

Photonic reinforcement learning based on optoelectronic reservoir computing
- PMID: 35260595
- PMCID: PMC8904492
- DOI: 10.1038/s41598-022-07404-z
Photonic reinforcement learning based on optoelectronic reservoir computing
Abstract
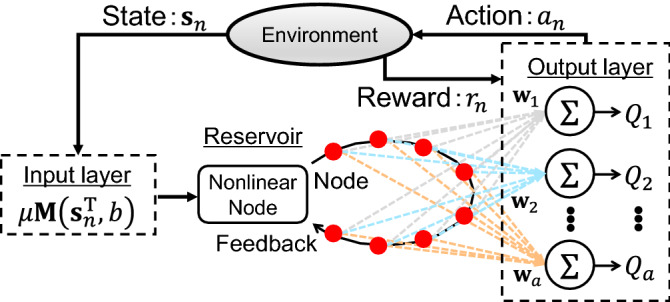
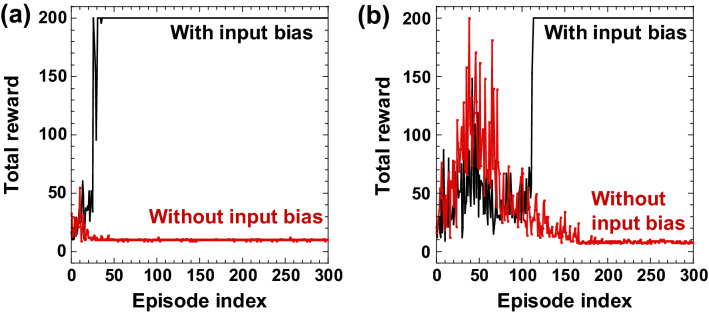
Reinforcement learning has been intensively investigated and developed in artificial intelligence in the absence of training data, such as autonomous driving vehicles, robot control, internet advertising, and elastic optical networks. However, the computational cost of reinforcement learning with deep neural networks is extremely high and reducing the learning cost is a challenging issue. We propose a photonic on-line implementation of reinforcement learning using optoelectronic delay-based reservoir computing, both experimentally and numerically. In the proposed scheme, we accelerate reinforcement learning at a rate of several megahertz because there is no required learning process for the internal connection weights in reservoir computing. We perform two benchmark tasks, CartPole-v0 and MountanCar-v0 tasks, to evaluate the proposed scheme. Our results represent the first hardware implementation of reinforcement learning based on photonic reservoir computing and pave the way for fast and efficient reinforcement learning as a novel photonic accelerator.
© 2022. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures



References
-
- Andrae A, Edler T. On global electricity usage of communication technology: trends to 2030. Challenges. 2015;6:117–157.
-
- Haghighat MH, Li J. Intrusion detection system using voting-based neural network. Tsinghua Sci. Technol. 2021;26:484–495.
-
- Zhang J, Xu Q. Attention-aware heterogeneous graph neural network. Big Data Min. Anal. 2021;4:233–241.
-
- Bie Y, Yang Y. A multitask multiview neural network for end-to-end aspect-based sentiment analysis. Big Data Min. Anal. 2021;4:195–207.
-
- Sutton RS, Barto AG. Reinforcement Learning: An Introduction. Cambridge: The MIT Press; 2018.
Grants and funding
LinkOut - more resources
Full Text Sources
