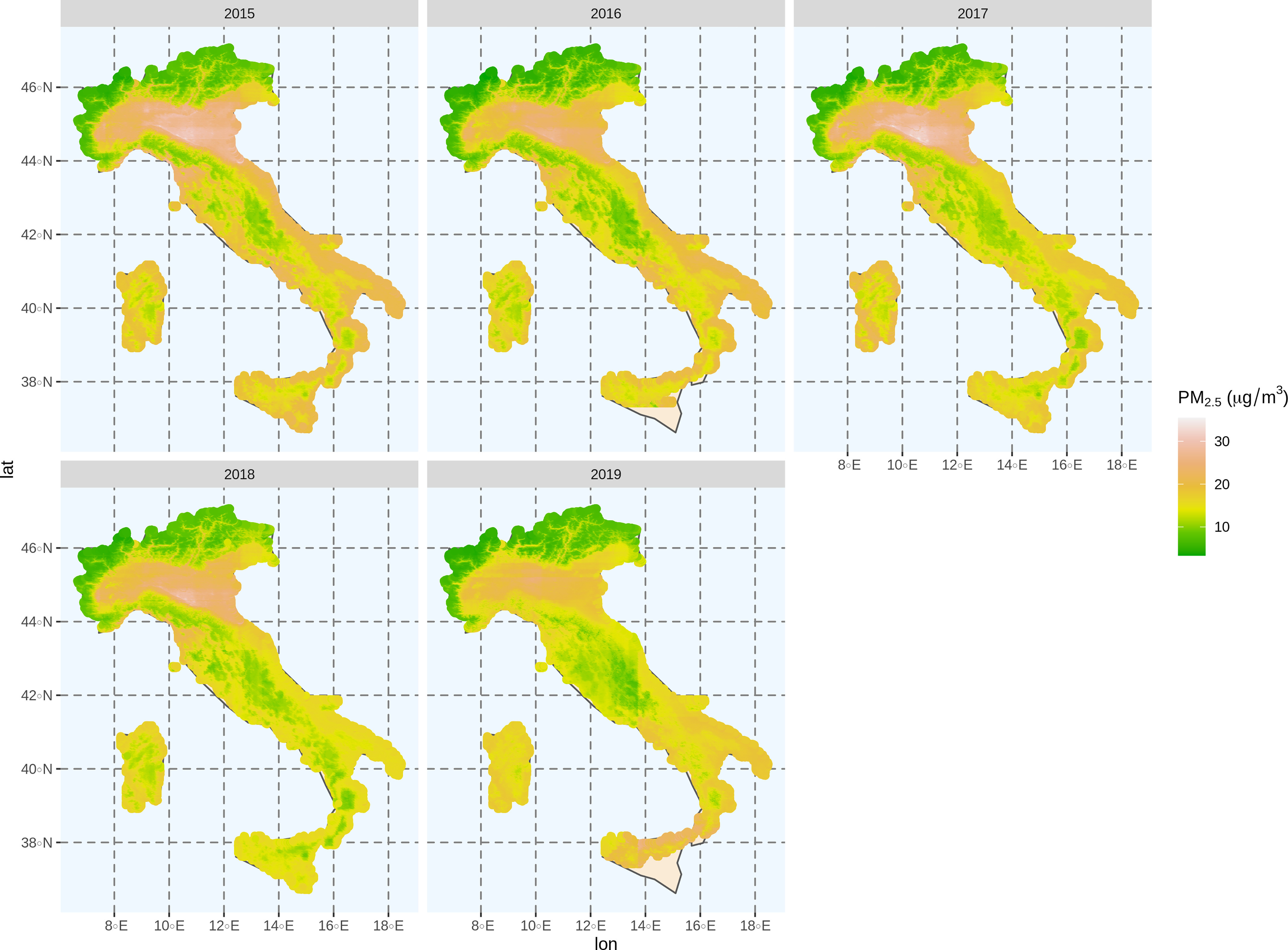
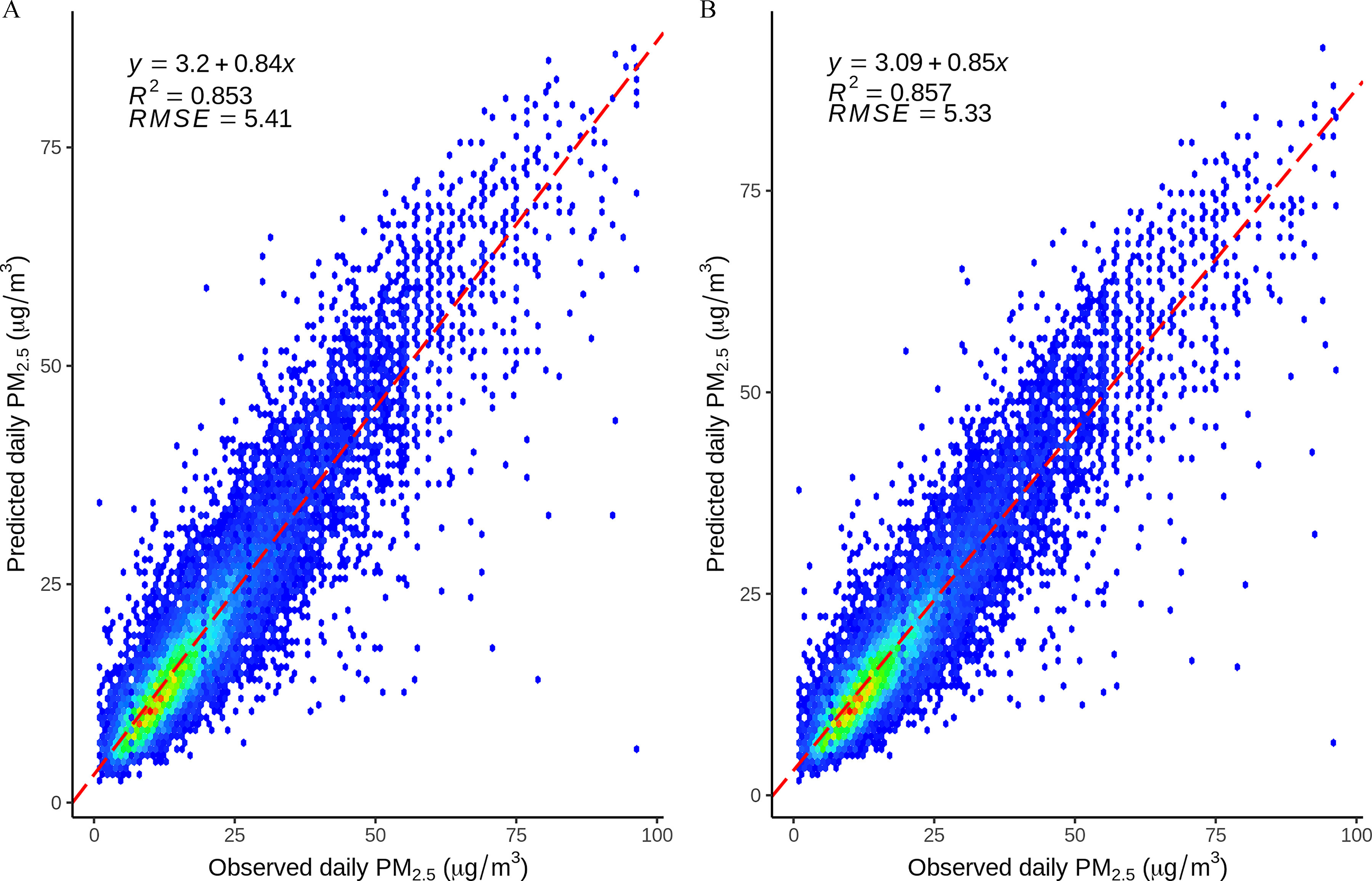
Results: The results revealed that the prediction performance of DEML [coefficients of determination and root mean square error ] was superior to any benchmark models (with of 0.51, 0.76, 0.83, 0.70, and 0.83 for GBM, SVM, RF, XGBoost, and SL approach, respectively). DEML displayed reliable performance in capturing the spatiotemporal variations of in Italy.
Discussion: The proposed DEML framework achieved an outstanding performance in estimation, which could be used as a tool for more accurate environmental exposure assessment. https://doi.org/10.1289/EHP9752.
Figures
Comment in
-
Comment on "Deep Ensemble Machine Learning Framework for the Estimation of Concentrations".Environ Health Perspect. 2022 Jun;130(6):68001. doi: 10.1289/EHP11385. Epub 2022 Jun 2. Environ Health Perspect. 2022. PMID: 35652826 Free PMC article. No abstract available.
-
Comment on "Evaluation of a Gene-Environment Interaction of PON1 and Low-Level Nerve Agent Exposure with Gulf War Illness: A Prevalence Case-Control Study Drawn from the U.S. Military Health Survey's National Population Sample".Environ Health Perspect. 2022 Jun;130(6):68003. doi: 10.1289/EHP11558. Epub 2022 Jun 15. Environ Health Perspect. 2022. PMID: 35703987 Free PMC article. No abstract available.
-
Response to "Comment on 'Evaluation of a Gene-Environment Interaction of PON1 and Low-Level Nerve Agent Exposure with Gulf War Illness: A Prevalence Case-Control Study Drawn from the U.S. Military Health Survey's National Population Sample'".Environ Health Perspect. 2022 Jun;130(6):68004. doi: 10.1289/EHP11607. Epub 2022 Jun 15. Environ Health Perspect. 2022. PMID: 35703989 Free PMC article. No abstract available.
References
-
- Alpaydin E. 2020. Introduction to Machine Learning. Cambridge, MA: MIT Press.
-
- Alsahli MM, Al-Harbi M. 2018. Allocating optimum sites for air quality monitoring stations using GIS suitability analysis. Urban Clim 24:875–886, 10.1016/j.uclim.2017.11.001. - DOI
-
- Biecek P. 2018. DALEX: explainers for complex predictive models in R. J Mach Learn Res 19:3245–3249.
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources